Вот какие заголовки мелькали в финансовых новостях в последние недели:
«Цена биткоина наконец дошла до 10 000 $!» —
The Economist, 28 ноября 2017
«Биткоин перешагнул рубеж в 10 000 $!» —
CNBC, 28 ноября 2017 года
«БИТКОИН ВЗЛЕТЕЛ ВЫШЕ 11 000 $!» —
The Guardian, 29 ноября 2017 года
Не успели эти известия толком перекипеть на новостных порталах, как буквально через сутки цена уже выросла до $11,500. К моменту, когда вышли заметки про одиннадцать тысяч, он уже успел упасть до девяти. А потом, пока журналисты лихорадочно дописывали последние строчки про «обвал биткоина», снова вернулся на уровень 11 000 $ за BTC.
И это не первый такой случай.
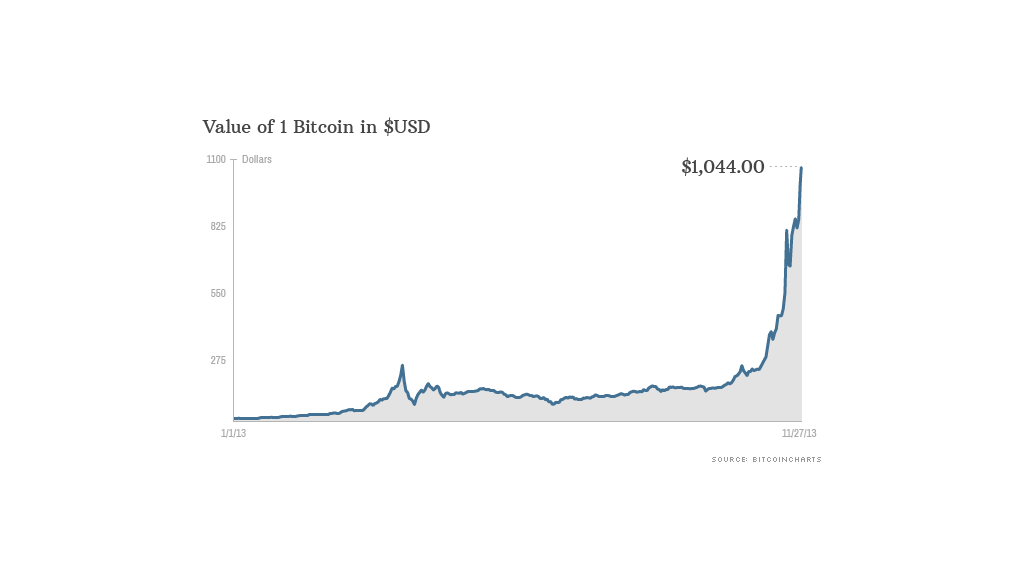
Мы уже сталкивались с чем-то подобным в 2013 году.
Когда стоимость биткоина подошла к отметке в 1000 $, пресса подняла шумиху, что привело к образованию «пузыря». В январе 2013 биткоин уходил примерно за 15 $, к апрелю цена подскочила до 266 $, а затем обвалилась до 50 $. К ноябрю она превысила 1 200$, достигнув максимума в 1 242 $ на Mt.Gox. За тот год биткоин вырос почти в сто раз – это на порядок больше, чем десятикратный подъем, через который он прошел в 2017 году.
Графики выглядят почти одинаково,
а новостные заголовки вообще слово в слово. Просто припишите нолик.
Пресса любит такие вещи, потому что люди читают их с большим интересом. Истории о том, как кто-то купил старый компьютер за 25 баксов и
обнаружил на нем 5 000 биткоинов, или случайно
выбросил жесткий диск с 7 500 биткоинами и долго искал его на свалке, или
отдал 10 000 биткоинов за две пиццы, раздувают ажиотаж и приносят деньги.










 Как-то раз в голове возникла мысль, а что бы сделать такое, чтобы скрестить старый радиоприемник в деревянном корпусе и современный контроллер для интернета-вещей ESP32? То ли с головой не так что-то, то ли делать мне нечего, но скрестить получилось. Не шаблонно, в целом, хотя судить вам, дорогие читатели Хабра).
Как-то раз в голове возникла мысль, а что бы сделать такое, чтобы скрестить старый радиоприемник в деревянном корпусе и современный контроллер для интернета-вещей ESP32? То ли с головой не так что-то, то ли делать мне нечего, но скрестить получилось. Не шаблонно, в целом, хотя судить вам, дорогие читатели Хабра).