Вопрос безопасности всегда будет актуальным, особенно в Сети. По этому, чтобы в один прекрасный день не получить на своем ресурсе такую картинку нужно уметь проверять на предмет уязвимостей себя самого.
Под катом — краткий обзор и типовые примеры использования бесплатных утилит, которые помогут (а точнее уже во всю помогают) хакерам, администраторам, разработчикам, тестировщикам проверить свои ресурсы конкурентов в автоматизированном режиме.
У статьи довольно низкий порог вхождения для понимания и использования, по этому, надеюсь, придется по душе многим. Раскрывается лишь базовый функционал программ.
Иногда проснувшись утром отчетливо понимаешь — что то не так. Хотя ты побрился и даже ни разу не порезался, кофе не выкипел, на улице солнечное утро, добрался до работы быстро и без приключений, вроде бы все хорошо, а все равно что то не так. Но войдя в офис ты видишь общую панику, истеричные вопли, о том, что все пропало и «весь офисный планктон» умрет, а ты находишься во главе тех кто погибнет.
Оказывается ночью отказали файловый и почтовый серверы. И тут понимаешь, что не с проста утро началось так хорошо. Работы предстоит достаточно, но данные надежно сохранены, ибо ты позаботился об их резервном копировании.
Сложные сети требуют комплексного подхода к управлению. Если вся сеть состоит из десятка свичей и управляется одним инженером, то для поддержания ее в рабочем состоянии достаточно набота простейших скриптов, нескольких электронных таблиц и любой примитивной системы мониторинга. В более крупных сетях, сотоящих из разношерсного оборудования разных вендоров, поддерживаемого десятками инженеров, разбросанных по разным городам и странам, начинают вылезать весьма специфичные проблемы: ворох самописных скриптов становится абсолютно неуправляемым и непредсказуемым в поведении, на интеграцию различных систем управления между собой уходит больше ресурсов, чем на разработку с нуля и установку и так далее. В результате быстро приходит понимание, что решать задачу системы управления сложной сетью можно только комплексно.
Еще в начале 80-х комитет ISO выделил основные компоненты системы управления сетью. Модель получила название FCAPS. По версии ISO, для успешного управления сетью надо уметь управлять отказами (F), конфигурацией оборудования и сервисов (C ), собирать и обрабатывать статистику по потреблению услуг (A), оценивать производительность (P) и централизованно управлять безопасностью (S). Прошедшие три десятка лет не добавили ничего принципиально нового, и все задачи управления сетью так или иначе прыгают вокруг основных составляющих.
Коммерческие комплексы подобного рода весьма дороги и далеко не безгрешны, а среди open-source систем присутсвовал явный и откровенный пробел, что просто подталкивало на разработку своего велосипеда. В результате обобщения нашего личного опыта по созданию и эксплуатации сетей, после долгих проб и ошибок появилась система NOC
Маленькое расширение для FCGI::ProcManager, позволяющее обращаться к менеджеру fcgi процессов. Для связи сторонней программы с менеджером используется сокет.
Подводные камни
Модуль FCGI::ProcManager используется для порождения обработчиков входящих запросов. Текущий процесс является менеджером. Со старта он порождает обработчиков (n_processes штук), далее он поддерживает их количество, следя за погибшими в бою. Для этих целей он использует wait. Тут и кроется проблемка. После того, как запущены потоки, менеджер, вызывая wait, блокируется. Достучаться до него можно только через сигналы. Исполнять в обработчике сигнала код нужно с умом и аккуратно, гонять там говнокод — нехорошо. А значит необходимо наладить другой канал связи.
Представим, что у нас есть сайт, на который регулярно дают ссылки с хабра.
Нам нужно подготовить его к резким всплескам посещаемости. Как это сделать?
С версии 0.8.46 в nginx появились опции, позволяющие легко и просто настроить прозрачное кэширование для анонимных пользователей.
Для работы этой схемы от сайта требуется очень мало: достаточно лишь не начинать сессию, то есть не отправлять сессионную куку, без явной на то необходимости. Редкий сайт нельзя довести до такого состояния, а значит большинство сайтов можно защитить от резких всплесков посещаемости с помощью nginx с минимальными затратами сил и времени.
Каким бы хорошим не был Python, есть у него проблема известная все разработчикам — скорость. На эту тему было написано множество статей, в том числе и наХабре.
1. Комбинируется p2p технология с современными алгоритмами репликации данных, чтобы обеспечить пользователя с приватной и распределённой файловой системой используя его же оборудование.
2. P2P слой позволяет связывать два или более компьюторов или столько сколько позволяет сеть или настройки файрвола. Это означает что AeroFS будет работать в Интернете, в локальной сети и в вашем офисе.
3. Т.к AeroFS полностью распределённая система, если сервера AeroFS будут в дауне то у пользователя все будет работать.
До сих пор на хабре еще никто не упоминал о такой удобной подсистеме ядра linux, как inotify и использовании ее в автоматизации работы системного администратора. Хотелось бы восполнить этот пробел.
Что такое inotify
Inotify — это подсистема ядра Linux, которая позволяет получать уведомления об изменениях в файловой системе. Т.е. простыми словами — эта штука дает нам информацию о создании или изменении любого файла или директории в используемой файловой системе.
Inotify появилась в ядре аж в версии 2.6.13 и прошла проверку временем. Для ее использования написано несколько утилит, работу с одной из которых мы и рассмотрим.
Забавно, но когда программист разрабатывает какой-либо продукт, он редко задумывается над вопросом могут ли на одну кнопку в один момент времени нажать одновременно 2000 человек. А зря. Оказывается могут. Как ни странно но большинство движков, написанных такими программистами, очень плохо ведут себя под большими нагрузками. Кто бы подумал, а всего один лишний INSERT, не проставленный index, или кривая рекурсивная функция могут поднять load averages чуть ли не на порядок.
В этой статье я опишу как мы, разработчики проекта, сумели выжать из одного сервера с Pentium 4 HT / 512Mb RAM, максимум, держа одновременно 700+ пользователей на форуме и 120,000 на трекере. Да, проект этот — торрент трекер. Предлагаю сразу оставить в стороне разговоры о копирайтах и правах, мне это не интересно, что действительно интересно — это HighLoad.
Вы PM. Как узнать – готова ли вёрстка к реальному использованию?
Вы заказчик. Как убедиться, что работа выполнена качественно?
Как оценить качество вёрстки?
Когда я стал тим-лидом, а позже PM, передо мной стала задача проверять вёрстку наших проектов. Нужно было выработать формальные, легкопроверяемые критерии, соответствие кода которым, должно было давать некую гарантию, что не будет факапов и ни клиент, ни программеры не сказажут потом “WTF?”.
Клиенту неважно насколько красив ваш код, но ему важен результат. Качественный код нужен фирме, т.к. он надёжней и в будущем его будет легче поддерживать.
Требования должны были быть такие, что соблюсти их легче, создавая качественную вёрстку, а не говнокод. Я составлял такой чек-лист в течении полутора лет. За последние полгода в него не добавилось ничего. Значит самое главное учтено.
Итак что же это за список?
Краткая версия теперь доступна на html5checklist.com (github), где можно вносить pull-request'ы.
История обновлений:
2015/08/11: Актуализировал рекомендации по оптимизации скорости загрузки. Добавил требование поддержки Retina. Дополнил «19. Мелочи» требованием что изображения должны масштабироваться в зависимости от размера окна.
2015/08/10: актуализирован список исключений для CSSLint
2015/07/29: актуализирован пункт №13 «плохо»/«хорошо»
2015/04/08: добавлено требование использования препроцессоров и рекомендация использования систем сборки
2013/04/25: добавлены анализаторами качества кода: CSSLint и JSHint, указан сайт подбора css font stack (спасибо @fliptheweb), мелкие уточнения (работу интерактивных элементов страницы, что не пропадает фон на высоких разрешениях, не должно быть пустых презентационных блоков, при проверках контента — пробовать удалять заголовки, менять местами блоки)
2013/04/24: добавил пункт об минимизации каскада (БЭМ-техники, MCSS, SMACSS), необходимости вписывания в экран моб. устройства, заменил ссылку на проверочный текст отображения стандартного html на код с normalize.css, поправил пример где в рекомендации встречался длинный каскад, упомянул про Opera на Presto и новый уровень семантики — в именах классов BEM.
2012/04/12: отсортировал пункты проверки в порядке важности, выделил главные, дополнил статью подробностями
2011/07/19: добавлено про повышение надёжности вёрстки благодаря html5-тэгам, про необходимость favicon/apple-touch-icon, отсутствие багов при ресайзе textarea
2011/06/15: добавил пояснения какие ошибки валидации допустимы, рассказал про отсутствие официальной кнопки «HTML5 Valid» и про официальное лого HTML5 на сайте.
Иногда возникает необходимость написать какой-то простенький TCP либо UDP сервер. Например, сейчас у меня вполне успешно в production трудится собственная реализация DHCP (существующие не подходят из-за специфики). Обычно это делается просто — один цикл, слушаем сокет — и вуаля! Но не всегда «тупой» подход оправдан (нужно что-то более сложное — работа в несколько потоков, например), а использование тяжелой артиллерии слишком затратно.
Обзор свободно доступных и бесплатных IP АТС: Asterisk, FreeSWITCH, SipXecs, Yate. Приводятся преимущества и недостатки, сравнительный анализ функциональности и сфер применения. Делается вывод о том, что все продукты можно сочетать друг с другом.
Некоторое время назад ко мне обратился товарищ из «Открытых Систем» и попросил сделать обзор открытых IP АТС. Так как он обратился не только ко мне, а еще и к другим экспертам IP телефонии, то в результате в журнал попала компиляция, в которой мало осталось от моего оригинального обзора. Публикую его целиком на Хабре.
Вначале будет теоретическая вставка, для тех, кто не совсем в теме. Если будет скучно — просто пропустите ее! Приятного чтения! А чтобы лучше читалось, главы сопровождаются музыкальными подарками (настоятельно рекомендую наушники :-)
Поехали!
Теория
PBX (Private Branch Exhange) — английский термин, обозначающий офисную телефонную станцию, которая обеспечивает установление, поддержание и разрыв соединений между аппаратами, то есть коммутацию. PBX позволяет разделять ограниченные ресурсы (городские линии и номера) между неограниченным числом внутренних пользователей, при помощи таких телефонных функций, как внутренний номерной план, перевод звонков, постановка на удержание, и других.
Именно поэтому PBX система необходима любой организации — она позволяет эффективно организовать телефонную связь на предприятии (ну, пока еще нужна ;-)
Недавно мне потребовалось перенести несколько сайтов различных клиентов на нормальный выделенный сервер (не виртуальный). Я давно выбирал, где лучше арендовать сервер и выбором стала немецкая компания Hetzner Online и ее тарифный план DS 3000 (AMD Athlon 64 X2 4200+/2Gb DDR/2x160Gb HDD — как выяснилось потом — на сервере оказалось два винчестера по 320Гб).
Но мне не хотелось всех размещать на одном сервере. Поэтому было решено сделать виртуальные машины на базе технологии XEN (к тому же в придачу к серверу на ТП DS 3000 Hetzner Online бесплатно выдает 6 IP-адресов, которые очень удобно будут смотреться для отдельных проектов). В Сети можно найти много информации по теме настройки и самого XEN'а на Debian'e и настройки роутинга на нем, поднятии виртуалок на LVM (lvm дает большее быстродействие, чем виртуалки на базе image-файлов), даже в вики самой фирмы была информация об этом (но на немецком — Google Translate нам в помощь). Но. Было одно «Но». Она вся была разрозненная и кусками. Я нигде не смог найти толкового пошагового руководства для настройки «от» и «до».
Недавно столкнулся с неприятной ситуацией — почтовый сервер попал в спам-листы. Дыру быстро нашли и залатали, но компания Oracle уже занесла наш сервер в свой черный список, причем блокировали нас ещё на стадии соединения.
Возник вопрос — куда писать? На сайте была только форма для клиентов, support@oracle.com предназначался для них же.
После недолгих раздумий, появилась мысль — а нет ли стандарта, определяющего почтовые адреса по которым надо писать в таком случае? Оказалось, что есть и описан он в RFC 2142.
Самое интересное содержится в таблицах, которые приведены ниже.
Поступила задача наладить автоматическое распознание текста с фотографий, т.е. пользователь при загрузке фотогографии на сервер, получает еще и распознанный с нее текст. Сказано — сделано. Было найдено хорошее бесплатное консольное решение — cuneiform.
Несколькими постами раньше уже были темы об использовании SMS уведомлений в Nagios. Сегодня я расскажу ещё об одном способе уведомлений. Нижеописанный способ несколько надёжнее описанных ранее, но и требует некоторых денежных вложений. Он полезен в том случае, когда какие-то из уведомлений являются критически важными (как, например, выход кондиционера из строя или увеличение влажности).
Способ заключается использовании мобильного телефона с корпоративным тарифом (дабы деньги на телефоне не кончились неожиданно).
Физически подключается к серверу по bluetooth, com или usb. На уровне ПО мы будем использовать два скрипта: один из них умеет отправлять sms, второй проверяет статус мобильной сети. Если мобильная сеть недоступна, то nagios отправляет сообщение на email.
Оба скрипта написаны на python и используют библиотеку gammu для подключения к телефону.
Добрый день. Недавно меня заинтересовал модуль ngx_http_gzip_static_module, и я решил погонять мой домашний сервер немного с разными настройками сжатия nginx, чтобы убедится, действительно ли современные процессоры настолько быстрые, что можно ставить сжатие в 9-тку и не париться. В качестве подопытного файла выступала слитая главная страница lenta.ru – 170кб. Во время тестирования обнаружилась интересная особенность, которая изменила мои взгляды на выбор количества процессов nginx.
Три года назад у меня была интересная задача. Необходимо было собрать платформу, объединявшую несколько стоек с серверами в единое целое, для динамического распределения ресурсов между сайтами написанным для LAMP платформы. Причем так, чтоб вмешательство в код сайтов было минимальным, а еще лучше — вообще отсутствовало.
При этом никаких дорогих решений вроде Cisco Content Switch или дисковой полки с оптоволокном использовать нельзя — не хватало бюджета.
А кроме того, разумеется, в случае выхода одного из серверов из строя — это не должно было влиять на работу платформы.
Узнать, как отмасштабировать Ваше приложение, не имея при этом никакого опыта, — это очень нелегко. Сейчас есть много сайтов, посвященных этим вопросам, но, к сожалению, не существует решения, которое подходит для всех случаев. Вам по-прежнему необходимо самому находить решения, которые подойдут под Ваши требования. Так же, как и мне.
Несколько лет назад ко мне пришел мой босс и сказал: «У нас есть новый проект для тебя. Это перенос сайта, который уже имеет 1 миллион посетителей в месяц. Тебенеобходимо его перенести и убедиться, что посещаемость может вырасти в будущем без всяких проблем.» Я уже был опытным программистом, но не имел никакого опыта в области масштабируемости. И мне пришлось познавать масштабируемость трудным путем.



 Каким бы хорошим не был Python, есть у него проблема известная все разработчикам — скорость. На эту тему было написано множество
Каким бы хорошим не был Python, есть у него проблема известная все разработчикам — скорость. На эту тему было написано множество 
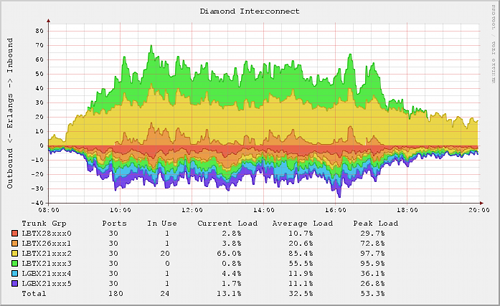
 Вы PM. Как узнать – готова ли вёрстка к реальному использованию?
Вы PM. Как узнать – готова ли вёрстка к реальному использованию?
 Добрый день. Недавно меня заинтересовал модуль ngx_http_gzip_static_module, и я решил погонять мой домашний сервер немного с разными настройками сжатия nginx, чтобы убедится, действительно ли современные процессоры настолько быстрые, что можно ставить сжатие в 9-тку и не париться. В качестве подопытного файла выступала слитая главная страница lenta.ru – 170кб. Во время тестирования обнаружилась интересная особенность, которая изменила мои взгляды на выбор количества процессов nginx.
Добрый день. Недавно меня заинтересовал модуль ngx_http_gzip_static_module, и я решил погонять мой домашний сервер немного с разными настройками сжатия nginx, чтобы убедится, действительно ли современные процессоры настолько быстрые, что можно ставить сжатие в 9-тку и не париться. В качестве подопытного файла выступала слитая главная страница lenta.ru – 170кб. Во время тестирования обнаружилась интересная особенность, которая изменила мои взгляды на выбор количества процессов nginx.