
Данная подборка позволит вам разобраться с плюсами и минусами дистанционной работы, оценить затраты и возможную экономию, познакомиться с опытом коллег и взглянуть на целый спектр компаний, команды которых работают дистанционно.

User



Я с удивлением обнаружил, что многие разработчики, даже давно использующие postgresql, не понимают оконные функции, считая их какой-то особой магией для избранных. Ну или в лучшем случае «копипастят» со StackOverflow выражения типа «row_number() OVER ()», не вдаваясь в детали. А ведь оконные функции — полезнейший функционал PostgreSQL.
Попробую по-простому объяснить, как можно их использовать.
 Ты просто-напросто ненавидишь Git? Ты абсолютно счастлив с Mercurial (или, фу, с Subversion), но раз в месяц тебе приходится отважно сталкиваться с Git, потому что каждый, даже его чертова собака, теперь использует GitHub? Тебя терзают смутные подозрения, что половина всех команд Git на самом деле удалят всю твою работу навсегда, но ты не знаешь какие именно и не хочешь проводить три недели, углубляясь в документацию?
Ты просто-напросто ненавидишь Git? Ты абсолютно счастлив с Mercurial (или, фу, с Subversion), но раз в месяц тебе приходится отважно сталкиваться с Git, потому что каждый, даже его чертова собака, теперь использует GitHub? Тебя терзают смутные подозрения, что половина всех команд Git на самом деле удалят всю твою работу навсегда, но ты не знаешь какие именно и не хочешь проводить три недели, углубляясь в документацию?






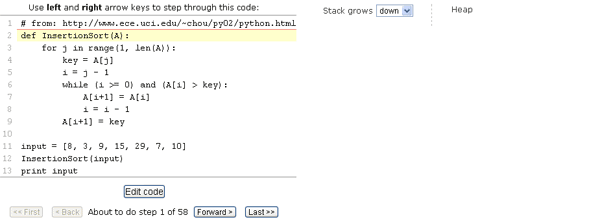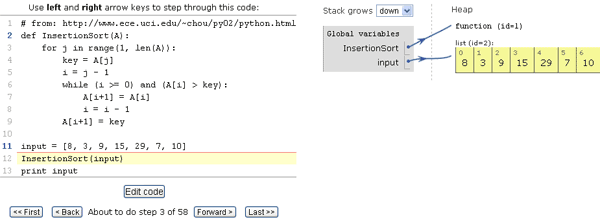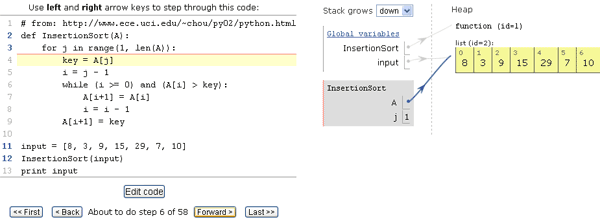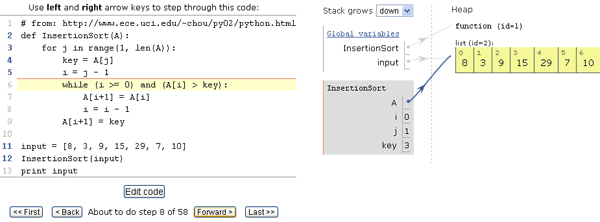
 Вчера, 25 августа, произошло важное для большого числа программистов событие: компания Intel выпустила новую версию программного комплекса Intel Parallel Studio XE — 2016, включающего в себя компиляторы Intel, библиотеки для повышения производительности, средства анализа и отладки программ, а также библиотеку Intel MPI и MPI инструментарий. Но это еще не вся радость. В новой «студии» к имевшей и ранее бесплатную версию библиотеке Intel Threading Building Blocks добавилось целых три продукта с community (то есть бесплатной) лицензией: новая библиотека Intel Data Acceleration Library, о которой мы только что писали, а также два очень полезных компонента: Intel Math Kernel Library и Intel Integrated Performance Primitives. Используйте на здоровье, какие-либо ограничения у бесплатных версий отсутствуют.
Вчера, 25 августа, произошло важное для большого числа программистов событие: компания Intel выпустила новую версию программного комплекса Intel Parallel Studio XE — 2016, включающего в себя компиляторы Intel, библиотеки для повышения производительности, средства анализа и отладки программ, а также библиотеку Intel MPI и MPI инструментарий. Но это еще не вся радость. В новой «студии» к имевшей и ранее бесплатную версию библиотеке Intel Threading Building Blocks добавилось целых три продукта с community (то есть бесплатной) лицензией: новая библиотека Intel Data Acceleration Library, о которой мы только что писали, а также два очень полезных компонента: Intel Math Kernel Library и Intel Integrated Performance Primitives. Используйте на здоровье, какие-либо ограничения у бесплатных версий отсутствуют.