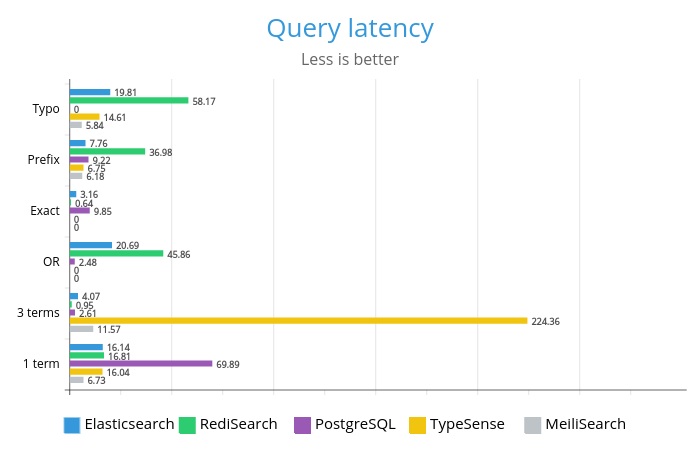
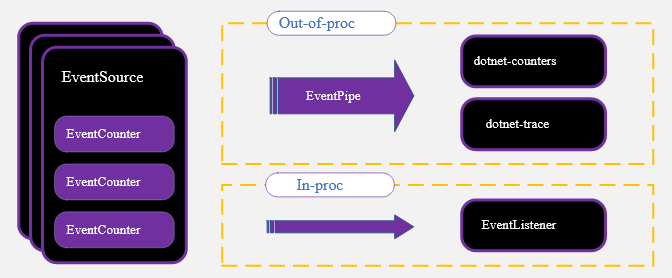
Предисловие: этот пост представляет собой очень длинный перечень мыслей и проблем, возникавших у меня за годы работы; также в нём рассматриваются некоторые из аргументов, которые мне часто говорили. В посте выражено моё мнение, сформировавшееся у меня в процессе разработки игр на Rust в течение многих тысяч часов на протяжении многих лет и после множества завершённых игр. Это не хвастовство и не показатель успеха, я просто хочу сказать, что вложил достаточно много усилий в Rust; здесь не получится сказать «когда наберёшься опыта, тебе всё станет понятно».
Пост не будет ни научной оценкой, ни A/B-исследованием. Это моё личное мнение после разработки игр на Rust маленькой инди-командой (два человека) в попытках заработать достаточно денег, чтобы финансировать процесс. Мы не одни из тех разработчиков с бесконечными финансами от инвестора и многолетним запасом времени. Если вы находитесь в этой категории и получаете удовольствие от многолетней разработки систем, то всё написанное ниже к вам не относится. Я рассматриваю всё с такой точки зрения: «Мне хочется создать игру максимум за 3-12 месяцев, чтобы люди могли сыграть в неё, а я — немного заработать». Статья не написана с точки зрения «Я хочу изучить Rust, а разработка игр — это весело», хотя это и вполне нормальная цель; просто она никак не согласуется с тем, чего хотим мы — заниматься разработкой игр коммерчески успешным и самодостаточным образом.
Мы выпустили несколько игр на Rust, Godot, Unity и Unreal Engine, и многие люди сыграли в них в Steam. Мы создали с нуля собственный игровой 2D-движок с простым рендерером, а также в течение нескольких лет использовали Bevy и Macroquad во многих проектах, некоторые из которых были очень нетривиальными. Кроме того, я бэкенд-разработчик на полную ставку и пишу код на Rust. Этот пост — не какое-то поверхностное мнение после изучения нескольких туториалов или разработки небольшой игры для геймджема. За три с лишним года мы написали сильно больше ста тысяч строк кода на Rust.
Задача этого поста — развеять популярные и часто повторяемые аргументы. Но это всё-таки субъективное мнение; по большей части я написал пост, чтобы не объяснять снова и снова одно и то же. Пусть это будет справочный материал о том, почему мы, скорее всего, откажемся от Rust как от инструмента для разработки игр. Мы ни в коем случае не планируем прекращать создавать игры, просто не будем делать это на Rust.