Здравствуй, Хабр! Данная статья предназначена для тех, кто приблизительно шарит в математических принципах работы нейронных сетей и в их сути вообще, поэтому советую ознакомиться с этим перед прочтением. Хоть как-то понять, что происходит можно сначала здесь, потом тут.
Недавно мне пришлось сделать нейросеть для распознавания рукописных цифр(сегодня будет не совсем её код) в рамках школьного проекта, и, естественно, я начал разбираться в этой теме. Посмотрев приблизительно достаточно об этом в интернете, я понял чуть более, чем ничего. Но неожиданно(как это обычно бывает) получилось наткнуться на книгу Саймона Хайкина(не знаю почему раньше не загуглил). И тогда началось потное вкуривание матчасти нейросетей, состоящее из одного матана.







 Сонары используются для обнаружения и исследования подводных объектов, в то время как похожие устройства, называемые радары — для исследования надводных, наземных, воздушных и космических объектов. Многое из того, что сказано ниже про сонары, справедливо и для радаров, либо имеет очевидные сходства.
Сонары используются для обнаружения и исследования подводных объектов, в то время как похожие устройства, называемые радары — для исследования надводных, наземных, воздушных и космических объектов. Многое из того, что сказано ниже про сонары, справедливо и для радаров, либо имеет очевидные сходства.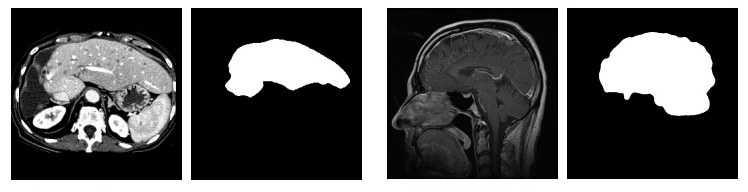 Слева — исходное изображение, справа — сегментированное
Слева — исходное изображение, справа — сегментированное