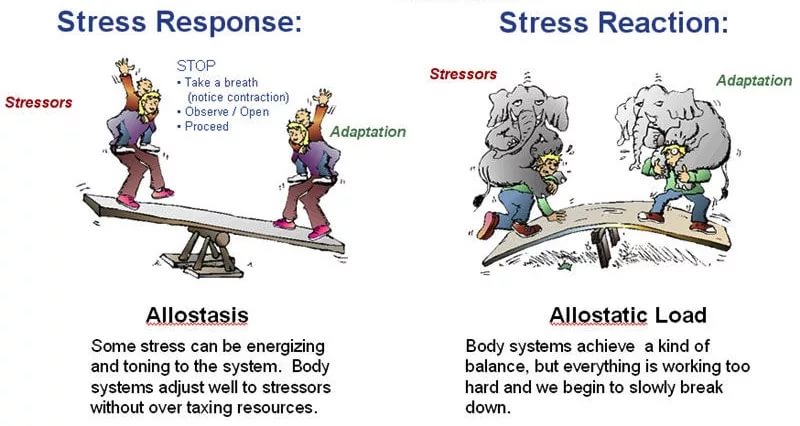
Восемь ошибок, которые я допускал, когда был джуниором
6 min
Translation
В начале карьеры разработчика часто бывает страшновато: перед тобой встают незнакомые проблемы, многому нужно научиться и приходится принимать сложные решения. И в некоторых случаях мы в этих решениях ошибаемся. Это вполне естественно, и грызть себя по этому поводу не стоит. А вот что стоит делать, так это запоминать свой опыт на будущее. Я — разработчик-сениор, который допустил в свое время уйму ошибок. Ниже я расскажу о восьми самых серьезных из них, которые совершил, когда был еще новичком в разработке, и поясню, как их можно было избежать.








 Это будет длиннопост. Я давно хотел написать этот обзор, но
Это будет длиннопост. Я давно хотел написать этот обзор, но