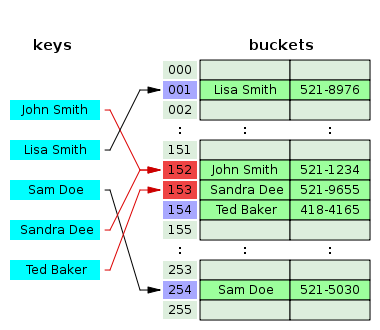
В продолжение рубрики "конспект админа" хотелось бы разобраться в нюансах технологий ОЗУ современного железа: в регистровой памяти, рангах, банках памяти и прочем. Подробнее коснемся надежности хранения данных в памяти и тех технологий, которые несчетное число раз на дню избавляют администраторов от печалей BSOD.




 Изложение
Изложение