Недавно я глубоко погрузился в тему архивирования веб-сайтов. Меня попросили друзья, которые боялись потерять контроль над своими работами в интернете из-за плохого системного администрирования или враждебного удаления. Такие угрозы делают архивирование веб-сайтов важным инструментом любого сисадмина. Как оказалось, некоторые сайты гораздо сложнее архивировать, чем другие. Эта статья демонстрирует процесс архивирования традиционных веб-сайтов и показывает, как он не срабатывает на модных одностраничных приложениях, которые раздувают современный веб.

Владислав Щапов @phprus
Манул
СХД для HPC-инфраструктуры, или Как мы собрали 65 ПБ хранения в японском исследовательском центре RIKEN
5 min

datacenterknowledge.com
В прошлом году была реализована самая крупная на данный момент инсталляция СХД на базе RAIDIX. Система из 11 отказоустойчивых кластеров была развернута в Центре вычислительных наук института RIKEN (Япония). Основное назначение системы — хранилище для инфраструктуры HPC (HPCI), которая реализована в рамках масштабного национального проекта по обмену академической информацией Academic Cloud (на базе сети SINET).
Знаковой характеристикой этого проекта является его суммарный объем — 65 ПБ, из которых полезный объем системы составляет 51,4 ПБ. Чтобы точнее понять эту величину, добавим, что это 6512 дисков по 10 ТБ (самых современных на момент установки). Это много.
C++20 и Modules, Networking, Coroutines, Ranges, Graphics. Итоги встречи в Сан-Диего
8 min
До C++20 осталась пара лет, а значит, не за горами feature freeze. В скором времени международный комитет сосредоточится на причёсывании черновика C++20, а нововведения будут добавляться уже в C++23.
Ноябрьская встреча в Сан-Диего — предпоследняя перед feature freeze. Какие новинки появятся в C++20, что из крупных вещей приняли, а что отклонили — всё это ждёт вас под катом.

Ноябрьская встреча в Сан-Диего — предпоследняя перед feature freeze. Какие новинки появятся в C++20, что из крупных вещей приняли, а что отклонили — всё это ждёт вас под катом.
Ceph. Анатомия катастрофы
20 min
Ceph — это object storage, призванный помочь построить отказоустойчивый кластер. И все-таки отказы случаются. Все, кто работает с Ceph, знают легенду о CloudMouse или Росреестре. К сожалению, делиться отрицательным опытом у нас не принято, причины провалов чаще всего замалчивают, и не дают будущим поколениям научиться на чужих ошибках.
Что ж, настроим тестовый, но близкий к реальному кластер и разберем катастрофу по косточкам. Измерим все просадки производительности, найдем утечки памяти, разберем процесс восстановления обслуживания. И все это под руководством Артемия Капитулы, который потратив почти год на изучение подводных камней, заставил при отказе производительность кластера не падать в ноль, и latency не подскакивать до неприличных значений. И получил красный график, который ну сильно лучше.
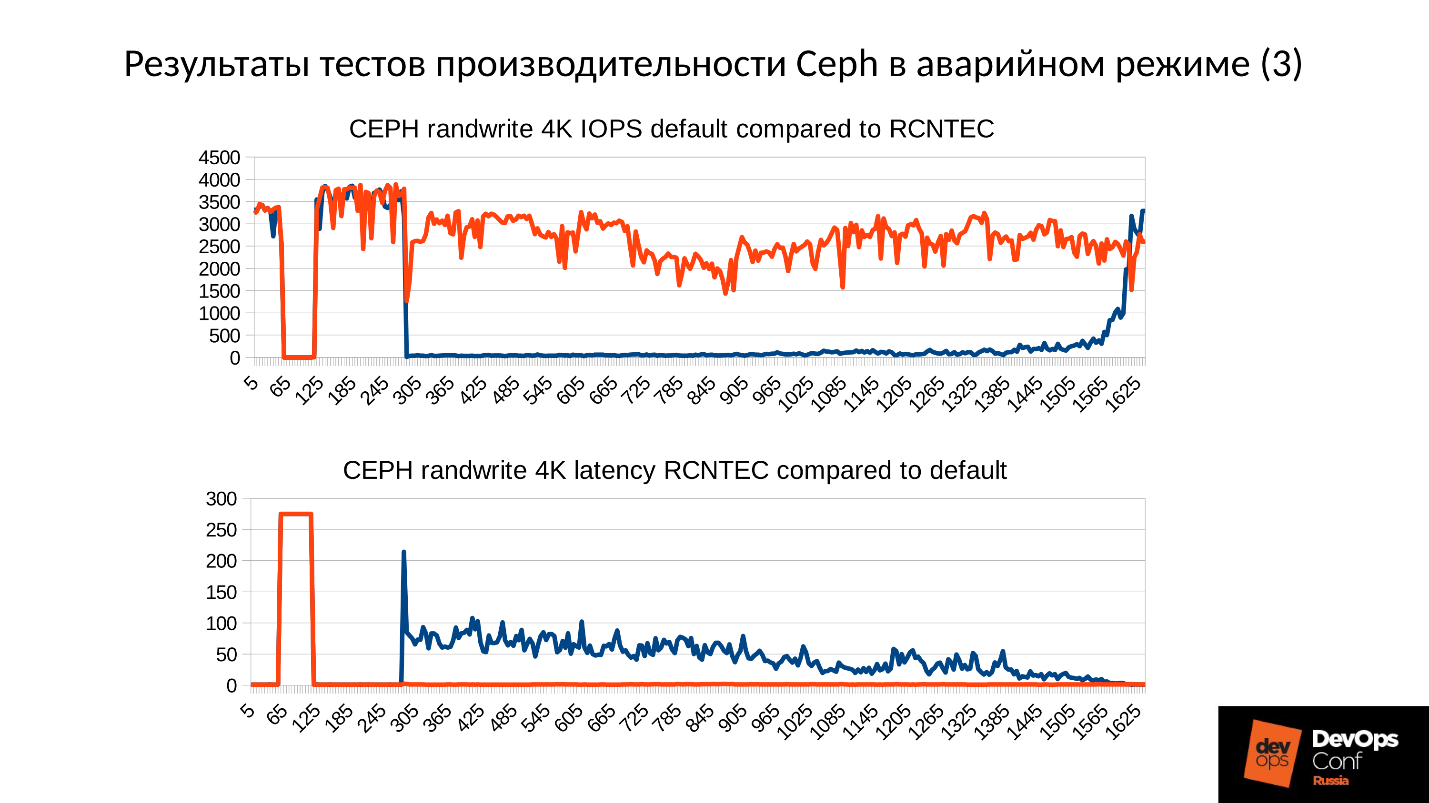
Далее вы найдете видео и текстовую версию одного из лучших докладов DevOpsConf Russia 2018.
Что ж, настроим тестовый, но близкий к реальному кластер и разберем катастрофу по косточкам. Измерим все просадки производительности, найдем утечки памяти, разберем процесс восстановления обслуживания. И все это под руководством Артемия Капитулы, который потратив почти год на изучение подводных камней, заставил при отказе производительность кластера не падать в ноль, и latency не подскакивать до неприличных значений. И получил красный график, который ну сильно лучше.
Далее вы найдете видео и текстовую версию одного из лучших докладов DevOpsConf Russia 2018.
Невызванная функция замедляет программу в 5 раз
5 min
Translation
Замедляем Windows, часть 3: завершение процессов

Автор занимается оптимизацией производительности Chrome в компании Google — прим. пер.
Летом 2017 года я боролся с проблемой производительности Windows. Завершение процессов происходило медленно, сериализованно и блокировало системную очередь ввода, что приводило к многократным подвисаниям курсора мыши при сборке Chrome. Основная причина заключалась в том, что при завершении процессов Windows тратила много времени на поиск объектов GDI, удерживая при этом критическую секцию system-global user32. Я рассказывал об этом в статье «24-ядерный процессор, а я не могу сдвинуть курсор».
Microsoft исправила баг, и я вернулся к своим делам, но потом оказалось, что баг вернулся. Появились жалобы на медленную работу тестов LLVM, с частыми подвисаниями ввода.
Но на самом деле баг не вернулся. Причина оказалась в изменении нашего кода.
Автор занимается оптимизацией производительности Chrome в компании Google — прим. пер.
Летом 2017 года я боролся с проблемой производительности Windows. Завершение процессов происходило медленно, сериализованно и блокировало системную очередь ввода, что приводило к многократным подвисаниям курсора мыши при сборке Chrome. Основная причина заключалась в том, что при завершении процессов Windows тратила много времени на поиск объектов GDI, удерживая при этом критическую секцию system-global user32. Я рассказывал об этом в статье «24-ядерный процессор, а я не могу сдвинуть курсор».
Microsoft исправила баг, и я вернулся к своим делам, но потом оказалось, что баг вернулся. Появились жалобы на медленную работу тестов LLVM, с частыми подвисаниями ввода.
Но на самом деле баг не вернулся. Причина оказалась в изменении нашего кода.
Любая интернет-компания обязана тайно изменить программный код по требованию властей
6 min
Любая интернет-компания обязана тайно изменить программный код по требованию властей
 6 декабря 2018 года парламент Австралии принял Assistance and Access Bill 2018 — поправки к Telecommunications Act 1997 о правилах оказания услуг электросвязи.
6 декабря 2018 года парламент Австралии принял Assistance and Access Bill 2018 — поправки к Telecommunications Act 1997 о правилах оказания услуг электросвязи.Говоря юридическим языком, эти поправки «устанавливают нормы для добровольной и обязательной помощи телекоммуникационных компаний правоохранительным органам и спецслужбам в отношении технологий шифрования после получения запросов на техническую помощь».
По сути это аналог российского «закона Яровой», который требует от интернет-компаний обязательной расшифровки трафика по запросу правоохранительных органов. В отдельных моментах австралийский закон даже более суровый, чем российский. Некоторые эксперты недоумевают, как такое законодательство вообще могло быть принято в демократической стране и называют его «опасным прецедентом».
Достижение максимальной производительности Быстрого Преобразования Фурье на основе управления данными
1 min
Recovery Mode
Статья поддерживается здесь:
[3] Caterpillar Implementation Based on Generated Code
// не вижу смысла писать на ресурсе а) с цензурой тэгов б) где каждый проходящий бот, набравший рейтинг галиматьей, сносит твой рейтинг и объяснение причины с него не требуется
[3] Caterpillar Implementation Based on Generated Code
// не вижу смысла писать на ресурсе а) с цензурой тэгов б) где каждый проходящий бот, набравший рейтинг галиматьей, сносит твой рейтинг и объяснение причины с него не требуется
Восстановление смазанных и расфокусированных изображений с помощью фильтра Винера. Реализация на C++ OpenCV
2 min
В продолжении статьи про восстановление расфокусированных и смазанных изображений хочу поделиться своими результатами восстановления реальных изображений с помощью фильтра Винера. В качестве библиотеки обработки изображений использовалась OpenCV 3.4. Фотокамера – Nikon D320, объектив Nikon DX AF-S NIKKOR 18-105mm, расфокусировка осуществлялась вручную, съёмка осуществлялась без штатива.
Самые быстрые числа с плавающей запятой на диком западе
5 min
В процессе реализации одной «считалки» возникла проблема с повышенной точностью вычислений. Расчетный алгоритм работал быстро на стандартных числах с плавающей запятой, но когда подключались библиотеки для точных вычислений, все начинало дико тормозить. В этой статье будут рассмотрены алгоритмы расширения чисел с плавающей запятой с помощью мультикомпонентного подхода, благодаря которому удалось достичь ускорения, так как float арифметика реализована на кристалле цп. Данный подход будет полезен для более точного вычисления численной производной, обращение матриц, обрезке полигонов или других геометрических задач. Так возможна эмуляции 64bit float на видеокартах, которые их не поддерживают.
LoJax: первый известный UEFI руткит, используемый во вредоносной кампании
25 min
Кибергруппа Sednit, также известная как АРТ28, Strontium и Fancy Bear, работает как минимум с 2004 года. Считается, что группа стоит за рядом резонансных кибератак. Некоторые ИБ-компании и Министерство юстиции США назвали Sednit ответственной за взлом Национального комитета Демократической партии перед выборами в США в 2016 году. Группе приписывают взлом глобальной телевизионной сети TV5Monde, утечку электронных писем Всемирного антидопингового агентства (WADA) и другие инциденты. У Sednit множество целей и широкий спектр инструментов, некоторые из которых мы уже задокументировали ранее, но в этой работе мы впервые детально опишем применение UEFI руткита.

Генерация трафика в юзерспейсе
11 min
Генерация трафика посредством MoonGen + DPDK + Lua в представлении художника
Нейтрализация DDoS-атак в реальных условиях требует предварительных тестирования и проверки различных техник. Сетевое оборудование и ПО должно быть протестировано в искусственных условиях близких к реальным — с интенсивными потоками трафика, имитирующего атаки. Без таких экспериментов крайне затруднительно получить достоверную информацию о специфических особенностях и ограничениях, имеющихся у любого сложного инструмента.
В данном материале мы раскроем некоторые методы генерации трафика, используемые в Qrator Labs.
ПРЕДУПРЕЖДЕНИЕ
Мы настойчиво рекомендуем читателю не пытаться использовать упомянутые инструменты для атак на объекты реальной инфраструктуры. Организация DoS-атак преследуется по закону и может вести к суровому наказанию. Qrator Labs проводит все тесты в изолированном лабораторном окружении.
Пара иногда востребованных хитростей при работе с git
6 min
Tutorial
Хочу поделиться рецептами решения пары задач, которые иногда возникают при работе с git, и которые при этом не "прямо совсем очевидны".
Сперва я думал накопить подобных рецептов побольше, однако всему своё время. Думаю, если есть польза, то можно и понемногу...
Итак...
Разработчики остались неизвестны. Лекция Яндекса
15 min
Этот доклад руководителя группы разработки ClickHouse Алексея Миловидова представляет собой обзор мало кому известных СУБД. Некоторые из них устарели, некоторые прекратили свое развитие и заброшены. Алексей обращает внимание на интересные архитектурные решения в перечисленных примерах, разбирается в их судьбе и объясняет, каким требованиям должен отвечать ваш опенсорс-проект.
— Мой доклад будет про базы данных. Позвольте сразу спросить, схема метрополитена какого города изображена на этом слайде? Все линии идут в одну сторону.
— Мой доклад будет про базы данных. Позвольте сразу спросить, схема метрополитена какого города изображена на этом слайде? Все линии идут в одну сторону.
Проектные нормы в микроэлектронике: где на самом деле 7 нанометров в технологии 7 нм?
12 min
Современные микроэлектронные технологии — как «Десять негритят». Стоимость разработки и оборудования так велика, что с каждым новым шагом вперёд кто-то отваливается. После новости об отказе GlobalFoundries от разработки 7 нм их осталось трое: TSMC, Intel и Samsung. А что такое, собственно “проектные нормы” и где там тот самый заветный размер 7 нм? И есть ли он там вообще?

Рисунок 1. Транзистор Fairchild FI-100, 1964 год.
Самые первые серийные МОП-транзисторы вышли на рынок в 1964 году и, как могут увидеть из рисунка искушенные читатели, они почти ничем не отличались от более-менее современных — кроме размера (посмотрите на проволоку для масштаба).
Рисунок 1. Транзистор Fairchild FI-100, 1964 год.
Самые первые серийные МОП-транзисторы вышли на рынок в 1964 году и, как могут увидеть из рисунка искушенные читатели, они почти ничем не отличались от более-менее современных — кроме размера (посмотрите на проволоку для масштаба).
Просто и качественно определяем язык сообщений
6 min
Tutorial

У нас в компании YouScan в день обрабатывается около 100 млн. сообщений, на которых применяется много правил и разных смарт-функций. Для корректной их работы нужно правильно определить язык, потому что не все функции можно сделать агностическими относительно языка. В данной статье мы коротко расскажем про наше исследование данной задачи и покажем оценку качества на датасете из соц. сетей.
Борьба за ресурсы, часть 2: Играемся с настройками Cgroups
5 min
Мы начали изучать Control Groups (Cgroups) в Red Hat Enterprise Linux 7 – механизм уровня ядра, позволяющий управлять использованием системных ресурсов, кратко рассмотрели теоретические основы и теперь переходим к практике управления ресурсами CPU, памяти и ввода-вывода.

Однако, прежде чем что-то менять, всегда полезно узнать, как все устроено сейчас.
Однако, прежде чем что-то менять, всегда полезно узнать, как все устроено сейчас.
Борьба за ресурсы, часть 1: Основы Cgroups
5 min
Компьютеры – это «железо». И сегодня мы вернулись в исходную точку, в том смысле, что сейчас редко найдешь физический хост, на котором выполняется одна единственная задача. Даже если на сервере крутится только одно приложение, оно, скорее всего, состоит из нескольких процессов, контейнеров или даже виртуальных машин (ВМ), и все они работают на одном сервере. Red Hat Enterprise Linux 7 неплохо справляется с распределением системных ресурсов в таких ситуациях, но по умолчанию ведет себя как добрая бабушка, угощающая внуков домашним пирогом и приговаривающая: «Всем поровну, всем поровну».

В теории принцип «всем поровну», конечно, прекрасен, но на практике некоторые процессы, контейнеры или ВМ оказываются важнее других, и, следовательно, должны получать больше.
В теории принцип «всем поровну», конечно, прекрасен, но на практике некоторые процессы, контейнеры или ВМ оказываются важнее других, и, следовательно, должны получать больше.
Новый виток импортозамещения. Куда бежать и что делать?
10 min
Что такое импортозамещение в ИТ
Совсем кратко пробегусь по основным вопросам для синхронизации.
1. Что такое отечественное ПО и оборудование?
С юридической точки зрения российскими считаются те продукты, чьё российское происхождение подтвердили в Министерстве цифрового развития и в Минпромторге соответственно включением в свои реестры.
С конца 2017 г. согласно постановлению Правительства РФ №1594 ПО стран ЕврАзЭс не подпадает под определение «иностранного», но пока реестра евразийского программного обеспечения нет, то и использовать, например, белорусское ПО в качестве импортозамещающего нельзя.
Сразу оговорюсь, что пост больше — про ПО.
2. А оно реально произведено в РФ с нуля?
В некоторых случаях — да. Например, решения от Kaspersky или Abbyy.
В других за основу взято свободное программное обеспечение (СПО), и к нему применены собственные разработки. Сюда можно отнести, например, большинство российских ОС, МойОфис Почта и Яндекс.Браузер. Это не обязательно плохо. По этому пути изначально шли, например, Nutanix и Zimbra. Главное — быть уверенными, что производитель не организовал «сборку» под единственный проект и планирует поддерживать решение в будущем.
Иногда возникают курьёзные случаи. Решение разработано в России, но продаётся через иностранную компанию. В этом случае, чтобы попасть в реестр, приходится организовывать отдельную российскую фирму и делать форк продукта под российский рынок. Преимущество таких решений — оперативная техническая поддержка третьего уровня, привыкшая к работе по западным стандартам.
3. А если этого ПО недостаточно?
В реестре отечественного ПО присутствуют операционные системы (ОС) на базе ядра Linux. У каждой из этих ОС есть свой репозиторий. Поскольку формально приложения входят в состав ОС, так же как и службы Windows, то они считаются российскими, и за их поддержку отвечает производитель ОС.
4. Есть ли альтернативы?
Есть СПО, о котором я уже говорил. Но имеются нюансы.
Параллелизм в PostgreSQL: не сферический, не конь, не в вакууме
10 min

Масштабирование СУБД – это непрерывно наступающее будущее. СУБД совершенствуются и лучше масштабируются на аппаратных платформах, а сами аппаратные платформы наращивают производительность, число ядер, памяти — Ахиллес догоняет черепаху, но все еще не догнал. Проблема масштабирования СУБД стоит во весь рост.
Компании Postgres Professional с проблемой масштабирования довелось столкнуться не только теоретически, но и практически: у своих заказчиков. И не раз. Об одном из таких случаев и пойдёт речь в этой статье.
PostgreSQL неплохо масштабируется на NUMA-системах, если это одна материнская плата с несколькими процессорами и несколькими шинами данных. О некоторых оптимизациях можно почитать здесь и здесь. Однако есть и другой класс систем, у них несколько материнских плат, обмен данными между которыми осуществляется с помощью интерконнекта, при этом на них работает один экземпляр ОС и для пользователя такая конструкция выглядит как единая машина. И хотя формально такие системы можно также отнести к NUMA, но по своей сути они ближе к суперкомпьютерам, т.к. доступ к локальной памяти узла и доступ к памяти соседнего узла отличаются радикально. В сообществе PostgreSQL считают, что единственный экземпляр Postgres, работающий на таких архитектурах, это источник проблем, и системного подхода к их решению пока нет.
Портирование JS на Эльбрус
11 min
Это рассказ про портирование JavaScript на отечественную платформу Эльбрус, выполненное ребятами из компании UniPro. В статье — краткий сравнительный анализ платформ, детали процесса и подводные камни.

В основе статьи — доклад Дмитрия (dbezheckov) Бежецкова и Владимира (volodyabo) Ануфриенко с HolyJS 2018 Piter. Под катом вы найдете видео и текстовую расшифровку доклада.
В основе статьи — доклад Дмитрия (dbezheckov) Бежецкова и Владимира (volodyabo) Ануфриенко с HolyJS 2018 Piter. Под катом вы найдете видео и текстовую расшифровку доклада.