Comments 178
Спасибо за статью, плюсанул вам в карму. Всегда интересно читать такие вещи.
Проблема не столько в несовершенстве оптимизатора (в конце концов, хинты всегда можно проставить), сколько в отстутствии реализации методов объединения, отличных от nested-loop (скажем, sort-merge или hash-join) — именно поэтому, в частности, не реализован full outer join.
В MariaDB, правда, есть подвижки с hash join.
В MariaDB, правда, есть подвижки с hash join.
Ну вот в сообществе PostgreSQL хинты считают несовершенством оптимизатора, и своя логика в этом есть.
Альтернативные методы объединения как раз и упираются в архитектурное несовершенство — там всё очень прибито гвоздями к nested loops.
Кстати, я забыл упомнянуть, что в MariaDB начали работу на оконными функциями, судя по коммитам.
Альтернативные методы объединения как раз и упираются в архитектурное несовершенство — там всё очень прибито гвоздями к nested loops.
Кстати, я забыл упомнянуть, что в MariaDB начали работу на оконными функциями, судя по коммитам.
Похожие публикацииЗабавно :)
>> Что нужно знать при миграции с MySQL на PostgreSQL? (56)
>> Миграция с mysql на postgresql (13)
>> Миграция данных с MySQL на PostgreSQL (6)
Не хватает: «Миграция с MySQL 5.1 на MySQL >= 5.2» :)
Я к тому, что знаю какая это боль (правда мой мозг старается забыть об этом, подробностей уже не вспомню).
В то время как, обновление Постгреса протекает почти незаметно для разработчиков.
Я к тому, что знаю какая это боль (правда мой мозг старается забыть об этом, подробностей уже не вспомню).
В то время как, обновление Постгреса протекает почти незаметно для разработчиков.
К сожалению, это не так. Обновление 9.3 -> 9.4 требовало переконвертации базы. Не супер сложный процесс, конечно, но ни разу не незаметный.
У меня это получалось сделать с деградацией в ридонли на 10 секунд. Ночью вполне ок.
Я к тому, что в случае с MySQL зачастую нужно переписывать софт, что может занять годы (!).
Эта тема была затронута в докладе яндекса о «построение кластеров». Правда там было о случае миграции с MySQL 3.x на 5.x.
Но, я, например, не видел чтобы возникали проблемы с софтом после миграции с 8.x на 9.x у постгреса. А мне приходилось этим заниматься.
Я к тому, что в случае с MySQL зачастую нужно переписывать софт, что может занять годы (!).
Эта тема была затронута в докладе яндекса о «построение кластеров». Правда там было о случае миграции с MySQL 3.x на 5.x.
Но, я, например, не видел чтобы возникали проблемы с софтом после миграции с 8.x на 9.x у постгреса. А мне приходилось этим заниматься.
9.1 -> 9.4 при штатной ежегодной остановке БД без проблем.
последний раз живого пользователя MyISAM я встречал лет пять назад.Похоже автор имеет дело только с проектами уровня «Github, Wikipedia, Google, Facebook, Twitter, LinkedIn, Alibaba, Taobao, Booking.com, AirBnB, Dropbox, Pinterest, GroupOn, Yelp».
Навалом известных бытовых cms-ок использует MyISAM.
Но проблема там в ДНК/Опыте авторов CMS а не MySQL
Нууу. Вы так говорите, как будто использование MyISAM это нечто сродни использованию php 1.0 :) Не все так плохо, для большинства бытовых цмс-ок ничего другого и не надо, а на достаточно серьезных сайтах у MyISAM-а вполне себе найдется целевое применение.
Т.е. движок конечно олдскульный, но далеко не мертвый.
Т.е. движок конечно олдскульный, но далеко не мертвый.
В CMSках — ровно до тех пор, пока не придётся вытаскивать базу из трёхмесячного дампа. Именно потому это и проблема.
На серьёзных сайтах, где MyISAM используют осознанно отказываясь от ACID, понимая стоимость — это совсем другой разговор.
Впрочем, на моей памяти, все эти случаи — это было временное хранилище данных между шагами в пайплайне.
На серьёзных сайтах, где MyISAM используют осознанно отказываясь от ACID, понимая стоимость — это совсем другой разговор.
Впрочем, на моей памяти, все эти случаи — это было временное хранилище данных между шагами в пайплайне.
В CMSках — ровно до тех пор, пока не придётся вытаскивать базу из трёхмесячного дампа. Именно потому это и проблема.В MyISAM нельзя делать бакапы чаще раза в 3 месяца?:)
Между прочим система бакапа (именно бакапа) в myisam нам больше нравится чем в innodb допустим. Скопирнул файлы таблиц и спокоен — у тебя актуальная версия в чистом и переносимом виде. Попробуйте проделать тот же фокус с innodb, особенно если у Вас 30гб база не бакапившаяся 3 месяца (сколько транзакций набежит?) и до кучи Вы переносите ее в другое окружение.
Не уверен, но возможно с включенной опцией innodb_file_per_table у вас получится перенести базу (таблицу) на другой сервер. Но вы должны понимать что это не самый правильный способ.
Там не всё так просто: нужно ещё shared tablespace переносить. То есть либо вы останавливаете сервер полностью и копируете datadir, либо пользуетесь утилитами горячего копирования (XtraBackup или MySQL Enterprise Backup), либо ручками переносите таблицы по одной при помощи transportable table spaces (доступны в 5.6+). XtraBackup или MySQL Enterprise Backup умеют копировать InnoDB таблицы поштучно.
myisam поддерживает fulltext поиск. Innodb только с версии 5.6.4, судя по документации. Поэтому еще куча кода осталось, где для всей cms используется innodb, а для поиска myisam
Вообще строго говоря подавляющее большинство этих CMS не завязаны на MyISAM и просто не указывают движок при построении схемы. А MyISAM всплывает при установки CMS на сервер за 15 руб/год настроенный и забытый в 200? году.
Я думаю, бытовые CMS вполне попадают в категорию «legacy», про который я и написал.
А сам MySQL, который хранит собственные системные таблицы в MyISAM, куда попадает?
Попадает в категорию legacy, потому что в 5.7 это уже не так. Да и в 5.6 уже не все системные таблицы в MyISAM.
Вот вы везде говорите про 5.7. Это про оракловый mysql имеете ввиду и серьезно думаете, что кто-то будет сейчас оракловой проприетарщиной пользоваться? А что в mariadb с этим? В какой версии есть нативный json, fts и таблицы не в myisam?
5.7 — это будущее. Актуальная стабильная версия 5.6.
Согласен. Кроме того, я немного облажался (ну, с кем не бывает). Я опирался на этот пост. Но вот в 5.7.8 я вижу, что какие-то таблицы уже в InnoDB, а какие-то ещё в MyISAM. Может они поправят это к релизу.
Но мой посыл был вообще не в этом, поэтому я не буду исправлять пост. Посыл заключается вот в чём: разработчикам приложений MyISAM сейчас ничем не интересна. Если вы сейчас, в 2015-м году подойдёте к любому разработчику высоконагруженных MySQL систем с вопросом «А вы используете MyISAM таблицы?», то он на вас очень странно посмотрит. Вот об этом речь, а не о том, что часть системных таблиц ещё в MyISAM. Это временно и в общем к делу не относится.
Но мой посыл был вообще не в этом, поэтому я не буду исправлять пост. Посыл заключается вот в чём: разработчикам приложений MyISAM сейчас ничем не интересна. Если вы сейчас, в 2015-м году подойдёте к любому разработчику высоконагруженных MySQL систем с вопросом «А вы используете MyISAM таблицы?», то он на вас очень странно посмотрит. Вот об этом речь, а не о том, что часть системных таблиц ещё в MyISAM. Это временно и в общем к делу не относится.
Может «высоконагруженных» тут важное слово? Хотя, помнится, в некоторых случаях MyISAM точно были шустрее.
Можете закидать меня тухлыми помидорами, конечно, но я использую MyISAM в нескольких местах. Оно весьма неплохо работает, когда вам нужно максимально компактно запихать на сервер много (100+ млн) строк фиксированной ширины (например, только int без null-полей). Оно очень шустрое в случае append-only нагрузки, и прекрасно подходит для данных, которые не жалко потерять. Масштабируется по ядрам тоже вполне нормально, если распределить по нескольким таблицам.
Раз уж на то пошло, это совсем разные движки хранения, и я не понимаю, как их можно соавнивать. InnoDB прекрасен для «веб» нагрузки, MyISAM хорошо подходит для хранения «лог»-таблиц или таблиц с фиксированной длиной одной записи.
Раз уж на то пошло, это совсем разные движки хранения, и я не понимаю, как их можно соавнивать. InnoDB прекрасен для «веб» нагрузки, MyISAM хорошо подходит для хранения «лог»-таблиц или таблиц с фиксированной длиной одной записи.
Насчет репликации. Я всё рассматриваю с практической точки зрения. В моей практике mysql не справился с объемом данных и пришлось мигриться на пг. Возможно, логическая реплика mysql несет определенные преимущества, но все это очень медленно, а другой нет.
а о каких объемах идет речь? При использовании mysql PK был задан?
Здесь тяжело давать конкретные рекомендации, ничего не зная о нагрузке и не видя метрик. В следующем посте я собирался предложить варианты и объяснить плюсы/минусы/подводные камни. В каких-то случаях DRBD вполне себе реализует физическую репликацию. В каких-то можно посмотреть на read-free репликацию в TokuDB. А в каких-то просто сервер не настроен грамотно.
Класс. Жду подобной статьи про «как не надо критиковать альтернативы git'у».
Почему то забыли о таком преимуществе MySQL как handler socket, который легко подключается и работает на ура. На сколько знаю ничего подобного для PostgreSQL нет.
Спасибо за здравую критику PostgreSQL-сообщества в статье.
Но мне хватило нескольких вещей, чтобы понять что MySQL не нужен:
1) Статья, которая показала всю дикость парсера запросов в MySQL: когда логически одинаковые запросы, написанные по-разному, выдают разные результаты. Результаты в статье были совершенно безумные.
2) Статья от бывшего разработчика из Percona (сейчас работающего в mail.ru), который довольно хорошо объяснил, что путь MySQL — это путь в никуда по сравнению с постгресом. Человек делал реплику в перконе, и сейчас кормится за счет своей экспертизы mysql. Думаю, ему можно верить.
3) Логическая репликация: она может сломаться в режиме statement-based, если разработчики сделают какие-то «неправильные» запросы с limit (поправьте если это уже не так). А row-based означает сильную деградацию в i/o.
Но мне хватило нескольких вещей, чтобы понять что MySQL не нужен:
1) Статья, которая показала всю дикость парсера запросов в MySQL: когда логически одинаковые запросы, написанные по-разному, выдают разные результаты. Результаты в статье были совершенно безумные.
2) Статья от бывшего разработчика из Percona (сейчас работающего в mail.ru), который довольно хорошо объяснил, что путь MySQL — это путь в никуда по сравнению с постгресом. Человек делал реплику в перконе, и сейчас кормится за счет своей экспертизы mysql. Думаю, ему можно верить.
3) Логическая репликация: она может сломаться в режиме statement-based, если разработчики сделают какие-то «неправильные» запросы с limit (поправьте если это уже не так). А row-based означает сильную деградацию в i/o.
> Логическая репликация: она может сломаться в режиме statement-based, если разработчики сделают какие-то «неправильные» запросы с limit (поправьте если это уже не так).
Это так и всегда будет так. В силу того, что некоторые запросы не гарантируют возвращение одного и того же результата при повторном выполнении. В любой базе.
> А row-based означает сильную деградацию в i/o.
А вот это не так. Точнее, было так в 5.5 для запросов вида UPDATE сто миллионов строк WHERE id=12345. В 5.6 для такого ввели опцию, позволяющую указать хотим ли мы записывать в лог все изменения или же только то, что изменилось.
Более того, иногда statement-based означает деградацию IO. Для запросов вида UPDATE IF… THEN… ELSE IF… и так много раз WHERE мы нашли всего одну строку.
Это так и всегда будет так. В силу того, что некоторые запросы не гарантируют возвращение одного и того же результата при повторном выполнении. В любой базе.
> А row-based означает сильную деградацию в i/o.
А вот это не так. Точнее, было так в 5.5 для запросов вида UPDATE сто миллионов строк WHERE id=12345. В 5.6 для такого ввели опцию, позволяющую указать хотим ли мы записывать в лог все изменения или же только то, что изменилось.
Более того, иногда statement-based означает деградацию IO. Для запросов вида UPDATE IF… THEN… ELSE IF… и так много раз WHERE мы нашли всего одну строку.
1) Статья…
2) Статья...
Дайте ссылки плз
К сожалению не смогу найти цитату и пруф, но слышал своими ушами от Павла Зайцева (на HighLoad++) замечание о том, что код в MySQL очень местами грязный и многие вещи сделаны очень велосипедно, поэтому многие нужные фичи невозможно реализовать без боязни сломать все остальное.
Да, это то самое legacy, но хотелось бы понять — сколько реально этого legacy там осталось?
В то же время где-то читал отзывы, что после покупки Oracle в MySQL начали появляться нормальные юнит-тесты и вообще стало более организованно все.
Можете прокомментировать свое отношение к качеству кода внутри MySQL?
Да, это то самое legacy, но хотелось бы понять — сколько реально этого legacy там осталось?
В то же время где-то читал отзывы, что после покупки Oracle в MySQL начали появляться нормальные юнит-тесты и вообще стало более организованно все.
Можете прокомментировать свое отношение к качеству кода внутри MySQL?
Видимо, Петра Зайцева, не Павла :)
По коду MySQL. Качество там очень неоднородно. Например, код InnoDB — самый красивый код, который я когда-либо видел. Настолько структурированного, документированного, да и просто последовательного стиля программирования.
А вот в самом сервере где как. Старый код ещё можно найти, и он ужасен. Новый код в оптимизаторе мне нравится — всё довольно красиво и модульно сделано, но переделывать ещё много. А в репликации наоборот — старый код неплох, новый ужасен — явный over-engineering.
По коду MySQL. Качество там очень неоднородно. Например, код InnoDB — самый красивый код, который я когда-либо видел. Настолько структурированного, документированного, да и просто последовательного стиля программирования.
А вот в самом сервере где как. Старый код ещё можно найти, и он ужасен. Новый код в оптимизаторе мне нравится — всё довольно красиво и модульно сделано, но переделывать ещё много. А в репликации наоборот — старый код неплох, новый ужасен — явный over-engineering.
Алексей, раз вы заговорили о красоте кода, не хотели бы поговорить в таком случае про зависимость между красотой кода и производительностью?
Я лично очень долгое время не любил InnoDB (и сейчас недолюбливаю, хотя многие проблемы уже исправлены, но осталось ещё очень много) из-за его очень непрозрачной работы в продакшен-режиме. Поясню: мы написали даже целую статью про «грабли» именно с InnoDB, которые мы собрали, и это далеко не полный список: habrahabr.ru/company/badoo/blog/197456 (см. секцию «InnoDB, MVCC и DELETE FROM: подводные камни»).
Этот самый замечательный «очень красивый» код зачастую игнорирует многие вопросы производительности, чего не наблюдается в MyISAM — например (все вопросы — риторические, на самом деле):
Вы говорите про красивый код, но недоговариваете про изначально не очень масштабируемую по ядрам архитектуру (как бы странно это не звучало). Да, конечно, InnoDB это MVCC, а MyISAM — это очень «тупой» движок хранения, но так в этом же и прелесть! MySQL всегда был интересен тем, что это очень тупая база данных, которая сделана весьма «по-хакерски» и за счёт этого работает очень быстро на простых запросах и жрать не просит. К тому же, она очень user-friendly и поддерживает много «фич», которые нарушают (или дополняют) стандарт SQL, но зато очень удобны в веб-разработке. Она легко держит пару тысяч установленных соединений, а также несколько тысяч коннектов/дисконнектов в секунду.
Я более, чем уверен, что код всего этого просто ужасен, но у этого всего был смысл — сделать базу максимально простой и удобной в эксплуатации, а не для разработки.
За счёт этого MySQL не так стыдно использовать при горизонтальном масштабировании — поскольку база всё равно ничего особо не умеет, то зачастую можно легко её расшардить на много (100+) серверов, не особо потеряв возможностях и производительности.
Резюмируя — я очень уважаю людей из перконы за то, что они делают, но странно слышать про красоту кода от ваших сотрудников. Какое отношение имеет красота кода к производительности или надежности? Очень часто самый быстро работающий код выглядит просто ужасно, и наоборот. Мне вот лично архитектурно намного больше нравится MyISAM, чем InnoDB — потому что первый можно хоть самому на коленке реализовать, а вот InnoDB порой удивляет своей внутренней сложностью и запутанностью. Иногда складывается ощущение, что InnoDB вообще создавался для того, чтобы запудрить мозг тому, кто его использует, чтобы он даже не пытался во всём этом разобраться, а просто использовал и слепо верил в то, что всё будет хорошо. Но вот иногда бывает нехорошо, и тогда становится очень ценным свойство прозрачности системы и простоты починки. С InnoDB, мягко говоря, всё очень сложно. Например, чтобы его забекапить, нельзя просто скопировать его файлы данных, даже с выключенного сервера. Хотелось бы иметь либо систему, в которой можно разобраться, либо систему без проблем с производительностью и удобством эксплуатации. Лично для меня очевидно, что второе — это что-то из области фантастики, поэтому системы должны быть прозрачными и чиниться с помощью «молотка и такой-то матери». Кстати, пример с репликацией очень хороший — репликация сделана по-тупому, и сейчас легко понять, почему она тормозит (или ломается), и что с этим делать. Я боюсь представить, что будет, когда в MySQL тоже появится физическая репликация. Какие действия нужно будет предпринимать, если всё-таки там что-то пойдет не так? А точно она никогда не будет отставать на одинаковом железе? А как будет реализован в такой схеме master-master?
В общем, я надеюсь, я донес основную мысль :). MySQL всегда мне нравился именно удобством эксплуатации, и хотелось бы, чтобы это оставалось приоритетом для разработчиков, а не какие-то другие вещи.
Я лично очень долгое время не любил InnoDB (и сейчас недолюбливаю, хотя многие проблемы уже исправлены, но осталось ещё очень много) из-за его очень непрозрачной работы в продакшен-режиме. Поясню: мы написали даже целую статью про «грабли» именно с InnoDB, которые мы собрали, и это далеко не полный список: habrahabr.ru/company/badoo/blog/197456 (см. секцию «InnoDB, MVCC и DELETE FROM: подводные камни»).
Этот самый замечательный «очень красивый» код зачастую игнорирует многие вопросы производительности, чего не наблюдается в MyISAM — например (все вопросы — риторические, на самом деле):
- Зачем при создании/удалении временных таблиц нужно синкаться на диск?
- Почему нужно пуржить удаленные записи в один поток, а давать удалять в несколько? Это приводит к тому, что при интенсивном удалении из таблиц легко получить неустранимый без ручного вмешательства 100% CPU usage
- При каких условиях начинает работать адаптивный hash-table? Зачем он нужен? Создается ли он для вторичных индексов? Когда? Почему?
- Зачем нужно занимать такое количество места на диске и в памяти по сравнению с MyISAM?
- Зачем брать один супер-большой лок при удалении таблицы перед выполнением unlink(), который не дает выполняться никаким другим транзакциям, даже если они не обращаются к этой таблице?
- Почему рестарт сервера с использованием InnoDB может занимать десятки минут, а с MyISAM время измеряется в десятках секунд?
- Зачем нужно лочить таблицу целиком, если удаляются или обновляются почти все строки? Зачем нужно было лочить на запись по одной строке за раз, когда делается UPDATE/DELETE с использованием WHERE без индекса (это давало совершенно ужасную производительность при удалении из множества тредов)? Оба решения плохие в плане производительности!
Вы говорите про красивый код, но недоговариваете про изначально не очень масштабируемую по ядрам архитектуру (как бы странно это не звучало). Да, конечно, InnoDB это MVCC, а MyISAM — это очень «тупой» движок хранения, но так в этом же и прелесть! MySQL всегда был интересен тем, что это очень тупая база данных, которая сделана весьма «по-хакерски» и за счёт этого работает очень быстро на простых запросах и жрать не просит. К тому же, она очень user-friendly и поддерживает много «фич», которые нарушают (или дополняют) стандарт SQL, но зато очень удобны в веб-разработке. Она легко держит пару тысяч установленных соединений, а также несколько тысяч коннектов/дисконнектов в секунду.
Я более, чем уверен, что код всего этого просто ужасен, но у этого всего был смысл — сделать базу максимально простой и удобной в эксплуатации, а не для разработки.
За счёт этого MySQL не так стыдно использовать при горизонтальном масштабировании — поскольку база всё равно ничего особо не умеет, то зачастую можно легко её расшардить на много (100+) серверов, не особо потеряв возможностях и производительности.
Резюмируя — я очень уважаю людей из перконы за то, что они делают, но странно слышать про красоту кода от ваших сотрудников. Какое отношение имеет красота кода к производительности или надежности? Очень часто самый быстро работающий код выглядит просто ужасно, и наоборот. Мне вот лично архитектурно намного больше нравится MyISAM, чем InnoDB — потому что первый можно хоть самому на коленке реализовать, а вот InnoDB порой удивляет своей внутренней сложностью и запутанностью. Иногда складывается ощущение, что InnoDB вообще создавался для того, чтобы запудрить мозг тому, кто его использует, чтобы он даже не пытался во всём этом разобраться, а просто использовал и слепо верил в то, что всё будет хорошо. Но вот иногда бывает нехорошо, и тогда становится очень ценным свойство прозрачности системы и простоты починки. С InnoDB, мягко говоря, всё очень сложно. Например, чтобы его забекапить, нельзя просто скопировать его файлы данных, даже с выключенного сервера. Хотелось бы иметь либо систему, в которой можно разобраться, либо систему без проблем с производительностью и удобством эксплуатации. Лично для меня очевидно, что второе — это что-то из области фантастики, поэтому системы должны быть прозрачными и чиниться с помощью «молотка и такой-то матери». Кстати, пример с репликацией очень хороший — репликация сделана по-тупому, и сейчас легко понять, почему она тормозит (или ломается), и что с этим делать. Я боюсь представить, что будет, когда в MySQL тоже появится физическая репликация. Какие действия нужно будет предпринимать, если всё-таки там что-то пойдет не так? А точно она никогда не будет отставать на одинаковом железе? А как будет реализован в такой схеме master-master?
В общем, я надеюсь, я донес основную мысль :). MySQL всегда мне нравился именно удобством эксплуатации, и хотелось бы, чтобы это оставалось приоритетом для разработчиков, а не какие-то другие вещи.
Спасибо за комментарий. Во избежание кривотолков хочу сказать, что я не являюсь сотрудником Перконы с августа этого года. Это в общем мало на что влияет, но тут такой накал страстей, что лучше высказать это явно.
По поводу кода и производительности. Я кратко, если не возражаете. Связи прямой конечно нет. На прошлом HighLoad++ я делал доклад о том, что InnoDB как проект началась в начале 90-х годов прошлого века, для совсем других ОС и оборудования. Потом был долгий период застоя, когда InnoDB и основной сервер принадлежали разным компаниям. И с 2010г. усиление команды и быстрый прогресс для адаптации к современным реалиям. Посмотрите на сайте HL++, там даже какая-то черновая версия моих слайдов лежит.
На текущий момент в общем-то всё, о чём вы говорите, исправлено. InnoDB в 5.7 — это зверь в плане производительности, даже на тестах в Перконе каких-то серьёзных дефектов выявлено не было. И это впервые за всё время.
Но вообще такие детальные комментарии дают много идей для дальнейших публикаций и докладов. Поэтому ещё раз спасибо! :)
По поводу кода и производительности. Я кратко, если не возражаете. Связи прямой конечно нет. На прошлом HighLoad++ я делал доклад о том, что InnoDB как проект началась в начале 90-х годов прошлого века, для совсем других ОС и оборудования. Потом был долгий период застоя, когда InnoDB и основной сервер принадлежали разным компаниям. И с 2010г. усиление команды и быстрый прогресс для адаптации к современным реалиям. Посмотрите на сайте HL++, там даже какая-то черновая версия моих слайдов лежит.
На текущий момент в общем-то всё, о чём вы говорите, исправлено. InnoDB в 5.7 — это зверь в плане производительности, даже на тестах в Перконе каких-то серьёзных дефектов выявлено не было. И это впервые за всё время.
Но вообще такие детальные комментарии дают много идей для дальнейших публикаций и докладов. Поэтому ещё раз спасибо! :)
Спасибо за ответ, Алексей! В таком случае, будем ждать новых статей :). Мои комментарии в основном относились к MySQL 5.5, но причина довольно простая — мы ограниченно используем даже 5.6 на продакшене по причине относительной нестабильности «новой» версии. В development-окружении у нас даже «лочилась» база под высокой нагрузкой, но в новых минорных версиях эта проблема исправлена.
Зачем нужны начиненные элекроникой лексусы, когда у шишиги проходимость в разы лучше, и починить её можно с помощью тапка и чулок?
А мне как-то приходилось разбираться как работает MyISAM: вот от этой части кода MySQL у меня волосы встали дыбом. Мне не понятно как оно вообще могло называться СУБД с таким-то отношением к данным и с таким стилем программирования. Ну и попатчить что хотел, я не смог за вменяемое время: разобраться в этом вермишельном ООП было очень тяжело.
Юнит-тесты в MySQL были всегда последние лет 9, что я ей вплотную занимаюсь.
Спасибо за статью! Плюс в карму однозначно! Пишите, пишите и пишите еще! Вы обещали в статье :)
Статья хорошая, хотя и с претензией на знание предмета (постгреса). Для себя я давно решил с MySQL и потому сил и эмоций на нее более тратить не хочу. На дворе 21 век и все проекты давно полибазны, то есть для каждого сервиса используют то, что лучше всего подходит. Хотите MySQL, в добрый путь, особенно, если вы родились с MySQL в обнимку и все по нее знаете.
Касательно форков, я всегда говорил, что наше сообщество форки любит и принимает, ибо они полезны. Однако, база данных — это весьма ответственная штука и чтобы пользоваться в критически важных местах нужно определенное доверие. В этом смысле форки MySQL типа еще незрелые. Лично мне, как человеку, с MySQL жизнь не прожившему, трудно разобраться в ее форках и версиях. На постгресовых форках проверяются интересные идеи, слишком революционные для стабильного релиза. Как правило, это специализированные субд, которые легко отождествляются по области применения и спутаться в выборе очень трудно.
Ну а про функции Светы Смирновой для json, при всей уважении к ней, можно только сказать, что это нативностью и не пахнет. Бинарного хранилища нет, а это на корню губит весь функционал. Наш код открыт да с либеральной BSD лиценцией, MySQL возьмет себе и все будет хорошо.
Что касается репликации, то пусть придет Олег Царев, я не буду лишать его хлеба.
Касательно форков, я всегда говорил, что наше сообщество форки любит и принимает, ибо они полезны. Однако, база данных — это весьма ответственная штука и чтобы пользоваться в критически важных местах нужно определенное доверие. В этом смысле форки MySQL типа еще незрелые. Лично мне, как человеку, с MySQL жизнь не прожившему, трудно разобраться в ее форках и версиях. На постгресовых форках проверяются интересные идеи, слишком революционные для стабильного релиза. Как правило, это специализированные субд, которые легко отождествляются по области применения и спутаться в выборе очень трудно.
Ну а про функции Светы Смирновой для json, при всей уважении к ней, можно только сказать, что это нативностью и не пахнет. Бинарного хранилища нет, а это на корню губит весь функционал. Наш код открыт да с либеральной BSD лиценцией, MySQL возьмет себе и все будет хорошо.
Что касается репликации, то пусть придет Олег Царев, я не буду лишать его хлеба.
О, Олег на Хабре! Привет!
> Статья хорошая, хотя и с претензией на знание предмета (постгреса).
Нет-нет, я в самом начале пишу, что знаю PostgreSQL очень плохо. И ни на что в этом плане вроде бы не претендовал, да и не собираюсь.
>В этом смысле форки MySQL типа еще незрелые. Лично мне, как человеку, с MySQL жизнь не прожившему, трудно разобраться в ее форках и версиях.
Вот эти два предложения немного друг другу противоречат.
> Ну а про функции Светы Смирновой для json, при всей уважении к ней, можно только сказать, что это нативностью и не пахнет.
Я написал, что «ограниченная поддержка в 5.6, нативная в 5.7». То, что есть в 5.7 — это не UDF.
> Статья хорошая, хотя и с претензией на знание предмета (постгреса).
Нет-нет, я в самом начале пишу, что знаю PostgreSQL очень плохо. И ни на что в этом плане вроде бы не претендовал, да и не собираюсь.
>В этом смысле форки MySQL типа еще незрелые. Лично мне, как человеку, с MySQL жизнь не прожившему, трудно разобраться в ее форках и версиях.
Вот эти два предложения немного друг другу противоречат.
> Ну а про функции Светы Смирновой для json, при всей уважении к ней, можно только сказать, что это нативностью и не пахнет.
Я написал, что «ограниченная поддержка в 5.6, нативная в 5.7». То, что есть в 5.7 — это не UDF.
Мне непонятна цель этой статьи. Пользователям постгреса эта mysql совсем по барабану, а пользователям mysql, которые хотят мигрировать на постгрес, эта статья ничего не принесла. Еще раз холивар развести? Автор может хорошо на кнопки нажимать, есть много интересных тем для статей. Надеюсь, что следующие статьи у него будут более содержательными.
Олег, я тоже сначала не очень понимал, к кому обращены все эти «наезды» на MySQL практически на каждом докладе про Постгрес. Кстати говоря, за все мои 11 лет в MySQL сообществе, я не слышал ни единого доклада про MySQL с наездами на Постгрес, но это лирическое отступление.
Как показывают комментарии с к этим статьям, очень много людей либо работали в прошлом, либо работают до сих пор с обеими СУБД. Что оправдывает такие статьи, но не полуграмотную критику с высоких трибун.
Как показывают комментарии с к этим статьям, очень много людей либо работали в прошлом, либо работают до сих пор с обеими СУБД. Что оправдывает такие статьи, но не полуграмотную критику с высоких трибун.
Да бросьте, кому нужны наезды на то, что давно неинтересно. Разве что в дискуссии, но там все может быть. Приведите пример хоть одного наезда или «полуграмотную критику с высоких трибун». У вас в голове тоже мифы какие-то. Получается, как в одном известном фильме, «Я бежала за вами три дня, чтобы сказать вам, что вы мне неинтересны». Еще раз, постгресисту MySQL не интересен! Изучайте постгрес, пишите статьи про фичи, это будет полезно, а раздувать холивар на хабре — это плохое начало.
Вы мою-то статью читали? Я там привёл пример с конференции. Я мог бы назвать название конференции, год, и кто ещё это может подтвердить, но до маразма-то доходить не будем, ладно? И это не единственный пример, который я могу привести.
Читал-читал и все жду, когда вы исправите «полуграмотные утверждения» на что-то более нейтральное.
Что касается конференций, то я еще раз утверждаю, что у вас просто эффект преломления сознания. Дискусии бывают жаркие, но специально никто ни на кого не наезжают, только технические споры. Вот пример, кстати, с моим участием, совместной встречи двух сообществ, найдите там наезды :)
postgresmen.ru/articles/postgresql-vs-mysql-moscow-2009
Что касается конференций, то я еще раз утверждаю, что у вас просто эффект преломления сознания. Дискусии бывают жаркие, но специально никто ни на кого не наезжают, только технические споры. Вот пример, кстати, с моим участием, совместной встречи двух сообществ, найдите там наезды :)
postgresmen.ru/articles/postgresql-vs-mysql-moscow-2009
Я исправил в посте «полуграмотные» на «не вполне корректные» и убрал ваше имя. Исключительно из уважения. Не думал, что это вызовет такую болезненную реакцию.
По поводу того кто, что и когда говорил — это не для публичных выяснений тема. Давайте поговорим при личной встрече.
Ещё раз, вся статья написана не для холивора, а с прямо противоположными целями. Вы как-то странно её читаете.
По поводу того кто, что и когда говорил — это не для публичных выяснений тема. Давайте поговорим при личной встрече.
Ещё раз, вся статья написана не для холивора, а с прямо противоположными целями. Вы как-то странно её читаете.
Вы меня не поняли, кого вы посчитали сотрудниками Postgres Professional? Ни одного сотрудника в обсуждении я не увидел. Если вы считаете Мишу Тюрина нашим сотрудником, так это не так, увы. Миша является VIP в Avito.ru, главный за все базы. Поэтому, поправьтесь еще раз и окончательно.
Я не обижаюсь, а наоборот, хочу вас немного поправить, чтобы больше таких конфузов не было. Неужели вы не видите, что я до сих пор никого не заминусовал :) У вас есть слог и рвение, что не очень часто совпадает в нашем техническом мире, поэтому я вас призываю к созиданию, а не к обидкам и нападкам. Можете представить, сколько всего я наблюдал за 20 лет опенсорса :)
Я не обижаюсь, а наоборот, хочу вас немного поправить, чтобы больше таких конфузов не было. Неужели вы не видите, что я до сих пор никого не заминусовал :) У вас есть слог и рвение, что не очень часто совпадает в нашем техническом мире, поэтому я вас призываю к созиданию, а не к обидкам и нападкам. Можете представить, сколько всего я наблюдал за 20 лет опенсорса :)
У меня есть подозрение почему статей с наездами на постгре от mysql нет — чтобы их писать, надо залезть в постгре. А если ты туда залез, зачем тебе обратно?
Может быть и так. Или вот другая версия: это такая игра в «царя горы». Кто в мире web сейчас «царь горы», а кто хотел бы им быть, думаю объяснять не нужно :)
Как насчет тех, кто выбирает БД и смотрит на всю критику MySQL, актуальную для древних версий?
Если вам она поможет для выбора, то плюсуйте, но мне она показалась просто еще одним холиваром.
Отнюдь. Вот представьте, есть человек, который начинает свой путь как разработчик. Ему надо выбрать базу, он взвешивает эти два варианта — постгре и май. Лезет в интернет, находит статью лохматого года «в май не транзакций». Лезет проверять, натыкается на комментарии на Хабре в том же духе. Так создается некий ореол вида «везде так сказано». Потом такой человек, «прокачавшись» в постгре, приходит в проекты на мае и начинает гнуть пальцы «да май — шлак полный, там ничего нет, давайте все под постгре переделаем». Поэтому отвечать на такие заведомо некорректные аргументы надо.
Посыл статьи правильный: в мае есть реальные проблемы, чтобы еще выдумывать новые (или вспоминать старые, не существующие ныне).
Я в статье не заметил ничего вида «постгре — ерунда, смотрите какой май крутой». Критикуется критика mysql. Не критикуются постгрешники как таковые. Только типичные заблуждения.
Посыл статьи правильный: в мае есть реальные проблемы, чтобы еще выдумывать новые (или вспоминать старые, не существующие ныне).
Я в статье не заметил ничего вида «постгре — ерунда, смотрите какой май крутой». Критикуется критика mysql. Не критикуются постгрешники как таковые. Только типичные заблуждения.
Тут получается немножко другая однобокость. Поскольку в статье собрана распространённая неверная критика, может сложиться впечатление («ореол»), что вся критика со стороны postgresql-коммьюнити необоснована, растёт из седой старины и т.д. Но, уже из комментариев видно, что на самом деле критика критики опирается местами на неопределённое будущее, а людям в этом случае критикуемые вопросы крайне болезненны сейчас.
На самом деле, тут нужно действительно «пилить» статью-сравнение двух баз в духе «вот так на самом деле прямо здесь и сейчас». Но это уже скорее хорошая статья для энциклопедии.
Автор ссылается на ряд крупных контор, которые используют MySQL, в духе «видите — это реальность, а не legacy». Но, если начать копать, то выясняется, что MySQL там зачастую используется как key-value хранилище. И в принципе было всё-равно, что будет так использоваться в этой роли — кандидатов много, просто MySQL уже был и именно с этой ролью справлялся неплохо, поэтому остался как наследие (история Facebook, Twitter — про других не так наслышан).
Тот же HandlerSocket — с одной стороны индульгенция MySQL — «у нас возможно и такое», с другой — HandlerSocket по-сути отодвигает весь слой MySQL в сторону как ненужный тормозящий хлам, а пускает нас во внутренности движка InnoDB, который на самом деле может сильно больше, чем MySQL ему позволяет.
С обратной стороны — логически некорректно говорить, что в Postgres только один движок, а «финт ушами» вроде HandlerSocket невозможен. Движков на самом деле несколько, но они конкурируют не за роль основного управляющего, а за роль реализаторов специфических запросов и функций. Postgres не менее расширяемый «хранилищами», просто это расширение идёт на другом уровне и более структурировано (те же: колоночное хранилище в памяти или обработчики запросов с вычислениями на GPU) — нет жёсткого ограничения «если используешь это, то нельзя использовать то». И само основное хранилище вполне себе расширяемо — новые типы данных, новые типы индексов, встраиваемые языки — всё это по сути можно создавать (и оно так и создаётся) как плагины. Что-то всем нужное и стабильное — пойдёт в апстрим «из коробки», что-то будет оформлено как комплект стандартных дополнений, что-то придётся искать или создавать самому и встраивать с прямыми руками и напильником.
Поэтому в принципе уже сама постановка вопроса MySQL vs PostgreSQL изначально некорректна, как некорректно сравнивать «широкое с гибким» )) Соответственно все «холивары» идут мимо и скатываются в нечто унылое.
Корректней было бы сравнивать конкретные «фичи» и их комплексы в проекции на решаемые задачи в целом. Сравнить не только наличие фич, но и возможность разные фичи связывать, использовать, настраивать. Интересно рассматривать «бутылочные горлышки», из-за которых важные задачи не решаются и приходится менять целую платформу.
Мы на самом деле видим много отзывов в духе «как я перешёл на Postgres, потому что мне не хватило того-то» и «меня в MySQL всё устраивает, всего хватает», обратные — в природе встречаются настолько редко, что это куда больше создаёт «ореол» MySQL — «пластмассовой машинки в песочнице», из которой дети вырастают и пересаживаются в «автомобиль» Postgres и «выезжают на автобан».
На самом деле, тут нужно действительно «пилить» статью-сравнение двух баз в духе «вот так на самом деле прямо здесь и сейчас». Но это уже скорее хорошая статья для энциклопедии.
Автор ссылается на ряд крупных контор, которые используют MySQL, в духе «видите — это реальность, а не legacy». Но, если начать копать, то выясняется, что MySQL там зачастую используется как key-value хранилище. И в принципе было всё-равно, что будет так использоваться в этой роли — кандидатов много, просто MySQL уже был и именно с этой ролью справлялся неплохо, поэтому остался как наследие (история Facebook, Twitter — про других не так наслышан).
Тот же HandlerSocket — с одной стороны индульгенция MySQL — «у нас возможно и такое», с другой — HandlerSocket по-сути отодвигает весь слой MySQL в сторону как ненужный тормозящий хлам, а пускает нас во внутренности движка InnoDB, который на самом деле может сильно больше, чем MySQL ему позволяет.
С обратной стороны — логически некорректно говорить, что в Postgres только один движок, а «финт ушами» вроде HandlerSocket невозможен. Движков на самом деле несколько, но они конкурируют не за роль основного управляющего, а за роль реализаторов специфических запросов и функций. Postgres не менее расширяемый «хранилищами», просто это расширение идёт на другом уровне и более структурировано (те же: колоночное хранилище в памяти или обработчики запросов с вычислениями на GPU) — нет жёсткого ограничения «если используешь это, то нельзя использовать то». И само основное хранилище вполне себе расширяемо — новые типы данных, новые типы индексов, встраиваемые языки — всё это по сути можно создавать (и оно так и создаётся) как плагины. Что-то всем нужное и стабильное — пойдёт в апстрим «из коробки», что-то будет оформлено как комплект стандартных дополнений, что-то придётся искать или создавать самому и встраивать с прямыми руками и напильником.
Поэтому в принципе уже сама постановка вопроса MySQL vs PostgreSQL изначально некорректна, как некорректно сравнивать «широкое с гибким» )) Соответственно все «холивары» идут мимо и скатываются в нечто унылое.
Корректней было бы сравнивать конкретные «фичи» и их комплексы в проекции на решаемые задачи в целом. Сравнить не только наличие фич, но и возможность разные фичи связывать, использовать, настраивать. Интересно рассматривать «бутылочные горлышки», из-за которых важные задачи не решаются и приходится менять целую платформу.
Мы на самом деле видим много отзывов в духе «как я перешёл на Postgres, потому что мне не хватило того-то» и «меня в MySQL всё устраивает, всего хватает», обратные — в природе встречаются настолько редко, что это куда больше создаёт «ореол» MySQL — «пластмассовой машинки в песочнице», из которой дети вырастают и пересаживаются в «автомобиль» Postgres и «выезжают на автобан».
> Но, уже из комментариев видно, что на самом деле критика критики опирается местами на неопределённое будущее, а людям в этом случае критикуемые вопросы крайне болезненны сейчас.
Я говорил о «скором релизе MySQL 5.7», который был выпущен… сегодня :) Если бы он был в глубокой альфе, я бы не стал его упоминать.
В остальной части не совсем понял критику. Не нужно пытаться увидеть в публикации то, чего там нет. Это не критика PostgreSQL и не попытка каких-либо сравнений. Это обзор типичных заблуждений о MySQL и корректная формулировка реальных проблем. Ни больше, ни меньше. Я ничего из этого не придумал сам — оно всё на виду, например в посте varanio, который действительно был попыткой сравнения. Если что-то упустил — пишите.
Про движки — нет, вы не полностью понимаете их концепцию. Постараюсь дать развёрнутое описание в будущем.
Я говорил о «скором релизе MySQL 5.7», который был выпущен… сегодня :) Если бы он был в глубокой альфе, я бы не стал его упоминать.
В остальной части не совсем понял критику. Не нужно пытаться увидеть в публикации то, чего там нет. Это не критика PostgreSQL и не попытка каких-либо сравнений. Это обзор типичных заблуждений о MySQL и корректная формулировка реальных проблем. Ни больше, ни меньше. Я ничего из этого не придумал сам — оно всё на виду, например в посте varanio, который действительно был попыткой сравнения. Если что-то упустил — пишите.
Про движки — нет, вы не полностью понимаете их концепцию. Постараюсь дать развёрнутое описание в будущем.
Наверно вместо этого комментария стоило бы уже статью написать, но он слишком специфичен как ответ. Заранее приношу извинения за этот приступ графомании :-)
> Это не критика PostgreSQL и не попытка каких-либо сравнений
Разумеется сама статья — не критика или попытка сравнений. Но тема статьи о том как правильно говорить о «MySQL vs Postgres». Без этого не было бы и статьи.
Но, Вы поднимаете тему не менее однобоко (со стороны одного из лагерей, причём с позиции наиболее «заинтересованной» его части — разработчиков), не до конца понимая или как-то по-своему понимая/интерпретируя утверждения (что явно заметно в следующей статье).
В конечном итоге те, кто глубоко себя посвящает одной из двух конкурирующих платформ/технологий, во второй типично будут разбираться значительно хуже и заблуждаться. Поэтому я и утверждаю, что «разборы мифов» и «разборы разборов» — не продуктивны и будут порождать новые мифы, а значительно продуктивнее было бы совместными усилиями сделать сводную таблицу возможностей и подводных камней с исследованиями и пруфами (но не уверен, что эта идея наберёт достаточное количество заинтересованных сторонников среди тех, кто «в теме», «профит» с этого предприятия крайне ограничен).
> который был выпущен… сегодня
И только сейчас начинает появляться в репозиториях ведущих дистрибутивов, а станет дефолтом в LTS и на хостингах…
Буду говорить только за себя ))
Я перешёл на Postgres, когда в модных книжках уже был MySQL 5.0, на горизонте маячил 5.1, а на хотинге было событием встретить что-то отличное от «тройки». Конечно, тот факт, что в MySQL что-то хорошее появляется и сама эта СУБД развивается — он со всех сторон положительный: конкуренция ускоряет развитие, а Postgres включился в гонку сразу на всех уровнях и направлениях — и с MySQL, и с Oracle, и с решениями типа Mongo, постепенно адаптируя их сильные стороны.
С поддержкой актуальных версий MySQL на типовых хостингах наверняка ситуация улучшилась, да и выделенное железо перестало быть недоступной по цене экзотикой, хотя бы в формате «облака» или VPS, где можно всё сделать «как правильно». Но, лично для меня с выходом 5.7 мало что меняется.
Я использую возможности Postgres, которые ещё неизвестно когда появятся в MySQL и появятся ли вообще, как Вы пишете «сообществу это не нужно» («не очень-то и хотелось» ) и при этом мне доступен широкий простор того, что я ещё могу и планирую использовать в Postgres. MySQL все эти годы так или иначе находился в позиции «догоняющего», при том, что некоторые возможности, возможно даже появились и раньше, чем в Postgres (тот же UPSERT), а для некоторого круга задач MySQL возможно даже чем-то лучше (Key/Value режим InnoDB с HandlerSocket). Я даже не исключаю, что ради последнего согласился бы пополнить «длинный список», поскольку с некоторого времени формально InnoDB — это таки уже MySQL ))
Но в целом, в целом… долгие годы разработчики MySQL вообще не ставили перед собой задачу «догнать и перегнать»…
Когда-то я сам думал в рамках минимализма: «пусть инструмент и с ограниченными возможностями, но главное, что он в хороших руках». В определённый момент, поймав себя на том, что изобретаю транзакции, принял решение о переходе с MyISAM на InnoDB. Потом добравшись до Postgres и вкусив, понял, что назад — дороги нет. Конечно, «никогда не говори «никогда»», но всё же: MySQL не в состоянии предложить того, что Postgres делает играючись. А key-value… есть для этого специализированные решения, которые с разгромным счётом уделают и Postgres, и InnoDB с HS, но при этом в Postgres к ним есть стандартный интерфейс (как и к MySQL) прямо из базы (какие там, кстати, перспективы у SQL/MED в MySQL?).
Но это, разумеется, всё оффтопик. Просто для лучшего понимания.
А «не оффтопик» из этого следующий: поскольку я, как и многие, кто будет критиковать или занимать нейтральную позицию в отношении MySQL, но при этом использовать другие СУБД (читай Mongo, Postgres и дальше по списку) — наверняка будем пользоваться в своих суждениях либо неактуальной информацией, либо особенно важными конкретно для нас слабыми местами MySQL/сильными сторонами других СУБД. Поэтому, если Вы хотите бороться с мифами (читай «евангелизировать MySQL для соответствующей (ангажированной) аудитории»), то как минимум Вам так же необходимо понимать и избавляться от своих заблуждений и мифов в отношении этой аудитории. Соответственно аргументы типа «раз нет, значит это не нужно» («конечно не нужно, ведь есть же %DBMS_NAME%, где всё в шоколаде»), «ряд компаний используют» (с любой DBMS со стажем можно составить немаленький список солидных компаний так или иначе её использующих, а у визави за редким исключением есть опыт перехода с MySQL на нечто для него лучшее и «забывания этого кошмара» ;-)) — аргументами совершенно не являются. Более того с этой позиции в мифах — именно Вы, полагая, что пытаетесь просветить «не разобравшихся в вопросе» (это конечно совершенно не касается детских заблуждений и откровенно устаревших утверждений, но в остальном — самая суть).
Ну и в довесок Вам там ещё комментарий во второй теме :-)
> Это не критика PostgreSQL и не попытка каких-либо сравнений
Разумеется сама статья — не критика или попытка сравнений. Но тема статьи о том как правильно говорить о «MySQL vs Postgres». Без этого не было бы и статьи.
Но, Вы поднимаете тему не менее однобоко (со стороны одного из лагерей, причём с позиции наиболее «заинтересованной» его части — разработчиков), не до конца понимая или как-то по-своему понимая/интерпретируя утверждения (что явно заметно в следующей статье).
В конечном итоге те, кто глубоко себя посвящает одной из двух конкурирующих платформ/технологий, во второй типично будут разбираться значительно хуже и заблуждаться. Поэтому я и утверждаю, что «разборы мифов» и «разборы разборов» — не продуктивны и будут порождать новые мифы, а значительно продуктивнее было бы совместными усилиями сделать сводную таблицу возможностей и подводных камней с исследованиями и пруфами (но не уверен, что эта идея наберёт достаточное количество заинтересованных сторонников среди тех, кто «в теме», «профит» с этого предприятия крайне ограничен).
> который был выпущен… сегодня
И только сейчас начинает появляться в репозиториях ведущих дистрибутивов, а станет дефолтом в LTS и на хостингах…
Буду говорить только за себя ))
Я перешёл на Postgres, когда в модных книжках уже был MySQL 5.0, на горизонте маячил 5.1, а на хотинге было событием встретить что-то отличное от «тройки». Конечно, тот факт, что в MySQL что-то хорошее появляется и сама эта СУБД развивается — он со всех сторон положительный: конкуренция ускоряет развитие, а Postgres включился в гонку сразу на всех уровнях и направлениях — и с MySQL, и с Oracle, и с решениями типа Mongo, постепенно адаптируя их сильные стороны.
С поддержкой актуальных версий MySQL на типовых хостингах наверняка ситуация улучшилась, да и выделенное железо перестало быть недоступной по цене экзотикой, хотя бы в формате «облака» или VPS, где можно всё сделать «как правильно». Но, лично для меня с выходом 5.7 мало что меняется.
Я использую возможности Postgres, которые ещё неизвестно когда появятся в MySQL и появятся ли вообще, как Вы пишете «сообществу это не нужно» («не очень-то и хотелось» ) и при этом мне доступен широкий простор того, что я ещё могу и планирую использовать в Postgres. MySQL все эти годы так или иначе находился в позиции «догоняющего», при том, что некоторые возможности, возможно даже появились и раньше, чем в Postgres (тот же UPSERT), а для некоторого круга задач MySQL возможно даже чем-то лучше (Key/Value режим InnoDB с HandlerSocket). Я даже не исключаю, что ради последнего согласился бы пополнить «длинный список», поскольку с некоторого времени формально InnoDB — это таки уже MySQL ))
Но в целом, в целом… долгие годы разработчики MySQL вообще не ставили перед собой задачу «догнать и перегнать»…
Когда-то я сам думал в рамках минимализма: «пусть инструмент и с ограниченными возможностями, но главное, что он в хороших руках». В определённый момент, поймав себя на том, что изобретаю транзакции, принял решение о переходе с MyISAM на InnoDB. Потом добравшись до Postgres и вкусив, понял, что назад — дороги нет. Конечно, «никогда не говори «никогда»», но всё же: MySQL не в состоянии предложить того, что Postgres делает играючись. А key-value… есть для этого специализированные решения, которые с разгромным счётом уделают и Postgres, и InnoDB с HS, но при этом в Postgres к ним есть стандартный интерфейс (как и к MySQL) прямо из базы (какие там, кстати, перспективы у SQL/MED в MySQL?).
Но это, разумеется, всё оффтопик. Просто для лучшего понимания.
А «не оффтопик» из этого следующий: поскольку я, как и многие, кто будет критиковать или занимать нейтральную позицию в отношении MySQL, но при этом использовать другие СУБД (читай Mongo, Postgres и дальше по списку) — наверняка будем пользоваться в своих суждениях либо неактуальной информацией, либо особенно важными конкретно для нас слабыми местами MySQL/сильными сторонами других СУБД. Поэтому, если Вы хотите бороться с мифами (читай «евангелизировать MySQL для соответствующей (ангажированной) аудитории»), то как минимум Вам так же необходимо понимать и избавляться от своих заблуждений и мифов в отношении этой аудитории. Соответственно аргументы типа «раз нет, значит это не нужно» («конечно не нужно, ведь есть же %DBMS_NAME%, где всё в шоколаде»), «ряд компаний используют» (с любой DBMS со стажем можно составить немаленький список солидных компаний так или иначе её использующих, а у визави за редким исключением есть опыт перехода с MySQL на нечто для него лучшее и «забывания этого кошмара» ;-)) — аргументами совершенно не являются. Более того с этой позиции в мифах — именно Вы, полагая, что пытаетесь просветить «не разобравшихся в вопросе» (это конечно совершенно не касается детских заблуждений и откровенно устаревших утверждений, но в остальном — самая суть).
Ну и в довесок Вам там ещё комментарий во второй теме :-)
Вы очень зря так думаете. Лично мой продакшен весь на MySQL и нет, вы не правильно подумали. Я не «ободрился» этой статьей, а очень даже развеял пару собственных стереотипов. Я знаю что такое PG и честно говоря после прочтения этой статьи осознал что некоторые камни в сторону MySQL были ну очень уж стереотипны и самое плохое что я сам в это верил, поэтому очень даже спасибо автору статьи. А новость про нативную поддержку JSON скорректировала планы по переводу одного из проектов на PG т.к. MySQL-ной реализации мне с головой хватит.
За статью плюсую!
Но оставлю тут полежать и следующие (если что, я не DBA и не DBD):
1. Миграции баз, сначала между движками, а потом между форками мускуля (например Percona->MariaDB) ни разу не прошли безболезненно. Везде происходило или ручное вмешательство или какие-то утилиты с каких-то форумов.
2. Миграции с версии на версию в постгресе, а так же psql<->mssql, psql<->oracle, psql<->db2, проходили достаточно безболезненно, штатными средсвами или миграторами скаченными с инета. Для мускуля приходилось писать специальные миграторы и потом еще нормализировать (обычно в контексте используемого ORM данные).
3. Настроить внятно Galera у меня не вышло. Собственно я тут не претендую на пряморукость, но с куда менее известными БД типа cassandra, neo4j у меня проблем не было. Причем на куда более значимых объемах данных. Psql упоминать не буду, на нем я только master-slave делал, который работал по принципу запустил и забыл.
Но оставлю тут полежать и следующие (если что, я не DBA и не DBD):
1. Миграции баз, сначала между движками, а потом между форками мускуля (например Percona->MariaDB) ни разу не прошли безболезненно. Везде происходило или ручное вмешательство или какие-то утилиты с каких-то форумов.
2. Миграции с версии на версию в постгресе, а так же psql<->mssql, psql<->oracle, psql<->db2, проходили достаточно безболезненно, штатными средсвами или миграторами скаченными с инета. Для мускуля приходилось писать специальные миграторы и потом еще нормализировать (обычно в контексте используемого ORM данные).
3. Настроить внятно Galera у меня не вышло. Собственно я тут не претендую на пряморукость, но с куда менее известными БД типа cassandra, neo4j у меня проблем не было. Причем на куда более значимых объемах данных. Psql упоминать не буду, на нем я только master-slave делал, который работал по принципу запустил и забыл.
Кстати, я не понимаю, как работают мультимастер схемы. Ведь при фиксации изменений, надо фиксировать их на всех мастерах, а значит долго. А если не фиксировать на всех, то будет неконсистентно. И в случае сбоя будет непонятно что.
Именно так и работают. Тут все зависит от каналов между серверами. Например при update (я тут и insert понимаю) при 3-5 Мб/сек вполне прилично работает на амазоне m2.large (bkb xlage, не помню, который с честной сетью). Тут правда не я настраивал и было сильно после моей эпопеи с galera (я игрался ы 2012 году, точно зная, что есть работающие инсталляции, на амазон видел в начале 2015 года).
Что любопытно было в моем случае, у меня все время сервера были в пределах не только одного сегмента сети, но в одном свиче. Причем четкие 8-9 гигабит между серверами бегало, я проверял (10Гб/с карточки, прям ну очень энерпрайзные). Но все равно, в какой-то момент фиксация изменений начинала очень сильно тормозить. А кворум на выбор нового мастера в 5 минут впечатлял. :)
Что любопытно было в моем случае, у меня все время сервера были в пределах не только одного сегмента сети, но в одном свиче. Причем четкие 8-9 гигабит между серверами бегало, я проверял (10Гб/с карточки, прям ну очень энерпрайзные). Но все равно, в какой-то момент фиксация изменений начинала очень сильно тормозить. А кворум на выбор нового мастера в 5 минут впечатлял. :)
А можно вкратце, какие именно фичи мускуля перевесят чашу весов (для нового проекта) по сравнению с pg?
в моем случае:
1. Хранимки на чем угодно
2. GIN,GIST индксы
3. внятная работа (и индексация) json
4. встроенное, и впоне приличное, key-value
5. адекватный мастер-slave
6. развитые средства типа pgbouncer
7. куда более приличный оптимизатор запросов в мозгах
1. Хранимки на чем угодно
2. GIN,GIST индксы
3. внятная работа (и индексация) json
4. встроенное, и впоне приличное, key-value
5. адекватный мастер-slave
6. развитые средства типа pgbouncer
7. куда более приличный оптимизатор запросов в мозгах
Только религиозные взгляды конкретного человека могут повлиять на выбор mysql. Я имею ввиду солидные проекты, конечно.
Я повторю свой список, пусть и тут полежит. Так вот, Github, Wikipedia, Google, Facebook, Twitter, LinkedIn, Alibaba, Taobao, Booking.com, AirBnB, Dropbox, Pinterest, GroupOn, Yelp — это всё релизиозные взгляды конкретного человек, чтоб вы знали. Ну либо несолидные проекты.
Ну вот, вы все-таки холивар развиваете. Вы про фичи напишите, мы же тут разработчики и инженеры. Вы же просто не представляете, как делается выбор в больших проектах, а мы говорим про нашу реальную головную боль. Под религиозными взглядами я имел ввиду то, какой опыт уже имел конкретный человек и с чем знакома его команда. Если все имели опыт работы с mysql, то скорее всего и надо выбирать ее. Если вы хотите помочь человеку с нуля, причем этому человеку совсем по барабану мифы и наследия прошлых времен, то ему нужна совсем другая статья. Холиварщиков хватает и без вас, давайте позитив делать, а это означает употребите ваши умения на благо.
Вот тут, например, инженер из Facebook рассказывает, как и почему они выбирают MySQL для _новых_ проектов внутри Facebook. И это вовсе не потому, что «знакома команда». У Facebook «команда» знакома вообще со всем на свете.
Весь смысл моей статьи — вести какие-то взаимно интересные дискуссии вместо тупых холиворов. По-моему, люди вполне позитивно её оценивают в целом. Что не так?
Весь смысл моей статьи — вести какие-то взаимно интересные дискуссии вместо тупых холиворов. По-моему, люди вполне позитивно её оценивают в целом. Что не так?
Ну вот, вы все-таки холивар развиваете.
И это нам говорит человек, чуть ранее написавший это:
Только религиозные взгляды конкретного человека могут повлиять на выбор mysql
Из вашего утверждения можно сделать вывод, что у Google, Facebook и Twitter установлена коробочная версия mysql которая их удовлетворяет. Гораздо инетерснее узнать сколько там осталось от mysql :)
Так всё же открыто и доступно для исследования. github.com/webscalesql/webscalesql-5.6 Но я и без исследований могу сказать, что осталось от mysql там много. Очень много.
При всем к вам уважении, ваши комментарии как раз больше похожи на высказывание религиозных взлядов (которые в вашем случае очевидны :-).
Я сам в большинстве случаев предпочитаю pg, и «нюансами» mysql-я сыт по уши, но для выбора mysql существуют и объективные причины — в основном в крупных проектах, когда ACID приносится в жертву масштабируемости с ручным шардингом. Скажем, типичный паттерн — «в основном используем mysql как быструю доставалку из innodb по индексу через handlersocket, но иногда используем и SQL». Спросите у badoo-шников — их тут много :-)
Я сам в большинстве случаев предпочитаю pg, и «нюансами» mysql-я сыт по уши, но для выбора mysql существуют и объективные причины — в основном в крупных проектах, когда ACID приносится в жертву масштабируемости с ручным шардингом. Скажем, типичный паттерн — «в основном используем mysql как быструю доставалку из innodb по индексу через handlersocket, но иногда используем и SQL». Спросите у badoo-шников — их тут много :-)
Не-не, знаем мы эти «вкратце». Я «вкратце» упомянул мелкую такую проблемку в pg, и вылилось в километровый холивор. PG сообщество оно всё-таки местами религиозную секту напомнает — никакой самокритики, никакой самоиронии, только хардкор!
Я лучше отдельным постом напишу.
Я лучше отдельным постом напишу.
На маленьких базах сложно найти разницу между данными проектами. Если кто-то строит свой сайт на своём велосипедном движке, какая разница на чём делать. А вот найти хостинг дешёвый на чём, то кроме MySQL сложнее.
Tokudb ничего не перевесит.
Мне уже смешны критерии по которым сравнивают БД на сегодняшний день.
Какой смысл в том что вставка где-то идет на 15% быстрее или выборка. О ЧЕМ ЭТО ГОВОРИТ? О том что моё приложение на одной базе упрется в производительность на 15% раньше чем на другой? Так мне от этого как-то не легче. Куча каких-то тестов которые НЕ ГОВОРЯТ НИ О ЧЕМ.
Намного интереснее как оно позволяет масштабироваться горизонтально и вертикально. Намного интереснее почему партицирование в Mysql требует отсутствия foreigh key на всей таблице. Намного интереснее почему планировщик запросов при вложенном партицировании не использует все колонки как надо.
Намного интереснее знать как оно все ведет себя после сбоев. Как работает мастер-мастер репликация и есть ли она вообще. Синхронная, асинхронная. Вот что надо сравнивать, а не притянутые за уши тесты, далекие от практики и комьюнити.
Какой смысл в том что вставка где-то идет на 15% быстрее или выборка. О ЧЕМ ЭТО ГОВОРИТ? О том что моё приложение на одной базе упрется в производительность на 15% раньше чем на другой? Так мне от этого как-то не легче. Куча каких-то тестов которые НЕ ГОВОРЯТ НИ О ЧЕМ.
Намного интереснее как оно позволяет масштабироваться горизонтально и вертикально. Намного интереснее почему партицирование в Mysql требует отсутствия foreigh key на всей таблице. Намного интереснее почему планировщик запросов при вложенном партицировании не использует все колонки как надо.
Намного интереснее знать как оно все ведет себя после сбоев. Как работает мастер-мастер репликация и есть ли она вообще. Синхронная, асинхронная. Вот что надо сравнивать, а не притянутые за уши тесты, далекие от практики и комьюнити.
Я примерно то же самое написал в заключении. Можем и об этих вещах поговорить, да. Вот про сравнение репликаций я как раз планирую пост. Мне больше нравится излагать вещи связным текстом, чем урывками по сотням комментариев, которых всё равно никто не читают, сразу пишут свой.
К вопросу о репликациях: в последних версиях postgresql есть Logical Decoding[1] — API для декодирования write ahead log. На основе этого можно сделать много всего — как логическую репликацию «поверх физической», так и всякие другие интересные вещи — скажем, поток изменений в базе в JSON-формате[2], на который подписывается некий внешний демон приложения.
[1] http://www.postgresql.org/docs/9.5/static/logicaldecoding.html
[2] https://github.com/ildus/decoder_json
[1] http://www.postgresql.org/docs/9.5/static/logicaldecoding.html
[2] https://github.com/ildus/decoder_json
А в MySQL уже появились аналоги таких типов, как INET и CIDR или по старинке адреса хранить в INT чтобы запросы вхождения и сортировка корректные были?
У MySQL много форков и у них разброд
Я знаю всего два: percona, MariaDB
Разброд у них был, после того как MySQL попал в Oracle, и основному разработчику с конторой оказалось не по пути. В итоге он пошёл пилить MariaDB.
"- Ложки, потом нашли, но осадок остался"
«В MySQL есть нетранзакционные движки типа MyISAM»
Да, но тут не очень понятно, в чём критика. Говорить о MyISAM в 2015-м году можно только в плане поддержки legacy приложений. Честно говоря, последний раз живого пользователя MyISAM я встречал лет пять назад.
Спешу Вас разочаровать. Вы один из пользователей MyISAM. Системные таблицы БД всегда в MyISAM
Ссылка на документацию
Important
Do not convert MySQL system tables in the mysql database (such as user or host) to the InnoDB type. This is an unsupported operation. The system tables must always be of the MyISAM type.
О проблемах мултидвижковости MySQL, связанных с этим проблемах репликации, очень хорошо написано тут. Автор zabivator о проблемах репликации в MySQL, знает не по наслышке, лучше всего его об этом спросить, если нужны детали.
Далее, есть один очень важный момент связанный с репликацией: ссылка на статью в блоге разрабов percona MySQL Replication vs DRBD Battles
Цитата:
So when I would recommend to use DRBD with MySQL?
… it is often inevitable choice when you can’t avoid loosing any transaction – period. Some people would rather stand longer fallback time (as with DRBD) but would not like to have lost transactions which may happen with async replication. Another similar case is when you’re looking to ensured consistency – MySQL Replication can out of sync – and there is bunch of tips in documentation of how to do it. With DRBD the chance of nodes running out of sync is minimal and can be caused by software and hardware bugs rather than known limitations.
Cобственные наблюдения. Есть большой парк инсталляций MySQL/percona ~300 единиц. Все БД высоконагружены. Соотношение чтение: запись ~ 30:70. Тоесть запись превалирует над чтением. Все БД разнесены территориально и большинство находится в глубинке. Выключения эл-ва, довольно часты и продолжительны, — никакие ИБП не спасают. В 8-ми случаях из 10, приходится восстанавливать БД, т.к. системная информация не соответствует тому, что содержится в таблицах. За прошедший год, пришлось два экземпляра БД восстанавливать из бэкап.
Тоесть буква D в ACID, у MySQL какая-то странная... Ну или у админов руки кривые.
При этом у PostgreSQL буква D очень твёрдая, даже с дефолтными настройками.
«В MySQL плохой консольный клиент»
Как я понял, под этим понимают отсутствие контекстно-зависимого автодополнения. Я согласен, это может быть удобно.
Да, про это. Что-то проверить, что-то посчитать, порой часто приходится смотреть схему таблиц, а так двойной таб в постгресе, в таких случаях очень радует. Когда легче/быстрее/проще сделать запрос с консоли, чем открывать софт или лезть в браузер за пхпмайадмин, то несомненный плюс постгресу за консольный клиент. На другие случаи не консоли это уже другой пункт сравнения клиентов для баз: workbench phpmyadmin phppgadmin jetbrains etc.
Но для тех, кому это очень нужно, недавно появился проект pmysql с умным автодополнением и даже подсветкой синтаксиса.
Простите, вы ссылкой не ошиблись? Там что-то совсем не то и 2013 года комит :)
проблемы с физическими бэкапами, которые вынуждены блокировать сервер
Есть такая штука, она не решает пролему о которой вы говорите? www.percona.com/software/mysql-database/percona-xtrabackup
У нас технический блог по постгресу, а нам предложили читать про мифы о MySQL. Текст написан складно, но вот только непонятны цели. Зачем-то оскорбили нашу компанию Postgres Professional, которая образовалась только в феврале и где она могла обидеть MySQL, мне непонятно. Автор не сознается, ну да ладно с ним. Я приведу несколько ссылок, чтобы люди смогли посмотреть технические детали двух субд.
1. Википедия — https://en.wikipedia.org/wiki/Comparison_of_relational_database_management_systems
2. http://sql-workbench.net/dbms_comparison.html
3. https://www.wikivs.com/wiki/MySQL_vs_PostgreSQL?
Последняя ссылка особенно хороша и без каких-либо холиваров. В частности, там написано: «PostgreSQL was not available on Windows. First windows native version was 8.0. This was an advantage for MySQL.» Вот с этим я согласен.
1. Википедия — https://en.wikipedia.org/wiki/Comparison_of_relational_database_management_systems
2. http://sql-workbench.net/dbms_comparison.html
3. https://www.wikivs.com/wiki/MySQL_vs_PostgreSQL?
Последняя ссылка особенно хороша и без каких-либо холиваров. В частности, там написано: «PostgreSQL was not available on Windows. First windows native version was 8.0. This was an advantage for MySQL.» Вот с этим я согласен.
Я объяснил в самом начале, почему пост именно в этом блоге. И цели тоже объяснил. Я много раз слышал технически некорректные высказывания о MySQL практически в каждом докладе на разных конференциях. В том числе, и от вас лично, Олег. Возможно, вы тогда ещё не были сотрудником Postgres Professional, но сейчас-то вы им являетесь. Но я подкорректировал пост ровно как вы просили. Я готов привести все примеры лично, мне кажется не этичным вытаскивать всё это на публику. И мне не кажется, что я каким-то образом бросил тень на компанию Postgres Professional. Я в явном виде вырази своё хорошее к ней отношение и к вам лично.
Разводить какой-то холивор я не собирался и не собираюсь. Собственно, тут не было никакого холивора, пока вы не ворвались с обидами за Postgres Professional.
PS. Последняя ссылка сильно устарела. Я её читал при подготовке поста.
Разводить какой-то холивор я не собирался и не собираюсь. Собственно, тут не было никакого холивора, пока вы не ворвались с обидами за Postgres Professional.
PS. Последняя ссылка сильно устарела. Я её читал при подготовке поста.
На мой взгляд, упоминание Postgres Professional в этом посте действительно не слишком понятно. По следующим причинам:
1. Пост явно является ответом на недавнюю волну критики MySQL, в которой, как уже было замечено, представители Postgres Professinal никак не участвовали.
2. В большей части публичных выступлений Олега за последние годы, я также участвовал. Про MySQL вообще речь почти не заходила. А, например, MongoDB, критиковали много.
Исходя из этого, мне кажется, что это вы таким образом припомнили Олегу что-то, что он сказал в кулуарах n лет тому назад.
1. Пост явно является ответом на недавнюю волну критики MySQL, в которой, как уже было замечено, представители Postgres Professinal никак не участвовали.
2. В большей части публичных выступлений Олега за последние годы, я также участвовал. Про MySQL вообще речь почти не заходила. А, например, MongoDB, критиковали много.
Исходя из этого, мне кажется, что это вы таким образом припомнили Олегу что-то, что он сказал в кулуарах n лет тому назад.
Спасибо большое за статью. Прочитал по диагонали и, как мне кажется, кое-что было упущено. С вашего позволения, оставлю ссылку на свою версию сравнения PostgreSQL и MySQL, и оставить небольшое дополнение.
На мой взгляд, эти РСУБД сильно отличаются по функционалу. Например, PostgreSQL поддерживает курсоры и функциональные индексы, что потенциально позволяет более эффективно использовать СУБД. С другой стороны, в MySQL/MariaDB из одной и той же БД можно реплицировать разные таблицы на разные реплики, и, если я правильно помню, чуть ли не столбцы одной таблицы на разные реплики, что делает MySQL/MariaDB потенциально более масштабируемой. Плюс в PostgreSQL upsert появится только в версии 9.5 (которая вроде еще не до конца вышла), плюс есть недостатки в плане усложненной схемы database, schema, table, плюс MySQL/MariaDB реально знает больше людей.
На мой взгляд, эти РСУБД сильно отличаются по функционалу. Например, PostgreSQL поддерживает курсоры и функциональные индексы, что потенциально позволяет более эффективно использовать СУБД. С другой стороны, в MySQL/MariaDB из одной и той же БД можно реплицировать разные таблицы на разные реплики, и, если я правильно помню, чуть ли не столбцы одной таблицы на разные реплики, что делает MySQL/MariaDB потенциально более масштабируемой. Плюс в PostgreSQL upsert появится только в версии 9.5 (которая вроде еще не до конца вышла), плюс есть недостатки в плане усложненной схемы database, schema, table, плюс MySQL/MariaDB реально знает больше людей.
Где-то слышал, что Facebook делает запросы к MySQL без JOIN'ов, т.е. они не используют всех прелестей реляционной модели работы с данными. Это правда?
не полный список всем известных компаний
И всё же, эти компании используют тру mysql или свои допилы движков и костыли к нему?
Я просто оставлю это здесь habrahabr.ru/company/mailru/blog/248845
Там кстати есть и про репликацию. И да товарищ что писал статью по ссылке, знает о внутренней кухне PostgreSQL и MySQL весьма и весьма много. Как прочитаете, можете написать про то какая красивая репликация в MYSQL :)
Там кстати есть и про репликацию. И да товарищ что писал статью по ссылке, знает о внутренней кухне PostgreSQL и MySQL весьма и весьма много. Как прочитаете, можете написать про то какая красивая репликация в MYSQL :)
Продолжая так называемый холивар. Как бы не защищали мускуль, но база откровенно так себе (на мое скромное субъективное мнение).
Начнем с такого, как вы делаете консистентный бекап в мускуле? Это когда пока вы бекапите последнюю таблицу, в уже забекапленные добавляются данные, как сделать так, чтобы эти данные попали в дамп? Речь идет конечно про продакшн сервер с которым работают пользователи.
Про сложные запросы с джойнами, аггрегирующими функциями и вложенными селектами даже не хочу начинать.
Начнем с такого, как вы делаете консистентный бекап в мускуле? Это когда пока вы бекапите последнюю таблицу, в уже забекапленные добавляются данные, как сделать так, чтобы эти данные попали в дамп? Речь идет конечно про продакшн сервер с которым работают пользователи.
Про сложные запросы с джойнами, аггрегирующими функциями и вложенными селектами даже не хочу начинать.
mysqldump --single-transaction
И для MyISAM? Без блокировок на время бекапа базы?
Для MyISAM бэкапы делать со слэйва, который переводится в режим ридонли (тем же mysqldump).
Вам всю статью говорят: забейте на myisam; не использует его уже никто. А кто использует, те либо не знают, в чём проблема и значит им это проблем не доставляет; либо они знают, в чём проблема, и знают, как её решать.
А вообще — поднимаем slave, и бекапим с него. Мастер на время бекапа не блокируется.
ЗЫ пока я писал, VolCh уже ответил.
А вообще — поднимаем slave, и бекапим с него. Мастер на время бекапа не блокируется.
ЗЫ пока я писал, VolCh уже ответил.
Немного эмоционально напишу, так что извиняйте.
Протру глаза, это правда, что в базе данных есть движок, который все рекомендуют не использовать? Нормальные бекапы, на сколько мне известно, есть только для InnoDB.
Ну это понятно что со слейва можно делать, но это уже пошли костыли, специально поднимать слейв чтобы делать бекапы.
Протру глаза, это правда, что в базе данных есть движок, который все рекомендуют не использовать? Нормальные бекапы, на сколько мне известно, есть только для InnoDB.
Ну это понятно что со слейва можно делать, но это уже пошли костыли, специально поднимать слейв чтобы делать бекапы.
Нет, неправильно. Да, есть движок, и что? В линуксе тоже есть команда dd if=/dev/zero of=/dev/sda. Я не рекомендую её использовать, кроме тех случаев, когда вы точно знаете, что она делает и именно этого хотите. И ножом можно порезаться. И что?
В базе данных есть исторический движок, предназначенный для особых случаев. Используйте его, если понимаете, что делаете. Если не уверены, используйте движок по умолчанию. Да, движок особый, работа с ним тоже особая. Если использовать его не к месту, могут потребоваться костыли и вообще будут проблемы.
Это чего угодно касается, если применять неправильно.
В базе данных есть исторический движок, предназначенный для особых случаев. Используйте его, если понимаете, что делаете. Если не уверены, используйте движок по умолчанию. Да, движок особый, работа с ним тоже особая. Если использовать его не к месту, могут потребоваться костыли и вообще будут проблемы.
Это чего угодно касается, если применять неправильно.
Ну как full text search в InnoDB появится так и необходимость в MyISAM отпадет. А пока его особо там нет. А вот в PostgreSQL есть аналог причем с морфологией.
В 5.6 жеж вроде появился. Или он там плохой?
О и правда. Можно будет избавиться для таких полей от MyISAM. Но да мофрологии нет, но и то хлеб :)
FTS — это вообще не моя тема, мало что могу сказать. Но было интересно почитать этот комментарий про FTS в PostgreSQL. Побольше бы таких, сухо и по делу. habrahabr.ru/post/268631/#comment_8610255
Эм, простите, почему эти вновь добавленные вообще должны попасть в дамп? Они наоборот НЕ ДОЛЖНЫ попасть в этот дамп, если мы конечно про консистентный дамп. Они попадут в следующий дамп, строго по расписанию.
Дамп — это транзакция, в нём должны быть данные, которые были в базе на момент начала дампа, а не добавленные в процессе.
Дамп — это транзакция, в нём должны быть данные, которые были в базе на момент начала дампа, а не добавленные в процессе.
Смотрите, идет бекап: купленные книги (id, book_id, user_id), ..., пользователи (id, name). Пока бекапелись таблицы из "...", добавился новый пользователь и купил книгу, в итоге пользователь попадает в бекап, а купленная книга нет.
Или вот Вам пример понаглядней, выводим на главной последние купленные книги, бекап шел наоборот:
— пользователи (id, name)
— … # — тут регистрируется новый пользователь и покупает книгу
— купленные книги (id, book_id, user_id),
В итоге после восстановления из бекапа на главной 500 ошибка, из за того, что у купленной книги нет пользователя, данные которого мы хотим зачем-то вывести на главной. Это называется консистентность данных.
Состояние консистентного бекапа это некая точка во времени по всем таблицам, иначе выйдет что первая таблица забекапилась с утра, пока дошло до последней настал вечер, такой дамп можно, грубо говоря, просто выкинуть.
Или вот Вам пример понаглядней, выводим на главной последние купленные книги, бекап шел наоборот:
— пользователи (id, name)
— … # — тут регистрируется новый пользователь и покупает книгу
— купленные книги (id, book_id, user_id),
В итоге после восстановления из бекапа на главной 500 ошибка, из за того, что у купленной книги нет пользователя, данные которого мы хотим зачем-то вывести на главной. Это называется консистентность данных.
Состояние консистентного бекапа это некая точка во времени по всем таблицам, иначе выйдет что первая таблица забекапилась с утра, пока дошло до последней настал вечер, такой дамп можно, грубо говоря, просто выкинуть.
А как MySQL реагирует на ALTER TABLE, которая добавляет столбец в большую таблицу?
У меня сложилось вмечатление, что таблица блокируется и любое обращение к ней подвисает.
У меня сложилось вмечатление, что таблица блокируется и любое обращение к ней подвисает.
Но для MySQL есть утилита pt-online-schema-change, которая позволяет обходить многие ограничения ALTER TABLE в MySQL и про которую часто не знают или забывают.
Из статьи. И не только эта утилита, а без нее — да.
Она использует какие-то секретные возможности протокола?
То есть evolutons, которые автоматически выполняют SQL-команды, использовать не получится?
То есть evolutons, которые автоматически выполняют SQL-команды, использовать не получится?
На сколько я знаю, по другой утилите, есть предположение, что эта работает так же. Создается временная таблица с новой схемой, там для ускорения отключается создание индексов и т.п. Далее туда закопирываются данные, с той куда хотели внести изменения по схеме, затем строится индекс в новой таблице, возможно, догонка данных и быстрая замена старой таблицы на с новой схемой, хак? да, но задачу решает. Здесь есть специалисты mysql, поправьте если соврал.
Кстати, удобный клиент важен именно если не слишком часто им пользуешься и не успеваешь придумать workaround для неудобств.
Ну, это конечно меня вообще убивает: «repeatable read — uses snapshot per transaction for plain SELECT. See the “read committed” for SELECT FOR UPDATE, INSERT, UPDATE, DELETE. Next-key locking provides repeatable reads for SELECT FOR UPDATE, INSERT, UPDATE, DELETE. Next key locks are implemented by locking index entries and the lock implies that the gap to the previous index entry is also locked. The use of “current” rather than “consistent” reads for INSERT, UPDATE, DELETE can cause surprises. For example a transaction might do SELECT to figure out what rows might match and then when an UPDATE is done with the same WHERE clause the matched rows can differ.»
Алексей, спасибо за статью! Отлично, что прорвались, наконец, через хабрадебри, плюсанул в карму.
Прокомментируйте, пожалуйста, — актуально ли вот это для новых версий? Это о myisam речь или шире?
twitter.com/sgrif/status/656167420290199553
twitter.com/zzashpaupat/status/656418345382711296
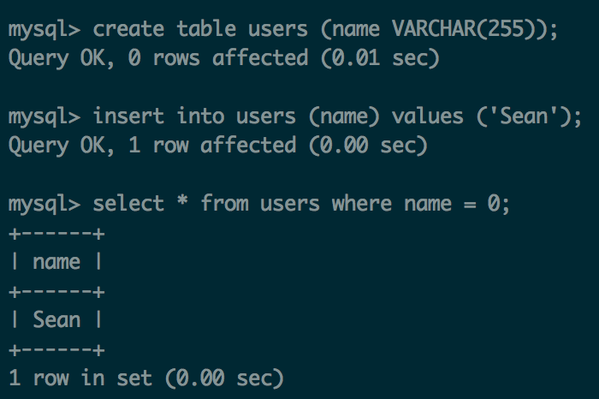

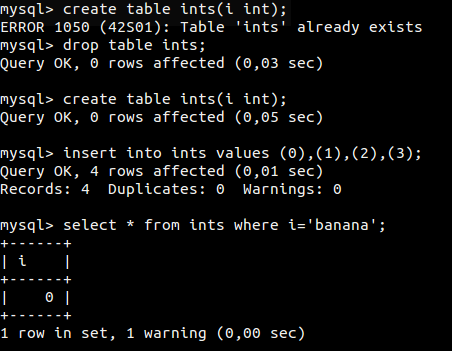
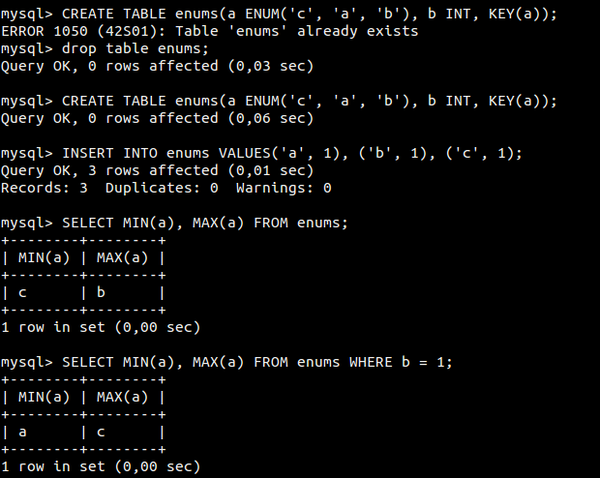
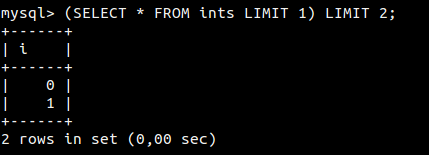
Прокомментируйте, пожалуйста, — актуально ли вот это для новых версий? Это о myisam речь или шире?
twitter.com/sgrif/status/656167420290199553
twitter.com/zzashpaupat/status/656418345382711296
Скажу честно — многие примеры скопипастил из прошлогодней статьи.
Выполнял на версии 5.6.25-0ubuntu0.15.04.1
Выполнял на версии 5.6.25-0ubuntu0.15.04.1
Спасибо, Николай! Да, тут уже приводили ссылку на статью, откуда это взято. Как я уже написал, это вполне тянет на вторую серию «памятки евангелиста». Но совсем вкратце ответить можно так: друзья, читайте документацию. Есть правила, они известны и документированы. Тот факт, что где-то работают другие правила, или то, что вам поведение кажется неинтуитивным, само по себе не тянет на те выводы, которые из этих фактов обычно делают.
Это называется gotchas, которые есть и в PostgreSQL, но я ни разу не видел твиты с копипейстом из PostgreSQL gotchas и подписью «why to use MySQL».
Это называется gotchas, которые есть и в PostgreSQL, но я ни разу не видел твиты с копипейстом из PostgreSQL gotchas и подписью «why to use MySQL».
Спасибо, Николай! Да, тут уже приводили ссылку на статью, откуда это взято. Как я уже написал, это вполне тянет на вторую серию «памятки евангелиста»
Да-да, когда их тыкают носом в очевидную ущербность их продукта, евангелисты mysql бегут писать памятки, как правильно критиковать mysql :)
К вопросу о том, кто что видел: почему я ни разу не видел подобных статей от евангелистов PHP, который только ленивый не пнул за аналогичное отвратительное (хотя и тоже задокументированное) неявное преобразование типов?
Впрочем, с нетерпением жду статьи.
bfy.tw/2OKe
www.creativebloq.com/netmag/debunking-phps-bad-reputation-9116801
Теперь вы видели всё. Не благодарите.
www.creativebloq.com/netmag/debunking-phps-bad-reputation-9116801
Теперь вы видели всё. Не благодарите.
Посылу в «let me google that fot you» я обязан саркастическому тону нашей беседы, который задал, безусловно, я. Виноват.
Однако, уж если послали, пробовали сами сходить по предложенному адресу?
Пройдусь по первой странице:
1. sql-info.de/postgresql/postgres-gotchas.html
Старенькая статья, в которой, что смешно, большая часть пунктов уже вычеркнута автором как неактуальная, а многие по моему скромному мнению тяжело отнести к разряду gotcha (Unquoted object names fold to lower case, PostgreSQL can't multiply 256 * 256 * 256 * 256, Upgrades).
Да и пунктов там набралось как-то немного — у того же автора есть статья и про mysql. Сравните сами, что называется (да, я знаю, что там про 4.1).
2. wiki.postgresql.org/wiki/PostgreSQL_Gotchas
Тоже весело: ссылка на оф вики постгреса с описанием 1 (одной! несмотря на множественное число) проблемы. Тут, впрочем, не спорю, gotcha — поведение не интуитивное.
3. www.nws.noaa.gov/oh/hrl/hseb/postgreSQL/Conversion_Gotchas.doc
Описание некоторых отличий постгреса для мигрантов с Informix
4. stackoverflow.com/questions/772111/switching-from-mysql-to-postgresql-tips-tricks-and-gotchas
То же для переходящих с mysql
5. engineering.coachup.com/postgres-null-comparison-gotcha
Человек открыл для себя понятие NULL в SQL. Виноват постгрес
6. www.depesz.com/2007/09/06/postgresql-gotchas
Евангелист постгреса рассказывает, какие бывают дурацкие ошибки у пользователя
7. johtopg.blogspot.com/2014/05/postgresql-gotcha-of-week-week-19.html
Ну наконец-то, реальная хитрая gotcha!
8. www.perlmonks.org/bare/?node_id=101762
Не особо интересные заметки перл-программиста, как в mysql что-то работает так, а в pg эдак
9. www.quora.com/What-are-the-must-know-concepts-gotchas-in-PostgreSQL
Вопрос на quora. Ноль ответов
10. linuxfestnorthwest.org/2015/sessions/postgresql-procedural-languages-tips-tricks-and-gotchas
Анонс лекции о процедурных языках в pg
Негусто, правда?
Если серьезно, то вы делаете правильное дело. Интересно и полезно разобраться в текущем положении дел с mysql, где-то отказаться от устаревших предрассудков, понять, в каком направлении оно движется, тем более из первых рук разработчиков. Так что я не шутил насчет «жду статьи». Но разберут ее по косточкам; выехать на том, что 0 = 'Sean' — документированное поведение, не получится, не обессудьте :)
Однако, уж если послали, пробовали сами сходить по предложенному адресу?
Пройдусь по первой странице:
1. sql-info.de/postgresql/postgres-gotchas.html
Старенькая статья, в которой, что смешно, большая часть пунктов уже вычеркнута автором как неактуальная, а многие по моему скромному мнению тяжело отнести к разряду gotcha (Unquoted object names fold to lower case, PostgreSQL can't multiply 256 * 256 * 256 * 256, Upgrades).
Да и пунктов там набралось как-то немного — у того же автора есть статья и про mysql. Сравните сами, что называется (да, я знаю, что там про 4.1).
2. wiki.postgresql.org/wiki/PostgreSQL_Gotchas
Тоже весело: ссылка на оф вики постгреса с описанием 1 (одной! несмотря на множественное число) проблемы. Тут, впрочем, не спорю, gotcha — поведение не интуитивное.
3. www.nws.noaa.gov/oh/hrl/hseb/postgreSQL/Conversion_Gotchas.doc
Описание некоторых отличий постгреса для мигрантов с Informix
4. stackoverflow.com/questions/772111/switching-from-mysql-to-postgresql-tips-tricks-and-gotchas
То же для переходящих с mysql
5. engineering.coachup.com/postgres-null-comparison-gotcha
Человек открыл для себя понятие NULL в SQL. Виноват постгрес
6. www.depesz.com/2007/09/06/postgresql-gotchas
Евангелист постгреса рассказывает, какие бывают дурацкие ошибки у пользователя
7. johtopg.blogspot.com/2014/05/postgresql-gotcha-of-week-week-19.html
Ну наконец-то, реальная хитрая gotcha!
8. www.perlmonks.org/bare/?node_id=101762
Не особо интересные заметки перл-программиста, как в mysql что-то работает так, а в pg эдак
9. www.quora.com/What-are-the-must-know-concepts-gotchas-in-PostgreSQL
Вопрос на quora. Ноль ответов
10. linuxfestnorthwest.org/2015/sessions/postgresql-procedural-languages-tips-tricks-and-gotchas
Анонс лекции о процедурных языках в pg
Негусто, правда?
Если серьезно, то вы делаете правильное дело. Интересно и полезно разобраться в текущем положении дел с mysql, где-то отказаться от устаревших предрассудков, понять, в каком направлении оно движется, тем более из первых рук разработчиков. Так что я не шутил насчет «жду статьи». Но разберут ее по косточкам; выехать на том, что 0 = 'Sean' — документированное поведение, не получится, не обессудьте :)
Суть этого вашего комментария поразительно напоминает суть статьи, только про другую СУБД.
Давайте поспорим :)
Не о том, конечно, что кому что напоминает — соль тут именно в аргументации.
Так, я, например, хоть убей, не считаю «gotcha» то, что идентификаторы в PG приводятся к нижнему регистру. По стандарту SQL — регистронезависимый язык (хотя идентификаторы и должны приводиться к верхнему регистру, так, например, делает Oracle). А в mysql как всегда красота: case sensitivity of the underlying operating system plays a part in the case sensitivity of database and table names (не знал сам, полез смотреть и сижу в позе «фейспалм»).
Не о том, конечно, что кому что напоминает — соль тут именно в аргументации.
Так, я, например, хоть убей, не считаю «gotcha» то, что идентификаторы в PG приводятся к нижнему регистру. По стандарту SQL — регистронезависимый язык (хотя идентификаторы и должны приводиться к верхнему регистру, так, например, делает Oracle). А в mysql как всегда красота: case sensitivity of the underlying operating system plays a part in the case sensitivity of database and table names (не знал сам, полез смотреть и сижу в позе «фейспалм»).
Ну то есть мы от «очевидной ущербности» MySQL плавно перешли к подсчёту gotchas. Честно скажу, считать их мы устанем — что-то устарело, кто-то где-то просто не разобрался и т.д.
Но мы же не против критики как таковой, мы за грамотную критику, правильно? Если, скажем, в MySQL мы насчитаем X gotchas и от этого он «очевидно ущербный», а в PostgreSQL мы насчитаем, ну пусть X/2 gotchas, то как будет грамотно называть PostgreSQL: «неочевидно ущербный» или «наполовину ущербный»? Теряюсь в догадках.
Но мы же не против критики как таковой, мы за грамотную критику, правильно? Если, скажем, в MySQL мы насчитаем X gotchas и от этого он «очевидно ущербный», а в PostgreSQL мы насчитаем, ну пусть X/2 gotchas, то как будет грамотно называть PostgreSQL: «неочевидно ущербный» или «наполовину ущербный»? Теряюсь в догадках.
Точно такие же gotchas есть и в JavaScript, и их обсуждают, шутят над выносящей мозг логикой сравнения, приведения типов и т.д. Только для JavaScript альтернативы особой нет. А вот в случае с MySQL — есть.
Кстати, был бы благодарен, если бы вы привели несколько примеров для PostgreSQL, чтобы быть начеку, если что.
Кстати, был бы благодарен, если бы вы привели несколько примеров для PostgreSQL, чтобы быть начеку, если что.
И кстати про репликацию и чем плоха логическая репликация. У меня сейчас залипла репликация между Master и Slave. Причина банальна. От Master каким-то чудным образом была потеряна операция Commit. В итоге логи льются, а база не синкается. В PostgreSQL такой фигни быть не могло. Так-как используются физические журналы.
! эх, по логике сюжета надо писать ответный пост.
но моя карма ниже плинтуса самого низкого)
хотя, есть какой-то «рекавери мод», хм, значит вроде можно.
но моя карма ниже плинтуса самого низкого)
хотя, есть какой-то «рекавери мод», хм, значит вроде можно.
В пункте №1, про legacy вы приводите в пример «Github, Wikipedia, Google, Facebook, Twitter, LinkedIn, Alibaba, Taobao, Booking.com, AirBnB, Dropbox, Pinterest, GroupOn, Yelp» как бы пытаясь опровергнуть базовое утверждение. Но это как раз есть legacy. Мы не знаем, выбрали бы эти фирмы MySQL, если бы выбор нужно было делать снова.
Под legacy обычно понимают системы, которые были созданы давно, и в данный момент активно не развиваются по тем или иным причинам. Я думаю, не стоит объяснять, почему перечисленные проекты и компании под эту категорию не попадают?
Кроме того, в крупных компаниях и проектах обычно не стесняются переходить на новые технологии тогда, когда это имеет какой-то технический смысл. В каждой из перечисленных компаний MySQL вовсе не является единственной используемой СУБД. Но, как я написал, играет ключевые роли в инфраструктуре.
Кроме того, в крупных компаниях и проектах обычно не стесняются переходить на новые технологии тогда, когда это имеет какой-то технический смысл. В каждой из перечисленных компаний MySQL вовсе не является единственной используемой СУБД. Но, как я написал, играет ключевые роли в инфраструктуре.
В крупных компаниях никогда не станут менять БД в работающем проекте, пока остается хоть малейшая возможность этого не делать.
Добавил в вопрос про MVCC ссылку на https://github.com/ept/hermitage
В разделе про клиенты командной строки добавил ссылку на MySQL Shell, где появилась поддержка автодополнения для SQL.
Добавил текст про поддержку CTE и оконных функций в MySQL 8.0 и результаты тестирования Маркуса Винанда.
Да, сайт он пока не обновил, но на то он и евангелист ;) Табличка взята из его твиттера: twitter.com/MarkusWinand/status/852862475699707904
Добавил абзац про новые возможности GIS в MySQL 8.0.
Sign up to leave a comment.
Памятка евангелиста PostgreSQL: критикуем MySQL грамотно