

Сегодня быть онлайн — это привычное состояние для многих людей. Все мы покупаем, общаемся, читаем статьи, ищем информацию на разные темы. Сеть соединяет нас со всем миром, но прежде всего, она соединяет людей. Я сам пользуюсь интернетом уже 20 лет, и мои отношения с ним изменились восемь лет назад, когда я стал веб-разработчиком.
Разработчики соединяют людей.
Разработчики помогают людям.
Разработчики дают людям возможности.
Разработчики могут создать сеть для всех, но эту способность необходимо использовать ответственно. В конце концов, важно создавать вещи, которые помогают людям и расширяют их возможности. В этой статье я хочу рассказать о том, как HTTP-заголовки могут помочь вам создавать лучшие продукты для лучшей работы всех пользователей в интернете.
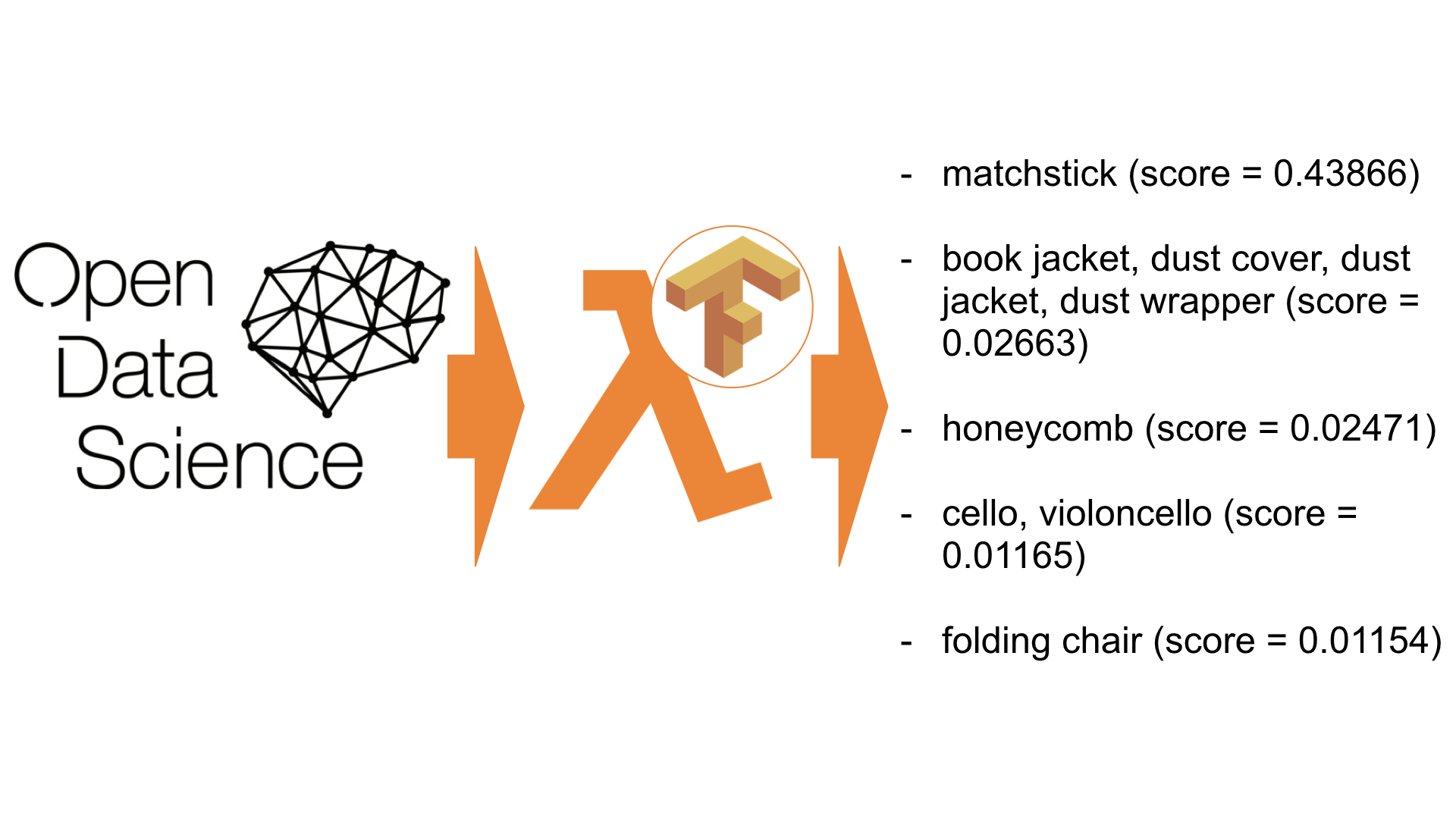

 Данное занятие мы посвятим методам обучения без учителя (unsupervised learning), в частности методу главных компонент (PCA — principal component analysis) и кластеризации. Вы узнаете, зачем снижать размерность в данных, как это делать и какие есть способы группирования схожих наблюдений в данных.
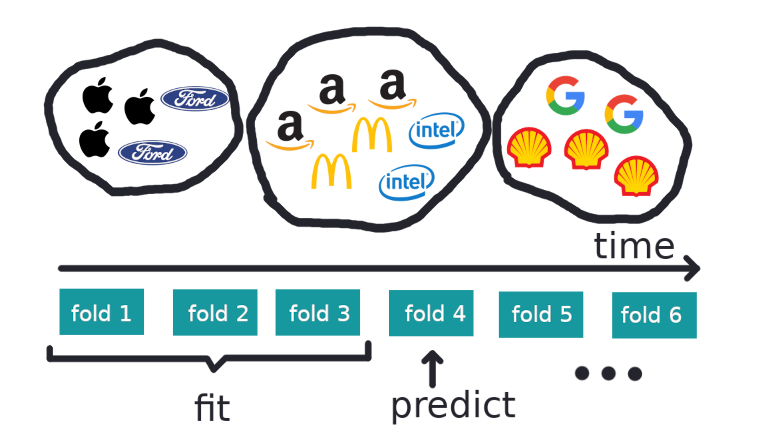
Данное занятие мы посвятим методам обучения без учителя (unsupervised learning), в частности методу главных компонент (PCA — principal component analysis) и кластеризации. Вы узнаете, зачем снижать размерность в данных, как это делать и какие есть способы группирования схожих наблюдений в данных. Посмотрим на то, как с ними работать в Python, какие возможные методы и модели можно использовать для прогнозирования; что такое двойное и тройное экспоненциальное взвешивание; что делать, если стационарность — это не про вас; как построить SARIMA и не умереть; и как прогнозировать xgboost-ом. И всё это будем применять к примеру из суровой реальности.
Посмотрим на то, как с ними работать в Python, какие возможные методы и модели можно использовать для прогнозирования; что такое двойное и тройное экспоненциальное взвешивание; что делать, если стационарность — это не про вас; как построить SARIMA и не умереть; и как прогнозировать xgboost-ом. И всё это будем применять к примеру из суровой реальности. 







 Здравствуйте, коллеги! Это блог открытой русскоговорящей
Здравствуйте, коллеги! Это блог открытой русскоговорящей