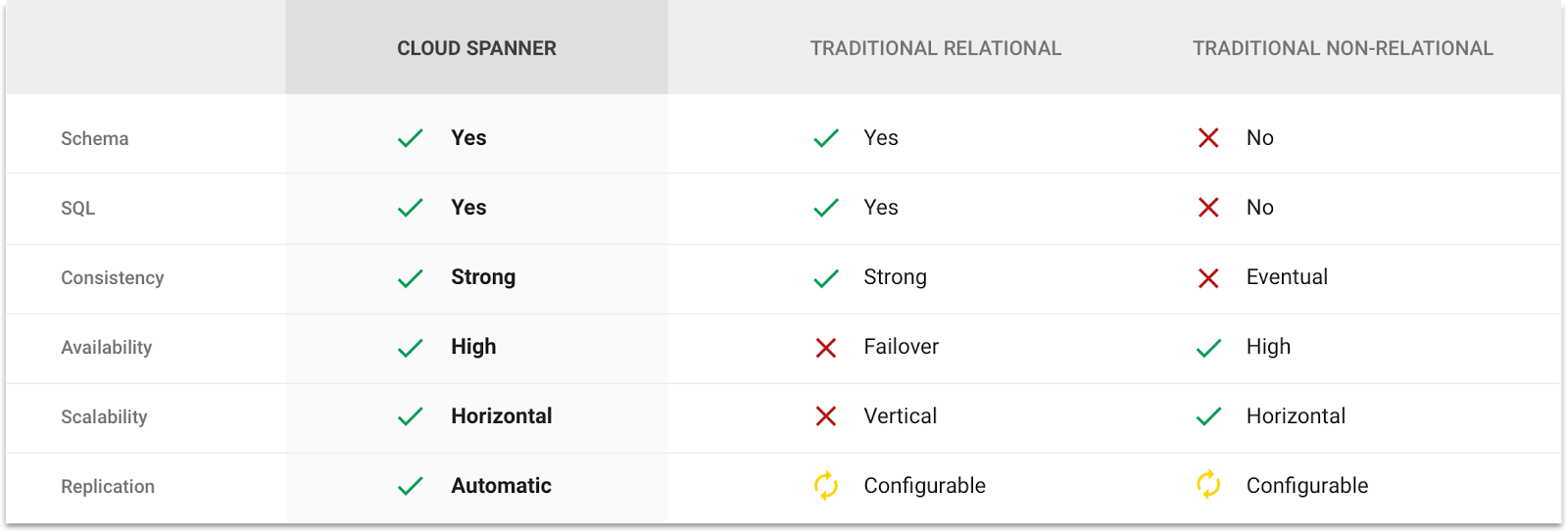
Анонимный разработчик написал статью для «Нетологии» о том, кто такие программисты, как ими становятся, и почему все программисты попадают в свой собственный Таиланд. При условии, если они пишут читабельный код, конечно же.

Если вы думаете, что быть программистом просто, то вы ошибаетесь. Если думаете, что трудно, то тоже ошибаетесь. Так кто такой программист, как писать крутой код и что отличает хороший тон от плохого в Таиланде или без него разбираемся с анонимусом.
Если вы думаете, что быть программистом просто, то вы ошибаетесь. Если думаете, что трудно, то тоже ошибаетесь. Так кто такой программист, как писать крутой код и что отличает хороший тон от плохого в Таиланде или без него разбираемся с анонимусом.





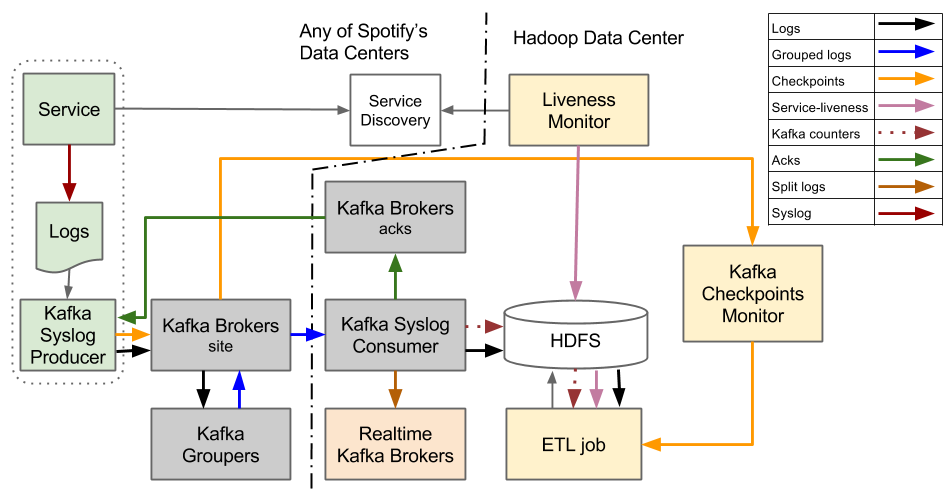
 Недавно мы в Voximplant улучшали авторизацию в SDK. Посмотрев на результаты, я несколько опечалился, что вместо простого и понятного токена их стало две штуки: access token и refresh token. Которые мало того что надо регулярно обновлять, так еще документировать и объяснять в
Недавно мы в Voximplant улучшали авторизацию в SDK. Посмотрев на результаты, я несколько опечалился, что вместо простого и понятного токена их стало две штуки: access token и refresh token. Которые мало того что надо регулярно обновлять, так еще документировать и объяснять в 

 Недавно я разговаривал с другом из бэкенд-разработки о том, сколько часов провожу за программированием и изучением кода в свободное время. Он показал отрывок из книги Дяди Боба «Чистый код». Там разработчики, которые репетируют код перед запуском в работе, сравниваются с музыкантами, которые много часов готовят инструменты к концерту.
Недавно я разговаривал с другом из бэкенд-разработки о том, сколько часов провожу за программированием и изучением кода в свободное время. Он показал отрывок из книги Дяди Боба «Чистый код». Там разработчики, которые репетируют код перед запуском в работе, сравниваются с музыкантами, которые много часов готовят инструменты к концерту. Специалисты по безопасности из Google обнаружили
Специалисты по безопасности из Google обнаружили