Перевод поста Стивена Вольфрама "What Is Spacetime, Really?".
Выражаю огромную благодарность Кириллу Гузенко KirillGuzenko за помощь в переводе и подготовке публикации.
Примечание: данный пост Стивена Вольфрама неразрывно связан с теорией
клеточных автоматов и других смежных понятий, а также с его книгой
A New Kind of Science (Новый вид науки), на которую из этой статьи идёт большое количество ссылок. Пост хорошо иллюстрирует применение программирования в научной сфере, в частности, Стивен показывает (код приводится в книге) множество примеров программирования на языке Wolfram Language в области физики, математики, теории вычислимости, дискретных систем и др.
Содержание
Простая теория всего?
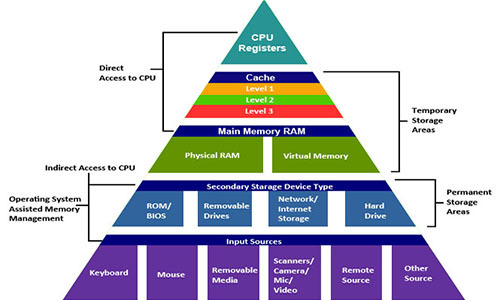
Структура данных Вселенной
Пространство как граф
Может быть, нет ничего, кроме пространства
Что есть время?
Формирование сети
Вывод СТО
Вывод ОТО (Общей теории относительности)
Частицы, квантовая механика и прочее
В поисках вселенной
Ок, покажите мне Вселенную
Заниматься физикой или нет — вот в чем вопрос
Что требуется?
Но пришло ли время?
Сто лет назад
Альберт Эйнштейн опубликовал общую теорию относительности — блестящую, элегантную теорию, которая пережила целый век и открыла единственный успешный путь к описанию
пространства-времени (
пространственно-временного континуума).
Есть много различных моментов в теории, указывающих, что общая теория относительности — не последняя точка в истории о пространстве-времени. И в самом деле, пускай мне нравится ОТО как абстрактная теория, однако я пришел к мысли, что она, возможно, на целый век увела нас от пути познания истинной природы пространства и времени.
Я размышлял об устройстве пространства и времени немногим более сорока лет. В начале, будучи
молодым физиком-теоретиком, я просто принимал эйнштейновскую математическую постановку задачи специальной и общей теории относительности, а так же занимался
некоторой работой в квантовой теории поля, космологии и других областях, основываясь на ней.
Но около 35 лет назад, отчасти вдохновленный своим опытом в технических областях, я начал более детально исследовать фундаментальные вопросы теоретической науки, с чего и начался
мой длинный путь выхода за рамки традиционных математических уравнений и использования вместо них вычислений и программ как основных моделей в науке. Вскоре после этого
мне довелось выяснить, что даже очень простые программы могут демонстрировать очень сложное поведение, а затем, спустя годы, я обнаружил, что
системы любого вида могут быть представлены в терминах этих программ.
Воодушевившись этим успехом, я стал размышлять, может ли это иметь отношение к важнейшему из научных вопросов — физической теории всего.
Во-первых, такой подход казался не слишком перспективным — хотя бы потому, что модели, которые я изучал
(клеточные автоматы), казалось, работали так, что это полностью противоречило всему тому, что я знал из физики. Но где-то в 88-м году — в то время, когда вышла первая версия
Mathematica, я начал понимать, что если бы я изменил свои представления о пространстве и времени, возможно, это к чему то бы меня привело.







 Привет. В этой статье будет рассмотрен способ
Привет. В этой статье будет рассмотрен способ