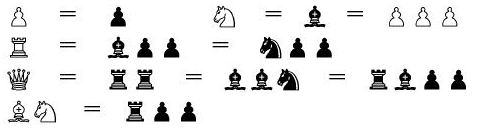
Здравствуй, Хабр!
В этой статье речь пойдёт о небольшом программистском этюде на тему машинного обучения. Замысел его возник у меня при прохождении известного здесь многим курса
«Machine Learning», читаемого Andrew Ng на Курсере. После знакомства с методами, о которых рассказывалось на лекциях, захотелось применить их к какой-нибудь реальной задаче. Долго искать тему не пришлось — в качестве предметной области просто напрашивалась оптимизация собственного шахматного движка.
Вступление: о шахматных программах
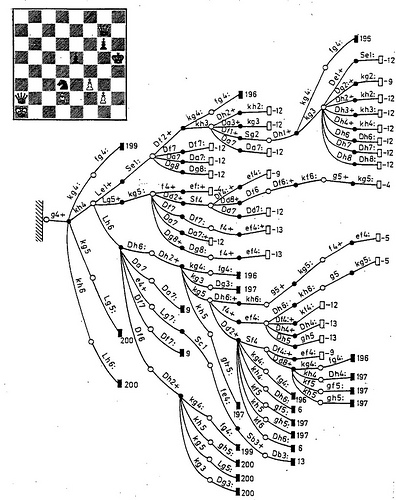
Не будем детально углубляться в архитектуру шахматных программ — это могло бы стать темой отдельной публикации или даже их серии. Рассмотрим только самые базовые принципы. Основными компонентами практически любого небелкового шахматиста являются
поиск и
оценка позиции.
Поиск представляет собой перебор вариантов, то есть итеративное углубление по дереву игры. Оценочная функция отображает набор позиционных признаков на числовую шкалу и служит целевой функцией для поиска наилучшего хода. Она применяется к листьям дерева, и постепенно «возвращается» к исходной позиции (корню) с помощью
альфа-бета процедуры или её вариаций.
Строго говоря,
настоящая оценка может принимать только три значения: выигрыш, проигрыш или ничья — 1, 0 или ½. По
теореме Цермело для любой заданной позиции она определяется однозначно. На практике же из-за комбинаторного взрыва ни один компьютер не в состоянии просчитать варианты до листьев полного дерева игры (исчерпывающий анализ в эндшпильных базах данных — это отдельный случай; 32-фигурных таблиц в обозримом будущем не появится… и в необозримом, скорее всего, тоже). Поэтому программы работают в так называемой
модели Шеннона — пользуются усечённым деревом игры и приближённой оценкой, основанной на различных эвристиках.






 Хабр, привет.
Хабр, привет.





