К моему удивлению, предыдущую статью приняли достаточно тепло. Сегодня продолжим рассмотрение этого вопроса.


Инженер





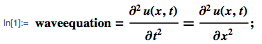

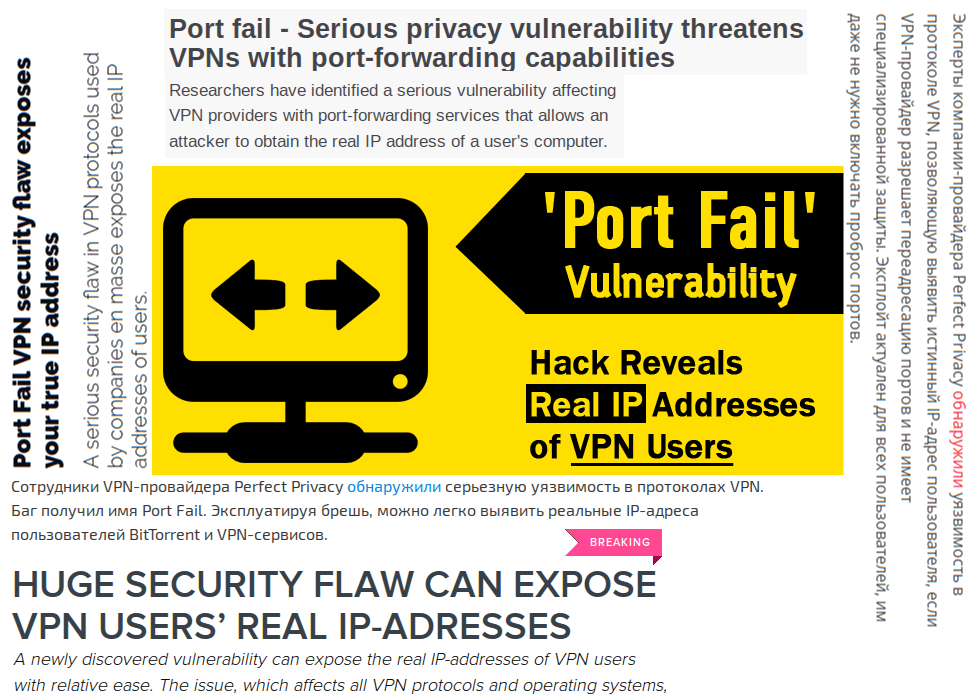
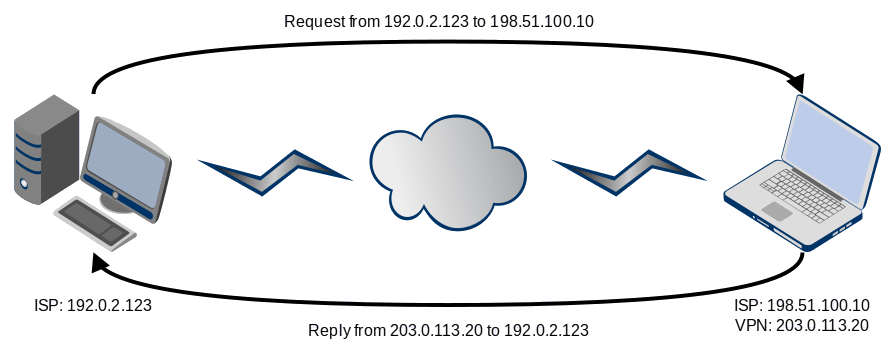
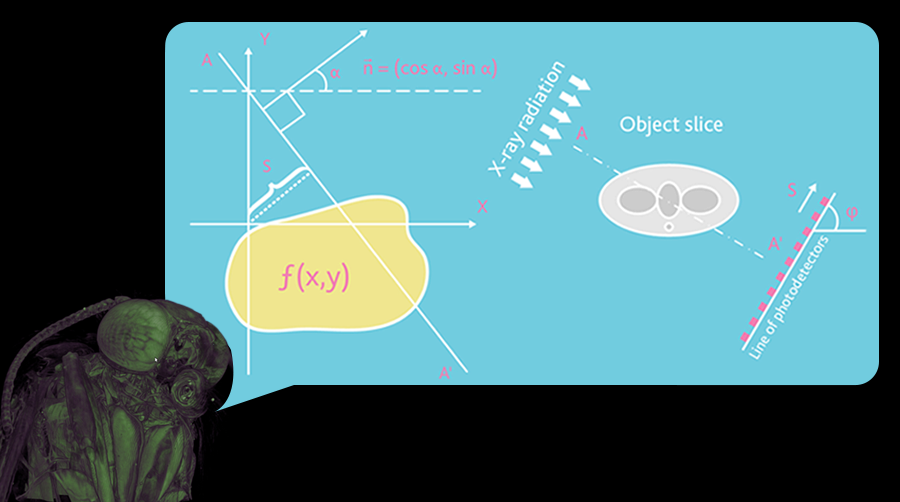
 А еще сегодня 16 декабря, день рождения Иоганна Радона, австрийского математика, ректора Венского университета, который в 1917 году ввел интегральное преобразование функции многих переменных, родственное преобразованию Фурье, используемое сегодня во всех томографах.
А еще сегодня 16 декабря, день рождения Иоганна Радона, австрийского математика, ректора Венского университета, который в 1917 году ввел интегральное преобразование функции многих переменных, родственное преобразованию Фурье, используемое сегодня во всех томографах. Прим. переводчика: Это перевод статьи Питера Брайта (Peter Bright) «How security flaws work: The buffer overflow» о том, как работает переполнение буфера и как развивались уязвимости и методы защиты.



import numpy as np
X = np.array([ [0,0,1],[0,1,1],[1,0,1],[1,1,1] ])
y = np.array([[0,1,1,0]]).T
alpha,hidden_dim = (0.5,4)
synapse_0 = 2*np.random.random((3,hidden_dim)) - 1
synapse_1 = 2*np.random.random((hidden_dim,1)) - 1
for j in xrange(60000):
layer_1 = 1/(1+np.exp(-(np.dot(X,synapse_0))))
layer_2 = 1/(1+np.exp(-(np.dot(layer_1,synapse_1))))
layer_2_delta = (layer_2 - y)*(layer_2*(1-layer_2))
layer_1_delta = layer_2_delta.dot(synapse_1.T) * (layer_1 * (1-layer_1))
synapse_1 -= (alpha * layer_1.T.dot(layer_2_delta))
synapse_0 -= (alpha * X.T.dot(layer_1_delta))
X = np.array([ [0,0,1],[0,1,1],[1,0,1],[1,1,1] ])
y = np.array([[0,1,1,0]]).T
syn0 = 2*np.random.random((3,4)) - 1
syn1 = 2*np.random.random((4,1)) - 1
for j in xrange(60000):
l1 = 1/(1+np.exp(-(np.dot(X,syn0))))
l2 = 1/(1+np.exp(-(np.dot(l1,syn1))))
l2_delta = (y - l2)*(l2*(1-l2))
l1_delta = l2_delta.dot(syn1.T) * (l1 * (1-l1))
syn1 += l1.T.dot(l2_delta)
syn0 += X.T.dot(l1_delta)
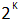 раз расширить диапазон представимых чисел в формате с плавающей точкой, где К — количество разрядов машинной мантиссы.
раз расширить диапазон представимых чисел в формате с плавающей точкой, где К — количество разрядов машинной мантиссы.