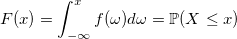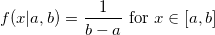Open Source проекты с каждым днём набирают всё большие обороты, появляются новые, активно развиваются популярные.
Такие проекты как Bootstrap, Angular.js, Elasticsearch, Symfony Framework, Swift и многие другие привлекают новых разработчиков, их сообщество растёт. Всё это даёт огромный рост проектам, а самим разработчикам интересно поучаствовать в разработке чего-то, чем пользуется весь мир.
Я, как и многие другие программисты, не устоял и также время от времени участвую в разработке Open Source проектов, в основном на PHP. Но когда я начинал, я столкнулся с проблемой — я не знал, как правильно организовать процесс «контрибьютинга», с чего начать, как сделать так, чтобы мой Pull Request рассмотрели и т.д.
Всем начинающим «контрибьютерам», которые столкнулись с похожим проблемами, добро пожаловать под кат.

Такие проекты как Bootstrap, Angular.js, Elasticsearch, Symfony Framework, Swift и многие другие привлекают новых разработчиков, их сообщество растёт. Всё это даёт огромный рост проектам, а самим разработчикам интересно поучаствовать в разработке чего-то, чем пользуется весь мир.
Я, как и многие другие программисты, не устоял и также время от времени участвую в разработке Open Source проектов, в основном на PHP. Но когда я начинал, я столкнулся с проблемой — я не знал, как правильно организовать процесс «контрибьютинга», с чего начать, как сделать так, чтобы мой Pull Request рассмотрели и т.д.
Всем начинающим «контрибьютерам», которые столкнулись с похожим проблемами, добро пожаловать под кат.
 Существует достаточно много цифровых сертификатов, каждый из которых служит для своих целей. Самые распространенный тип сертификатов это естественно SSL сертификаты, которые также имеют несколько подвидов. Также существуют Code Signing сертификаты, Website Anti Malware Scanner сертификаты и Unified Communications сертификаты.
Существует достаточно много цифровых сертификатов, каждый из которых служит для своих целей. Самые распространенный тип сертификатов это естественно SSL сертификаты, которые также имеют несколько подвидов. Также существуют Code Signing сертификаты, Website Anti Malware Scanner сертификаты и Unified Communications сертификаты.