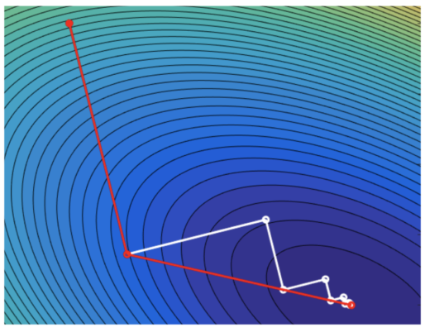
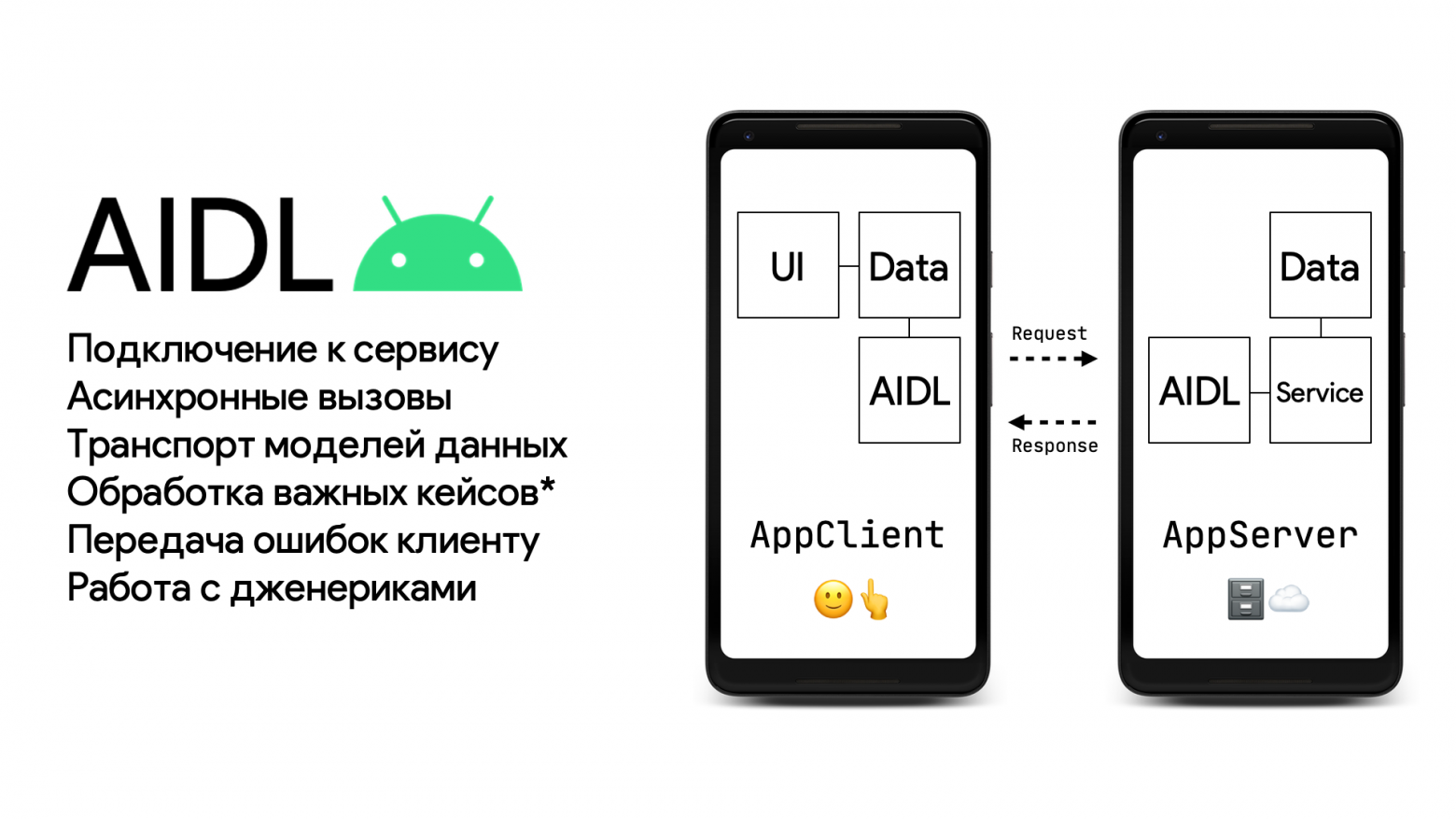
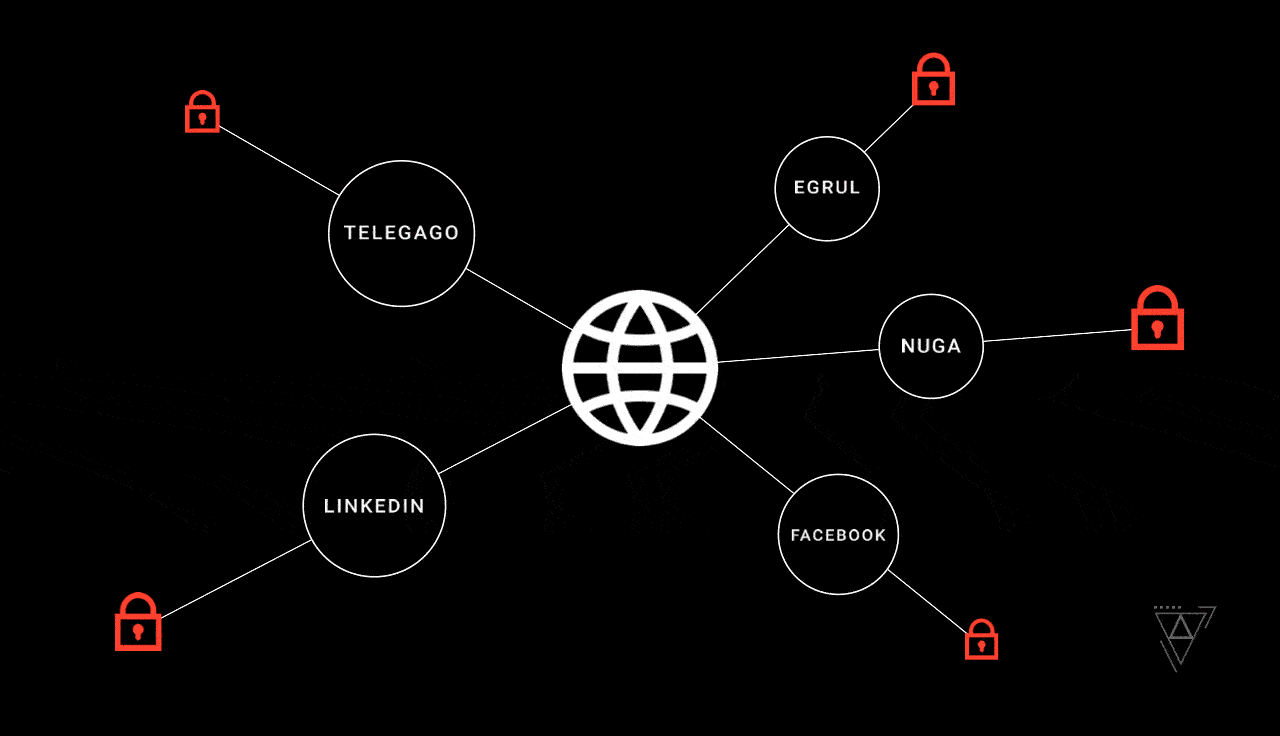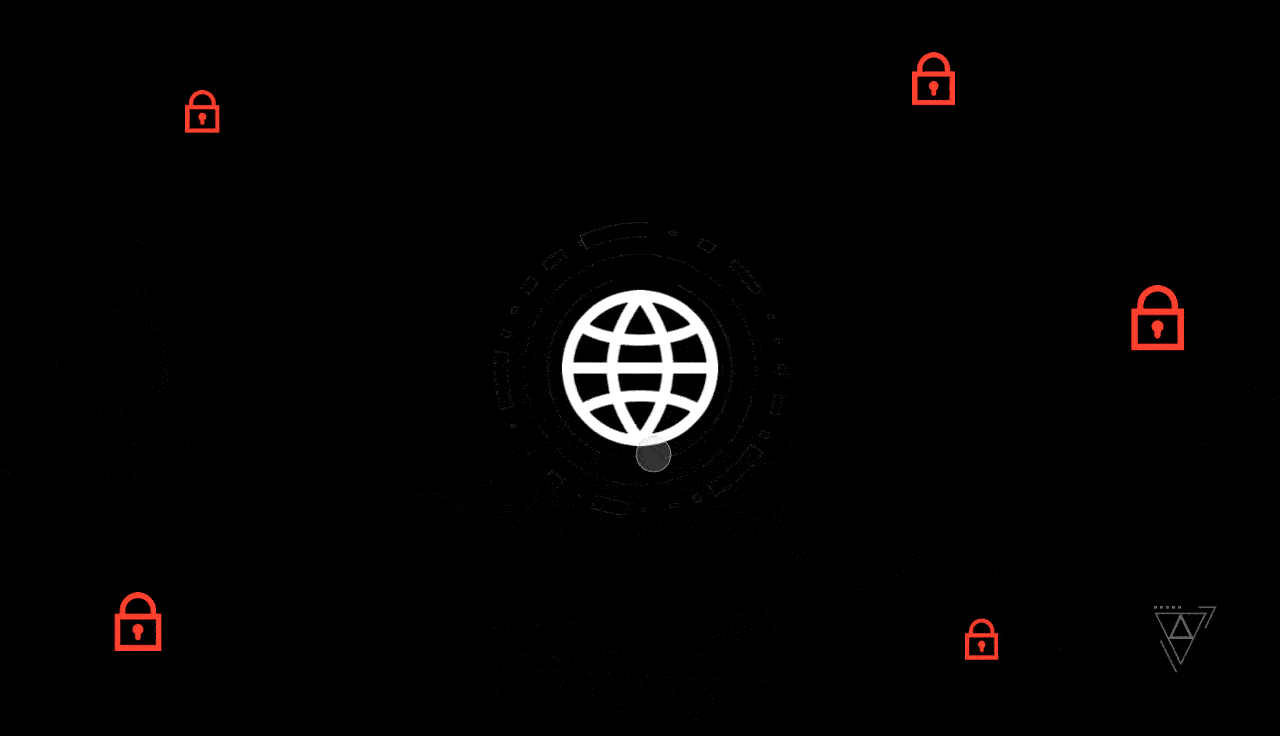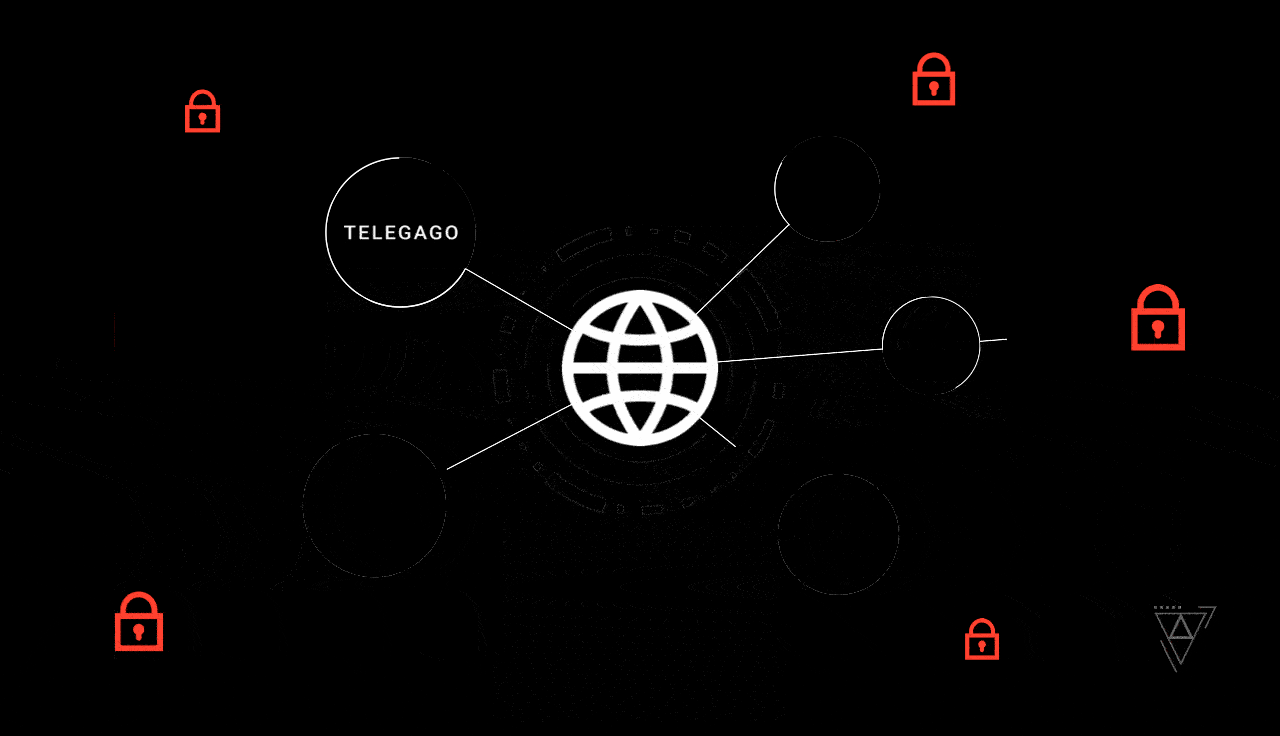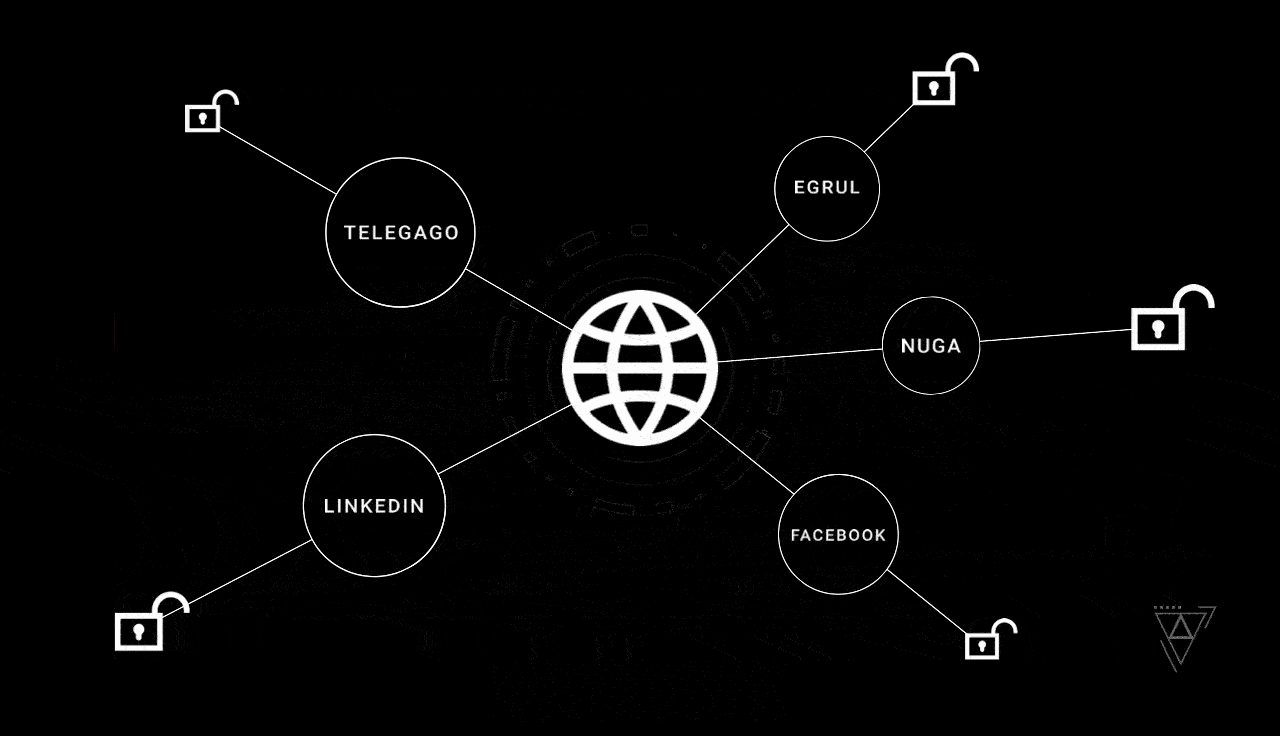
### Часть 1. Золотое «Ку»
Лет в шесть мне попался в руки дедовский справочник[50] по грузовым автомобилям середины 20-го века. Добротный, напечатанный на гладкой плотной бумаге раритет. Единственное, что вообще осталось на память от деда после распада страны, войн и переездов.


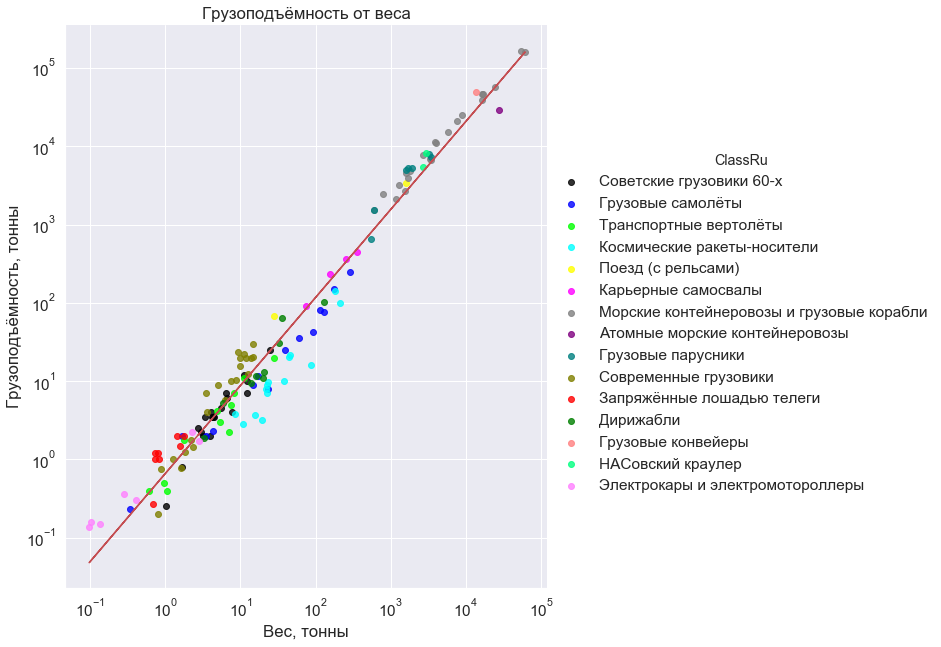
В справочнике содержалось множество интересных ТТХ, так что слово «грузоподъёмность» стало мне знакомо с раннего детства. И когда отец на прогулке упомянул, что любой грузовик весит столько же, сколько увозит сам, я это запомнил. Запомнил и, много позже, заинтересовался.
Отец был прав. Для грузовиков 60-х годов это правило выполняется с довольно удивительной точностью:
Лет в шесть мне попался в руки дедовский справочник[50] по грузовым автомобилям середины 20-го века. Добротный, напечатанный на гладкой плотной бумаге раритет. Единственное, что вообще осталось на память от деда после распада страны, войн и переездов.
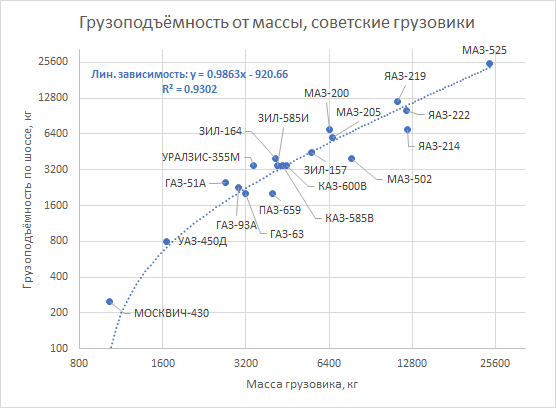
В справочнике содержалось множество интересных ТТХ, так что слово «грузоподъёмность» стало мне знакомо с раннего детства. И когда отец на прогулке упомянул, что любой грузовик весит столько же, сколько увозит сам, я это запомнил. Запомнил и, много позже, заинтересовался.
Отец был прав. Для грузовиков 60-х годов это правило выполняется с довольно удивительной точностью: