Сегодня многие компании работают с огромным количеством данных. Нет, я сейчас не о паттернах BigData, а просто о том, что удивить десятком-другим терабайт данных на серверах отдельно взятой компании никого уже нельзя. Но многие идут дальше – сотни терабайт, петабайты, десятки петабайт… Конечно, хорошо, когда ваши данные и задачи по их обработке попадают под идеологию mapreduce, но намного чаще все эти данные представляют собой либо «просто файлы», либо тома виртуальных машин, либо уже структурированные и шардированные своим образом данные. В таких случаях компания приходит к идее необходимости развертывания системы хранения данных.

Добавляет популярности СХД сегодня и системы, подобные OpenStack – ведь приятно управлять своими серверами не заботясь о том, что в одном сервере не работает диск, что одна из стоек обесточена. Не заботиться о том, что железо на одном Самом Важном Сервере устарело и для его апгрейда необходимо деградировать ваши сервисы до минимального уровня. Конечно, такие случаи могут быть ошибкой проектирования, но будем честны – все мы можем допустить такие ошибки.
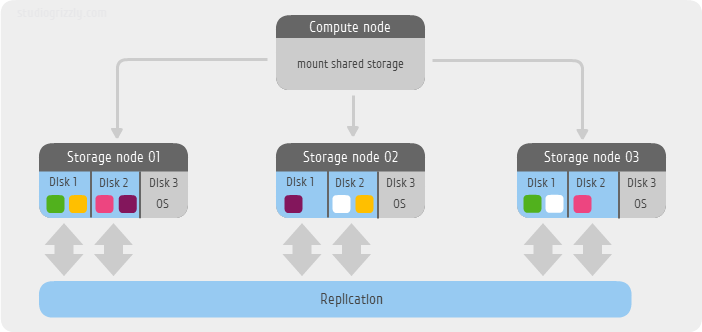
В итоге компания встаёт перед непростым выбором: создать СХД самостоятельно на основе открытого ПО (Ceph, MuseFS, hdfs – есть из чего выбрать с минимальными затратами на интеграцию, но придется потратить время на дизайн и развертывание) или купить готовую проприетарную СХД и потратить время и силы на её интеграцию (с риском того что СХД со временем достигнет лимита своей ёмкости или производительности).
Но что если взять за основу Ceph, для которого сложно придумать невыполнимую задачу в области хранения данных, заручиться поддержкой какого-нибудь Ceph-вендора (например Inktank, которые его и создали), взять современные серверы с большим количеством SAS-дисков, написать web-интерфейс для управления, добавить дополнительные возможности для эффективного развертывания и мониторинга… Звучит заманчиво, но сложно для среднестатистической компании, тем более, если это не IT-компания.
К счастью, обо всём этом уже позаботились в компании Fujitsu, в лице продукта
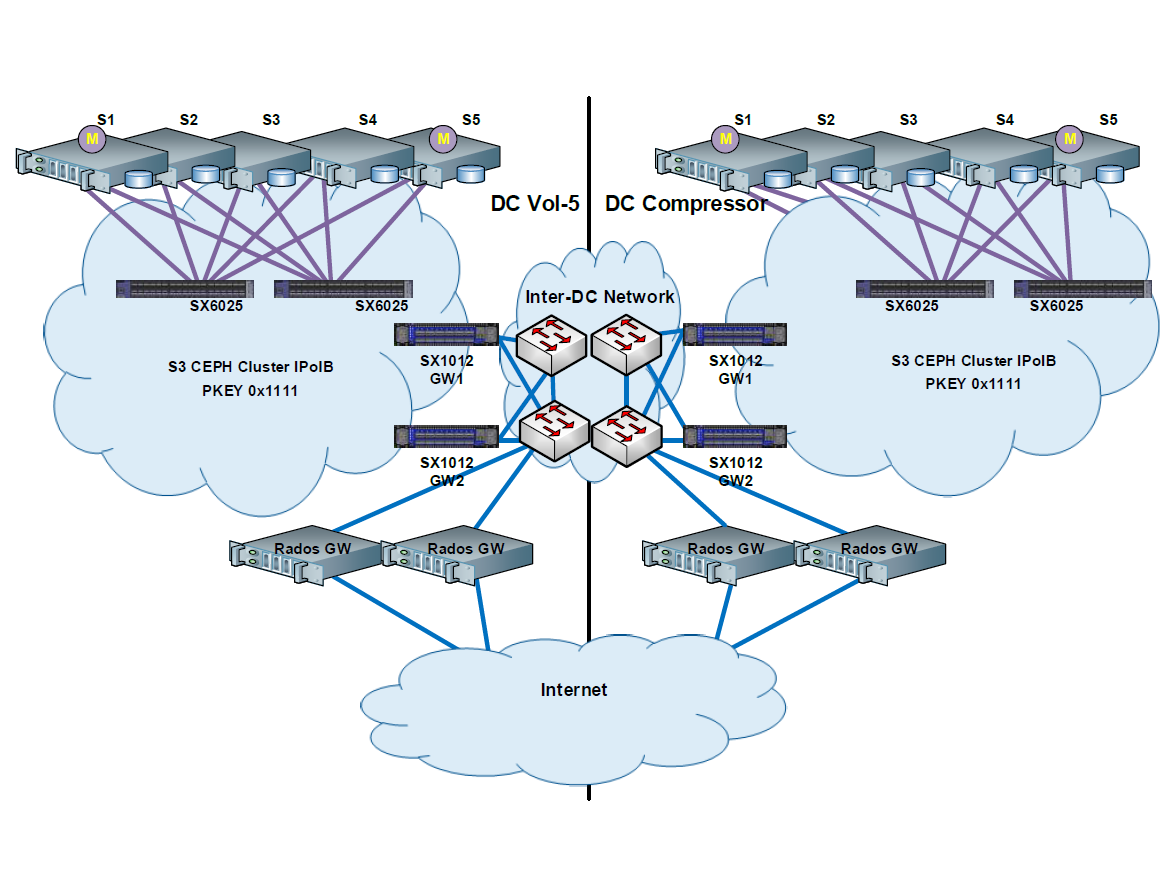
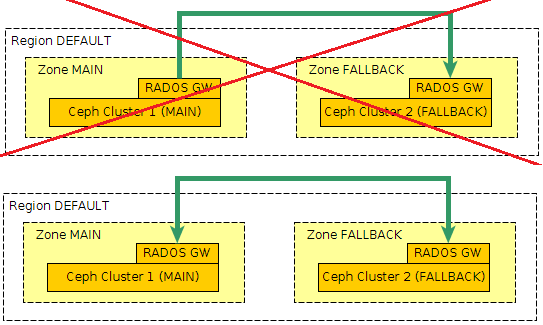
ETERNUS CD10000 – первой enterprise-СХД, основанной на Inktank Ceph Enterprise, с которой мы вас сегодня и познакомим.





 В прошлом уроке мы таки осилили открытие окна и примитивный пользовательский ввод. В этом уроке мы разберем все азы вывода вершин на экран и воспользуемся всеми возможностями OpenGL, вроде VAO, VBO, EBO для того, чтобы вывести пару треугольников.
В прошлом уроке мы таки осилили открытие окна и примитивный пользовательский ввод. В этом уроке мы разберем все азы вывода вершин на экран и воспользуемся всеми возможностями OpenGL, вроде VAO, VBO, EBO для того, чтобы вывести пару треугольников.  Статистика приходит к нам на помощь при решении многих задач, например: когда нет возможности построить детерминированную модель, когда слишком много факторов или когда нам необходимо оценить правдоподобие построенной модели с учётом имеющихся данных. Отношение к статистике неоднозначное. Есть мнение, что существует три вида лжи: ложь, наглая ложь и статистика. С другой стороны, многие «пользователи» статистики слишком ей верят, не понимая до конца, как она работает: применяя, например, тест
Статистика приходит к нам на помощь при решении многих задач, например: когда нет возможности построить детерминированную модель, когда слишком много факторов или когда нам необходимо оценить правдоподобие построенной модели с учётом имеющихся данных. Отношение к статистике неоднозначное. Есть мнение, что существует три вида лжи: ложь, наглая ложь и статистика. С другой стороны, многие «пользователи» статистики слишком ей верят, не понимая до конца, как она работает: применяя, например, тест 



{kind=link}