Введение
На волне хайпа криптовалют проскакивают новости о торговле биткойном на мировых биржах CME и NASDAQ. Для меня это знаковое событие: руки корпораций, надувавших пузыри доткомов и ипотек, дотянулись и до золота шифропанков — криптовалют. А в арсенале этих самых корпораций мощный рычаг — производные финансовые инструменты, или деривативы.
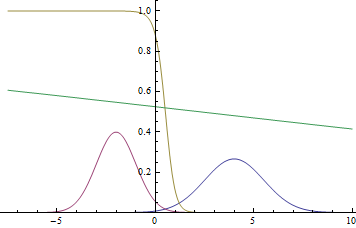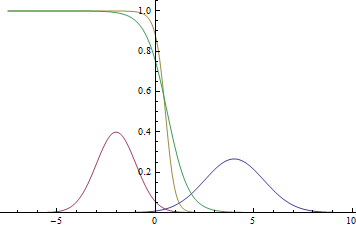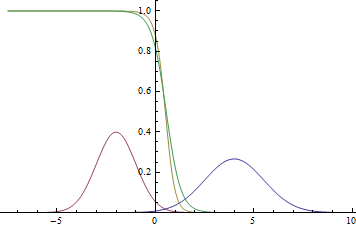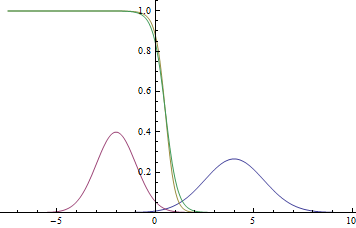
Находясь под впечатлением прочитанных не так давно историй взлетов и метаморфоз рынков деривативов — прежде всего, фьючерсных и опционных контрактов, я заинтересовался нетривиальным ценообразованием опционов. Мне открылось, что, хотя интернет полон рерайтов статей, толкующих знаменитую формулу Блэка-Шоулза, практических инструментов — web-сайтов, технологических программ или банальных руководств для программиста — не математика, по данному вопросу в интернете недостает. Пришлось вспомнить азы тервера и адаптировать строгие математические описания в популярном, понятном, прежде всего, мне самому, формате.


 Если ты на практике используешь ООП, то хорошо разбираешься в таких вещах, как
Если ты на практике используешь ООП, то хорошо разбираешься в таких вещах, как 

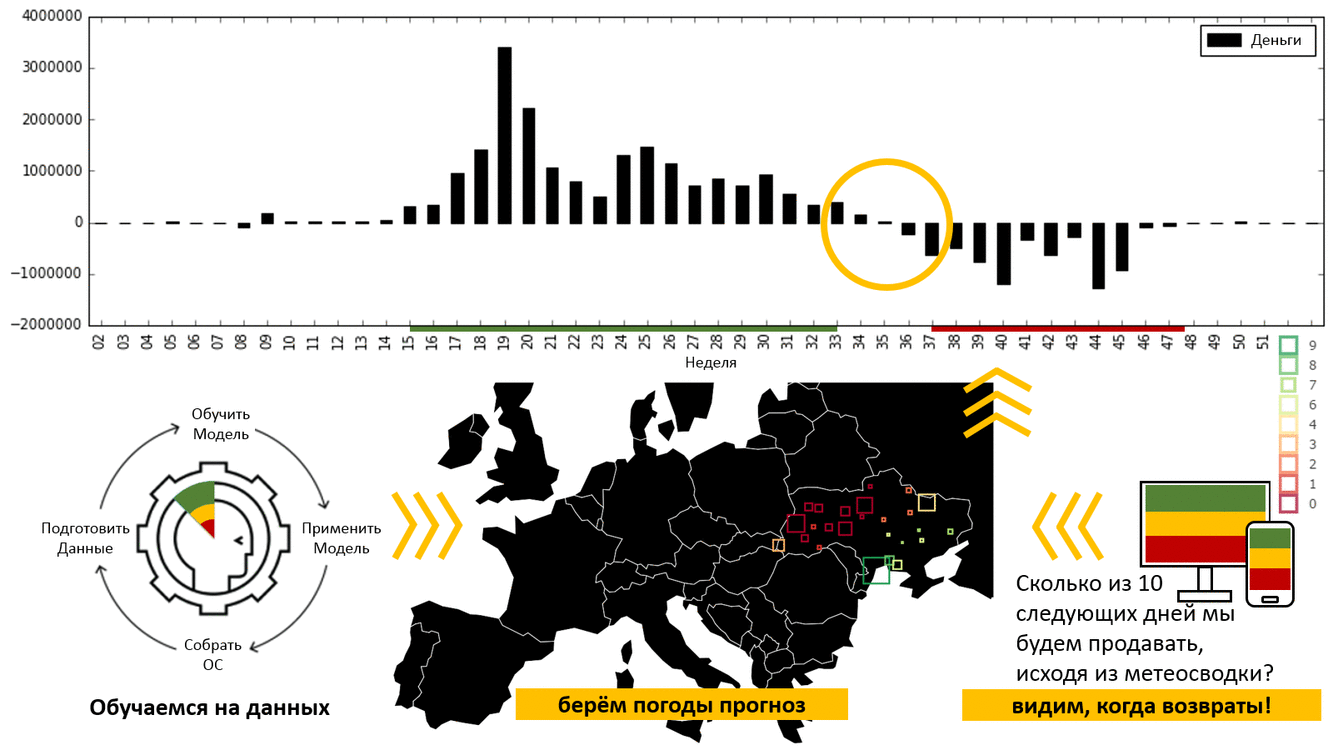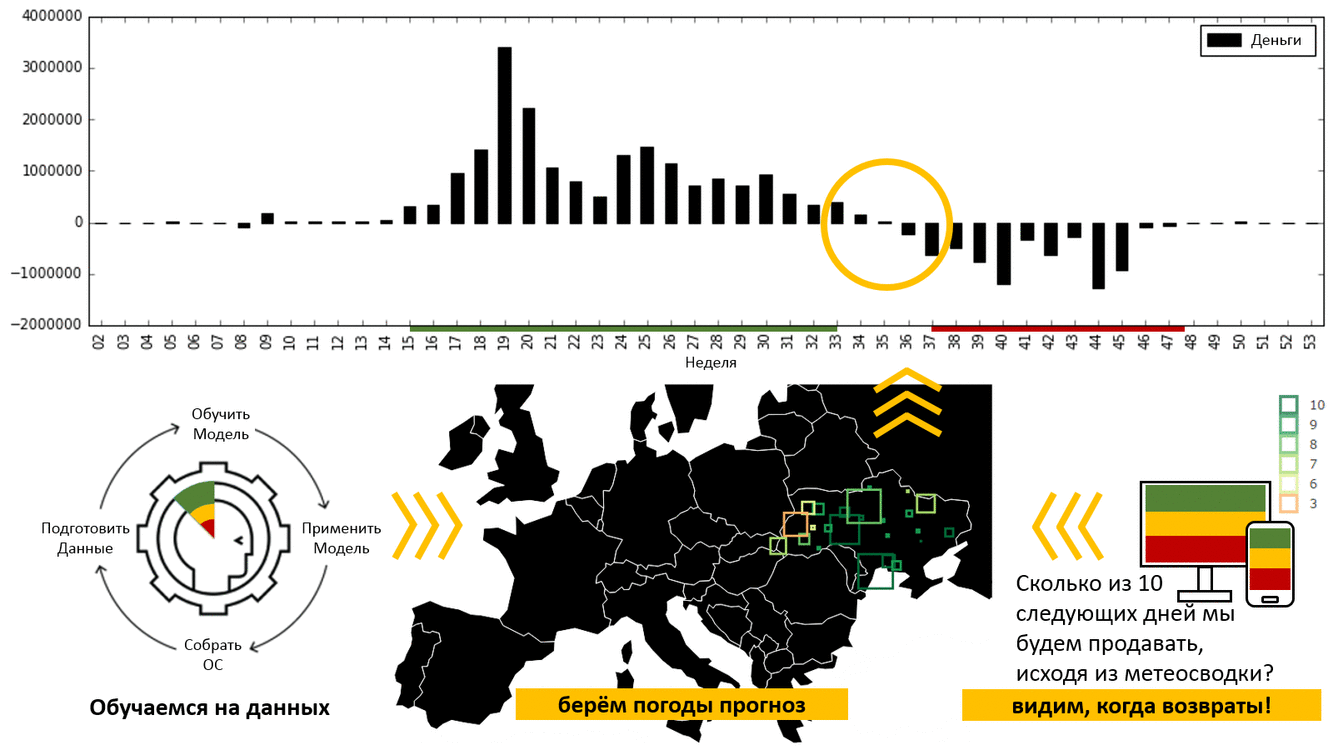
 Каждый должен делать свою работу качественно и в срок. Допустим, вам нужно сделать веб-сервис классификации картинок на базе обученной нейронной сети с помощью библиотеки
Каждый должен делать свою работу качественно и в срок. Допустим, вам нужно сделать веб-сервис классификации картинок на базе обученной нейронной сети с помощью библиотеки  Эта статья представляет собой адаптацию разделов 2 и 3 из главы 9 моей книги «
Эта статья представляет собой адаптацию разделов 2 и 3 из главы 9 моей книги «