
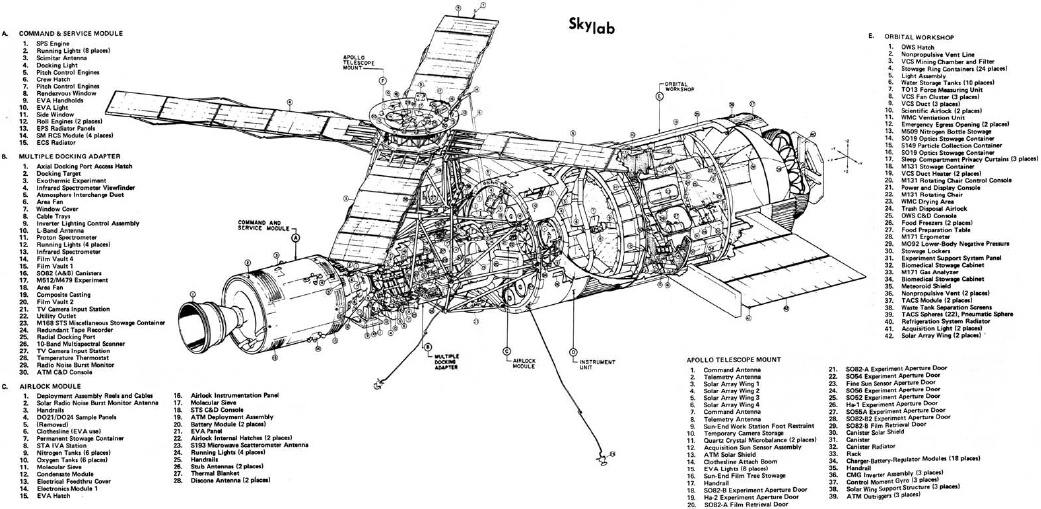
В 1973 году американцы вывели на орбиту огромную хреновину на 77 тонн. Называлась эта штука Skylab. У нас она особо известна тем, что есть как минимум полдюжины конспирологических теорий, зачем она действительно была нужна. Самая простая – что там был шлюз для корабля пришельцев.
Но это не важно. Важно то, что в 1979 году её хотели затопить в океане, но вместо этого затопили на паре австралийских ферм. Местные в разных поселениях с большим удовольствием смаковали эту историю, и поэтому я не мог не раскопать детали. И, конечно же, там обнаружился целый цирк.
Картинка Университета Флиндерса (Южная Австралия, апрель 2012)
Итак, для начала NASA не знала, куда именно грохнется Скайлаб. Уточнённый прогноз предполагал, что она развалится в атмосфере и даст кучу осколков с покрытием 7400 километров по вектору входа в атмосферу. Надо отметить, что вся эта история происходила в 1978-м году.
А 1978 год особо примечателен тем, что в Канаду уже упал наш советский спутник. Так в Канаде появилось новое месторождение урана. Причём сразу обогащённого.
В результате прогноз попадания в хотя бы одного человека 1 к 152 воспринимался примерно так же как фраза капитана пассажирского самолёта «Уважаемые пассажиры, пожалуйста, сохраняйте спокойствие».
Но это не важно. Важно то, что в 1979 году её хотели затопить в океане, но вместо этого затопили на паре австралийских ферм. Местные в разных поселениях с большим удовольствием смаковали эту историю, и поэтому я не мог не раскопать детали. И, конечно же, там обнаружился целый цирк.
Картинка Университета Флиндерса (Южная Австралия, апрель 2012)
Итак, для начала NASA не знала, куда именно грохнется Скайлаб. Уточнённый прогноз предполагал, что она развалится в атмосфере и даст кучу осколков с покрытием 7400 километров по вектору входа в атмосферу. Надо отметить, что вся эта история происходила в 1978-м году.
А 1978 год особо примечателен тем, что в Канаду уже упал наш советский спутник. Так в Канаде появилось новое месторождение урана. Причём сразу обогащённого.
В результате прогноз попадания в хотя бы одного человека 1 к 152 воспринимался примерно так же как фраза капитана пассажирского самолёта «Уважаемые пассажиры, пожалуйста, сохраняйте спокойствие».
 На данный момент существует много компаний нуждающихся в системах аналитики, но дороговизна и чрезмерная сложность данного ПО в большинстве случаев вынуждает отказаться от идеи построения собственной аналитической системы в пользу простого всем известного экселя. Также дополнительные расходы на обучение сотрудников, поддерживание дорогих систем хранения данных и т.д. И тут на помощь могут прийти Open Source решения — их не так много, но есть очень достойное ПО, одним из которых которых является RapidMiner.
На данный момент существует много компаний нуждающихся в системах аналитики, но дороговизна и чрезмерная сложность данного ПО в большинстве случаев вынуждает отказаться от идеи построения собственной аналитической системы в пользу простого всем известного экселя. Также дополнительные расходы на обучение сотрудников, поддерживание дорогих систем хранения данных и т.д. И тут на помощь могут прийти Open Source решения — их не так много, но есть очень достойное ПО, одним из которых которых является RapidMiner.






 Я закончил августовскую сессию курса
Я закончил августовскую сессию курса 
{kind=link}