Apache Kafka является мощным инструментом для обработки и передачи потоковых данных в реальном времени, который находит широкое применение в различных индустриях для обработки огромных объемов данных с низкой задержкой. В центре этой платформы лежит способность эффективно распределять данные между множеством производителей (producers) и потребителей (consumers), при этом поддерживая высокую пропускную способность и масштабируемость. Однако, с увеличением количества и разнообразия данных, возникает необходимость в управлении структурами этих данных, что обеспечивает Schema Registry. Этот компонент является критически важным для поддержания согласованности данных в Kafka, поскольку он управляет схемами сообщений и обеспечивает совместимость между различными версиями схем, что позволяет системам бесперебойно обмениваться данными даже при изменении структуры сообщений.

Ведущий разработчик
Другой способ понять, как работает async/await в C#
Про закулисье async/await написано предостаточно. Как правило, авторы декомпилируют IL-код, смотрят на IAsyncStateMachine и объясняют, вот дескать какое преобразование случилось с нашим исходным кодом. Из бесконечно-длинной прошлогодней статьи Стивена Тауба можно узнать мельчайшие детали реализации. Короче, всё давно рассказано. Зачем ещё одна статья?
Я приглашаю читателя пройти со мной обратным путём. Вместо изучения декомпилированного кода мы поставим себя на место дизайнеров языка C# и шаг за шагом превратим async/await в код, который почти идентичен тому, что синтезирует Roslyn.
Эволюция оценки программиста на интервью

Я более десяти лет жизни писал код в одной российской компании и активно собеседовал-нанимал людей. За это время успел пообщался с четырьмя сотнями кандидатов. На моих интервью было все – от алгоритмических задач до разговоров о «жизни». Но форма вторична – я рассматриваю интервью как инструмент для проверки совпадения с кандидатом по культуре. И все эти десять лет в моей компании менялся подход к оценке программиста на интервью и менялась культура.
Любое собеседование адекватно компании, которая его проводит. Даже если от собеседования «бомбит» и «подгорает» - проблема в кандидате, а не в компании. И как кандидат я очень рад такому простому фильтру для отбраковки не подходящих мне компаний. Но и компания тоже преследует свои цели – сохранение и изменение своей культуры за счет найма «правильных» людей. Проверка технических навыков тоже важна, но важнее нанимать людей, с которыми можно работать.
Далее я хочу рассмотреть в формате моей истории разные способы оценки программиста на техническом интервью. У меня нет цели рассказать обо всех методиках оценки компетенций. Мой обзор методов оценки будет не полным, эгоцентричным и предвзятым. Также часть моего рассказа будет собрана из историй про другие компании. Это не будет рассказ как все на самом деле обстоит-обстояло, и прошу считать эту историю чистым вымыслом.
Как языковая модель предсказывает следующий токен (часть 1)
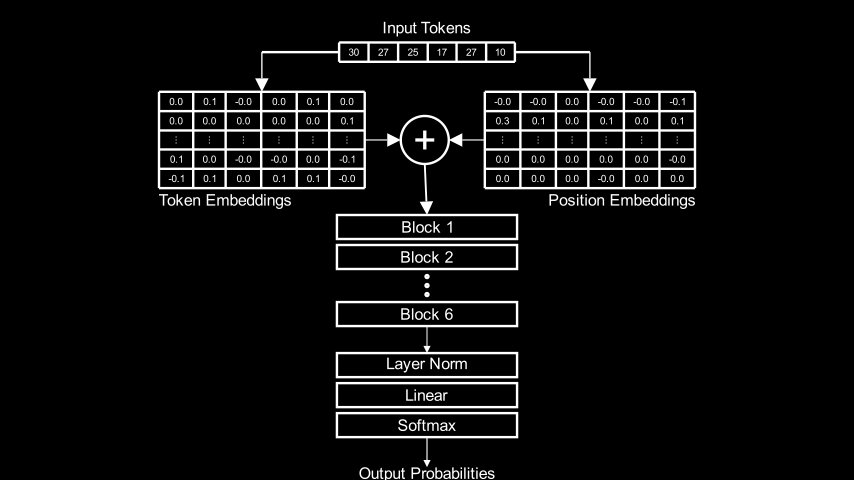
Я обучил небольшой (порядка 10 миллионов параметров) трансформер по превосходному туториалу Let’s build GPT: from scratch, in code, spelled out Андрея Карпати. После того, как он заработал, я захотел максимально глубоко понять, как он устроен внутри и как создаёт свои результаты.
В исходной научной статье, как и во всех туториалах по трансформерам упор в основном делается на многоголовом самовнимании, — механизме, при помощи которого трансформеры обучаются множественным взаимосвязям между токенами, не используя рекурретности или свёртку. Ни в одной из этих статей или туториалов я не нашёл удовлетворительного объяснения того, что происходит после внимания: как конкретно результаты вычисления внимания превращаются в точные прогнозы следующего токена?
Я подумал, что могу пропустить несколько примеров промтов через обученный мной небольшой, но работающий трансформер, изучить внутренние состояния и разобраться в них. То, что казалось мне быстрым исследованием, оказалось полугодовым погружением, но дало результаты, которыми стоит поделиться. В частности, у меня появилась рабочая теория, объясняющая, как трансформер создаёт свои прогнозы, и эмпирические свидетельства того, что это объяснение, по крайней мере, правдоподобно.
Если вы знакомы с трансформерами и хотите сразу узнать вывод, то он таков: каждый блок трансформера (содержащий слой многоголового внимания и сеть с прямой связью) изучает веса, связывающие конкретный промт с классом строк, найденных в обучающем корпусе. Распределение токенов, соответствующее этим строкам в обучающем корпусе, и есть приблизительно то, что блок выводит как прогноз для следующего токена. Каждый блок может ассоциировать один и тот же промт со своим классом строк обучающего корпуса, что приводит к другому распределению следующих токенов, а значит, и к другим прогнозам. Окончательный результат работы трансформера — это линейное сочетание прогнозов каждого блока.
Как мы решили вопрос нехватки кадров, обучив соискателей работе с Apache Spark
Привет, Хабр! На связи Т1 Цифровая Академия из Холдинга Т1. Сегодня расскажем о
том, как мы помогали клиенту справиться с нехваткой data-инженеров и увеличить темпы найма, дообучая кандидатов навыкам работы с Apache Spark на реальных задачах компании.
Что курил автор: добавим олдскула в этот безумный мир игр
Под катом вы найдёте описание игры, фичи, а также узнаете про призы за топовые места.

Нескучный API

Как создать АПИ для умных? Такое апи, чтобы создание клиента для него было не скучным механическим процессом, а настоящим приключением с элементами детектива, хоррора и мистики? Такое апи, о котором пользователи будут взахлёб рассказываете коллегам? Апи взрывающее мозг, заставляющее смеяться, кричать и плакать? Я постарался отобрать лучшие практики, с которыми пришлось столкнуться.
Стилизация изображений с помощью нейронных сетей: никакой мистики, просто матан
Приветствую тебя, Хабр! Наверняка вы заметили, что тема стилизации фотографий под различные художественные стили активно обсуждается в этих ваших интернетах. Читая все эти популярные статьи, вы можете подумать, что под капотом этих приложений творится магия, и нейронная сеть действительно фантазирует и перерисовывает изображение с нуля. Так уж получилось, что наша команда столкнулась с подобной задачей: в рамках внутрикорпоративного хакатона мы сделали стилизацию видео, т.к. приложение для фоточек уже было. В этом посте мы с вами разберемся, как это сеть "перерисовывает" изображения, и разберем статьи, благодаря которым это стало возможно. Рекомендую ознакомиться с прошлым постом перед прочтением этого материала и вообще с основами сверточных нейронных сетей. Вас ждет немного формул, немного кода (примеры я буду приводить на Theano и Lasagne), а также много картинок. Этот пост построен в хронологическом порядке появления статей и, соответственно, самих идей. Иногда я буду его разбавлять нашим недавним опытом. Вот вам мальчик из ада для привлечения внимания.
Сегментация текстовых строк документов на символы с помощью сверточных и рекуррентных нейронных сетей
Важность сегментации обусловлена тем обстоятельством, что в основе большинства современных систем оптического распознавания текста лежат классификаторы (в том числе — нейросетевые) отдельных символов, а не слов или фрагментов текста. В таких системах ошибки неправильного проставления разрезов между символами как правило являются причиной львиной доли ошибок конечного распознавания.
Поиск границ символов усложняется из-за артефактов печати и оцифровки (сканирования) документа, приводящим к “рассыпанию” и “склеиванию” символов. В случае использования стационарных или мобильных малоразмерных видеокамер спектр артефактов оцифровки существенно пополняется: возможны дефокусировка и смазывание, проективные искажения, деформирование и изгибы документа. При съемке камерой в естественных сценах на изображениях часто возникают паразитные перепады яркости (тени, отражения), а также цветовые искажения и цифровой шум в результате низкой освещенности. На рисунке ниже показаны примеры сложных случаев при сегментации полей паспорта РФ.





В этой статье мы расскажем о методе сегментации символов текстовых строк документов, разработанном нами в Smart Engines, основанный на обучении сверточных и рекуррентных нейронных сетей. Основным рассматриваемым в работе документом является паспорт РФ.
Умный дом. Конкретная реализация
 Добрый день, уважаемое сообщество!
Добрый день, уважаемое сообщество! В своих предыдущих статьях я рассказывал о том, как делаю у себя умный дом. С тех пор прошло уже достаточно большое количество времени и я достаточно серьезно продвинулся как в оборудовании, так и в софте. Думаю, что эту очередную статью можно смело называть «Умный дом v3» :)
Будущее API

Думаю, мы недостаточно говорим о будущем API. Я не помню ни одного хорошего обсуждения о том, что ждёт API в будущем. Вот совсем не припоминаю. Но если мы хорошенько подумаем об этом, то придём к выводу, что API в том виде, в каком мы понимаем сейчас — это далеко не конец игры. В этом виде API не будет оставаться вечно. Давайте попробуем заглянуть в будущее и ответить на вопрос, что случится с API в будущем.
Шаблоны проектирования с человеческим лицом

Шаблоны проектирования — это способ решения периодически возникающих проблем. Точнее, это руководства по решению конкретных проблем. Это не классы, пакеты или библиотеки, которые вы можете вставить в своё приложение и ожидать волшебства.
Как сказано в Википедии:
В программной инженерии шаблон проектирования приложений — это многократно применяемое решение регулярно возникающей проблемы в рамках определённого контекста архитектуры приложения. Шаблон — это не законченное архитектурное решение, которое можно напрямую преобразовать в исходный или машинный код. Это описание подхода к решению проблемы, который можно применять в разных ситуациях.
 Будьте осторожны
Будьте осторожны
- Шаблоны проектирования — не «серебряная пуля».
- Не пытайтесь внедрять их принудительно, последствия могут быть негативными. Помните, что шаблоны — это способы решения, а не поиска проблем. Так что не перемудрите.
- Если применять их правильно и в нужных местах, они могут оказаться спасением. В противном случае у вас будет ещё больше проблем.
В статье приведены примеры на PHP 7, но пусть вас это не смущает, ведь заложенные в шаблонах принципы неизменны. Кроме того, внедряется поддержка других языков.
Тюнинг SQL Server 2012 под SharePoint 2013/2016. Часть 1
Этот пост является первым из двух, в которых я расскажу о важной с точки зрения администрирования порталов SharePoint теме – по тюнингу серверов SQL, нацеленного на достижение высокой производительности. Крайне важно обеспечить тщательное планирование, корректную инсталляцию и последующую настройку SQL-сервера, который будет использоваться для хранения данных, размещенных на корпоративном портале.
В этом посте вы сможете прочитать о планировании инсталляции SQL-сервера. Чуть позже будет опубликована вторая часть, посвященная установке SQL-сервера и последующему конфигурированию.

Как я сделал тестер-оптимизатор для нахождения прибыльных стратегий на Бирже — 2

Рис. 1. Оптимизация многомерного пространства алгоритмов торговых стратегий.
Оптимизация торговых стратегий
В процессе алгоритмической торговли постоянно возникает необходимость настройки параметров алгоритмов торговых стратегий. Сочетания всех возможных параметров превращается в большое многомерное пространство вариантов стратегий. Чтобы получить самые прибыльные и стабильные стратегии нужно исследовать это пространство и подобрать оптимальные параметры для торговли.
Эффективное распределение ролей посредством RACI матрицы (Обновлено)
 Часто ли Вы сталкивались с таким явлением, как нерациональное распределение обязанностей? Сколько раз приходилось наблюдать за тем, как один человек «на все руки мастер» выполняет работу за пятерых? А так называемый «специалист, занимающийся не понятно чем» — знакомо? Такие варианты, а также им подобные нередко приходилось видеть ранее в отечественных реалиях. Этот же «совок» многим приходится наблюдать, и что хуже, чувствовать на своей личной шкуре и поныне во многих госструктурах.
Часто ли Вы сталкивались с таким явлением, как нерациональное распределение обязанностей? Сколько раз приходилось наблюдать за тем, как один человек «на все руки мастер» выполняет работу за пятерых? А так называемый «специалист, занимающийся не понятно чем» — знакомо? Такие варианты, а также им подобные нередко приходилось видеть ранее в отечественных реалиях. Этот же «совок» многим приходится наблюдать, и что хуже, чувствовать на своей личной шкуре и поныне во многих госструктурах.О таком умном словосочетании, как «разделение полномочий» говорят часто. Но все ли знают, как его применять на практике, и кому удается этим реально воспользоваться? Приглядевшись внимательно, делаем вывод, что такое явление происходит по большому счету, в компаниях частного сектора, в особенности тех, кто работает с иностранным клиентом.
Именно из-за «бугра» до нас дошла любопытная аббревиатура под названием RACI. При этом, зачастую перед ней можно наблюдать разного рода умности а-ля «матрица» или «модель». Что это и с чем его едят, попытаюсь объяснить читателю далее. Возможно, кому-то уже повезло работать в коллективах, где каждый знает свои обязанности и область ответственности – за таких людей можно только порадоваться. При этом лично я верю, что далеко не у всех всё идеально в сфере разделения полномочий. Для таких людей данная статья может оказаться полезной.
Как я создал SaaS-сервис, который приносит мне 1000 долларов в месяц
Всё началось с моего другого SaaS-сервиса с названием Postio, который я сделал, чтобы облегчить людям поиск и публикацию контента на их страницах и в их группах в социальных сетях. В рамках своей маркетинговой стратегии я приобрёл и опубликовал на своём блоге десяток статей по различным темам, ориентированных на аудиторию веб-сервиса, чтобы получить дополнительный трафик с поисковых систем.
Потом вдруг Postio начал получать относительно большой трафик от Google и Яндекс (русская поисковая система) с ключевыми словами, которые не имели ничего общего с самим Postio.
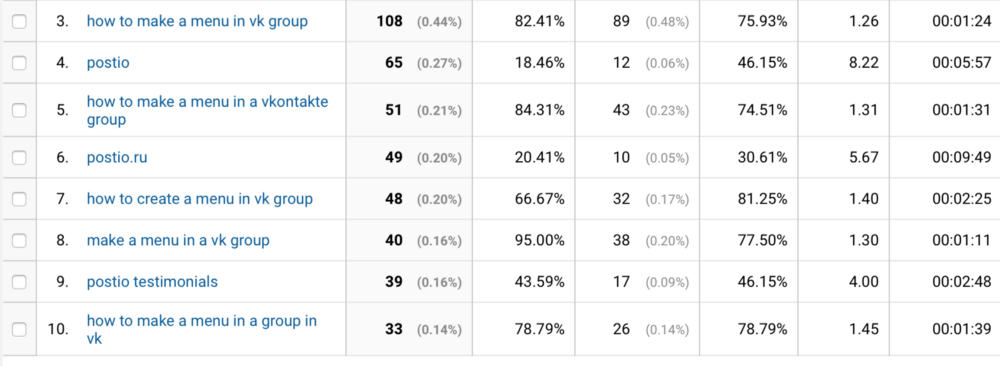
Аналитическая статистика Гугл по суточному трафику
Здесь-то и начинается фактическая история.
OWASP TOP-10: практический взгляд на безопасность веб-приложений
Чтобы Всем было интереснее, мы не будем рекламировать свой сервис (ну если только чуть-чуть). Вместо этого, мы подготовили первую серию публикаций, которая будет посвящена такой увлекательной и крайне актуальной теме, как безопасность Web-приложений. Мы постараемся раскрыть опасности, сопутствующие любому действующему интернет-проекту и простым языком донести всю важность ответственного подхода к рутинным, казалось бы, мелочам в вопросах безопасности данных. Надеемся наши статьи будут не бесполезны для Вас. Уверены, так Вы узнаете нас гораздо лучше.
Application Insights. Про аналитику и другие новые инструменты
JSX — подробности

Этой публикацией я открываю серию переводов раздела "Продвинутые руководства" (Advanced Guides) официальной документации библиотеки React.js.
JSX — подробности
Фундаментально, JSX является синтаксическим сахаром для функции React.createElement(component, props, ...children).