Всем привет. Сегодня я хочу поговорить о принципе PECS. Понимаю, что сейчас гуру программирования и многоопытные сеньоры в очередной раз впечатали ладонь в лицо, ибо «Java Generics появились в JDK 1.5, которая вышла 30 сентября 2004 года…». Но если есть те, для кого принцип PECS остаётся туманным и непонятным, а упорное гугленье только сгущает «туман», добро пожаловать под кат, будем вместе разбираться до полного духовного просветления. Хочу сразу предупредить, что в данной заметке не рассматривается, что такое дженерики и что такое wildcard. Если вы не знакомы с данными понятиями, то перед чтением необходимо с ними разобраться.

Мария @pythagoreantree
Java Developer
64-битный hashmap в JS
1 min
Как бы вы сделали быстрый hashmap для 64-битных ключей? Если ключи 32-битные, то вряд ли можно сделать что то быстрее чем встроенный ES6 Map, но если ключи 64 битные, то начинаются сложности потому что JS застрял на 32-битном int.
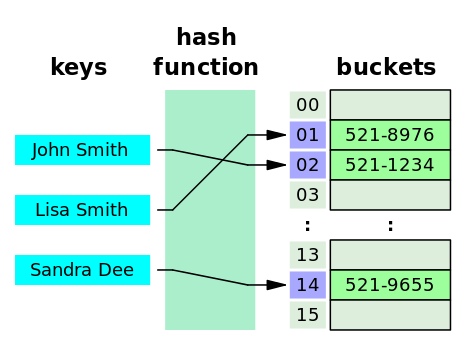
Префиксные деревья в Python
6 min
Доделал на днях питонью библиотеку datrie, реализующую префиксное дерево (см. википедию или хабр), спешу поделиться.
Если вкратце, то можно считать, что datrie.Trie — это замена стандартному питоньему dict, которая при определенных условиях (ключи — строки) занимает меньше памяти, имеет сравнимую скорость получения отдельного элемента и поддерживает дополнительные операции (получение всех префиксов данной строки, получение всех строк, начинающихся с данной строки и др.), которые работают примерно так же быстро, как и «словарные» операции.
Работает под Python 2.6-3.3, поддерживает юникод, лицензия LGPL.
Если вкратце, то можно считать, что datrie.Trie — это замена стандартному питоньему dict, которая при определенных условиях (ключи — строки) занимает меньше памяти, имеет сравнимую скорость получения отдельного элемента и поддерживает дополнительные операции (получение всех префиксов данной строки, получение всех строк, начинающихся с данной строки и др.), которые работают примерно так же быстро, как и «словарные» операции.
Работает под Python 2.6-3.3, поддерживает юникод, лицензия LGPL.
Персистентные деревья отрезков
4 min
Введение
Структуры данных можно разделить на две группы: эфемерные (ephemeral) и персистентные (persistent).
Эфемерными называются структуры данных, хранящие только последнюю свою версию.
Персистентные структуры, то есть те, которые сохраняют все свои предыдущие версии, в свою очередь можно разделить еще на две подгруппы: если структура данных, позволяет изменять только последнюю версию, она называется частично персистентной (partially persistent), если же позволяется изменять любую версию, такая структура считается полностью персистентной (fully persistent).
Далее будет рассмотрено дерево отрезков и его полностью персистентная версия.
Весь код доступен на GitHub.
Как работает ConcurrentHashMap
5 min
В октябре на хабре появилась замечательная статья про работу HashMap. Продолжая данную тему, я собираюсь рассказать о реализации java.util.concurrent.ConcurrentHashMap.
Итак, как же появился ConcurrentHashMap, какие у него есть преимущества и как он был реализован.
Итак, как же появился ConcurrentHashMap, какие у него есть преимущества и как он был реализован.
Дерево отрезков
5 min
Я расскажу о структуре под названием дерево отрезков и приведу его простую реализацию на языке С++. Эта структура весьма полезна в случаях, когда необходимо часто искать значение какой-то функции на отрезках линейного массива и иметь возможность быстро изменять значения группы подряд идущих элементов.
Типичный пример задачи на дерево отрезков:
Есть линейный массив, изначально заполненный некоторыми данными. Далее приходят 2 типа запросов:
1й тип — найти значение максимального элемента на отрезке массива [a..b].
2й тип — заменить iй элемент массива на x.
Возможен запрос «добавить х ко всем элементам на отрезке [a..b]», но в данной статье я его не рассматриваю.
С помощью дерева отрезков можно искать не только максимум чисел, но и любую функцию, удовлетворяющую свойству ассоциативности.
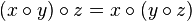
Это ограничение связано с тем, что используется предпросчет значений для некоторых отрезков.
Типичный пример задачи на дерево отрезков:
Есть линейный массив, изначально заполненный некоторыми данными. Далее приходят 2 типа запросов:
1й тип — найти значение максимального элемента на отрезке массива [a..b].
2й тип — заменить iй элемент массива на x.
Возможен запрос «добавить х ко всем элементам на отрезке [a..b]», но в данной статье я его не рассматриваю.
С помощью дерева отрезков можно искать не только максимум чисел, но и любую функцию, удовлетворяющую свойству ассоциативности.
Это ограничение связано с тем, что используется предпросчет значений для некоторых отрезков.
Свой инструмент нужно знать в лицо: обзор наиболее часто используемых структур данных
8 min
Некоторое время назад я сходил на собеседование в одну довольно большую и уважаемую компанию. Собеседование прошло хорошо и понравилось как мне, так и, надеюсь, людям его проводившим. Но на следующий день, в процессе разбора полетов, я обнаружил, что в ходе собеседования ответ на как минимум один вопрос был неверен.
Вопрос: Почему поиск в python dict на больших объемах данных быстрее чем итерация по индексированному массиву?
Ответ: В dict хранятся хэши от ключей. Каждый раз, когда мы ищем в dict значение по ключу, мы сначала вычисляем его хэш, а потом (внезапно), выполняем бинарный поиск. Таким образом, сложность составляет O(lg(N))!
На самом деле никакого бинарного поиска тут нет. И сложность алгоритма не O(lg(N)), а Amort. O(1) — так как в основе dict питона лежит структура под названием Hash Table.
Причиной неверного ответа было то, что я не удосужился досконально изучить те структуры, которые лежат в основе работы с коллекциями моего любимого языка. Правда, по результатам опроса нескольких знакомых разработчиков, оказалось что это не только моя проблема, очень многие вообще не задумываются, как работают коллекции в их любимых ЯП. А ведь используем мы их каждый день и не по разу. Так родилась идея этой статьи.
Дерево ван Эмде Боаса
6 min
 Всем доброго времени суток!
Всем доброго времени суток!Сегодня я расскажу вам об одной интересной структуре данных, про которую слышали лишь немногие и про которую очень незаслуженно мало написано в рунете, да и в англоязычном информации, в общем-то, тоже негусто. Решено было исправить ситуацию и поделиться с общественностью в доступной форме этой достаточно экзотической структурой данных.
Дерево ван Эмде Боаса (van Emde Boas tree) — ассоциативный массив, который позволяет хранить целые числа в диапазоне [0; U), где U = 2k, проще говоря, числа, состоящие не более чем из k бит. Казалось бы, зачем нужно еще какое-то дерево, да еще позволяющее хранить только целые числа, когда существует множество различных сбалансриованных двоичных деревьев поиска, позволяющих выполнять операции вставки, удаления и прочие за O(log n), где n — количество элементов в дереве?
Главная особенность этой структуры — выполнение всех операций за время O(log(log(U))) независимо от количества хранящихся в ней элементов.
AVL деревья и широта их применения
3 min
Решил немного описать на мой взгляд самую полезную древовидную структуру. AVL дерево это бинарное дерево (у каждой вершины не более 2 сыновей), в котором каждой вершине присвоен идентификатор (как раз его и хранит дерево), идентификаторы подчиняются следующему правилу: ID левого сына<ID родителя<ID правого сына.
Т.е. если обходить дерево рекурсивно слева направо получим отсортированный по возрастанию список ID, справа налево – по убыванию.
Причем дерево максимально сбалансировано: высота левого поддерева отличается от высоты правого максимум на 1.
Интересно в нем то, что тогда на проверку существования элемента в дереве уходит log(N) N – количество ID. Ведь надо пройти от корня вниз, а поскольку дерево максимально симметрично то его высота — log(N)+1
Хорошая новость – нам никто не запрещает прикрепить к вершине еще какие-то полезные данные и тогда выборка произвольных данных по ID будет занимать log(N) времени
Плохая новость – одинаковые ID как следует из определения в нем существовать не могут. Придется делать финт ушами, один способ сделать вместо каждой вершины список вершин с одинаковым ID, другой – изменить алгоритм балансировки.
Т.е. если обходить дерево рекурсивно слева направо получим отсортированный по возрастанию список ID, справа налево – по убыванию.
Причем дерево максимально сбалансировано: высота левого поддерева отличается от высоты правого максимум на 1.
Интересно в нем то, что тогда на проверку существования элемента в дереве уходит log(N) N – количество ID. Ведь надо пройти от корня вниз, а поскольку дерево максимально симметрично то его высота — log(N)+1
Хорошая новость – нам никто не запрещает прикрепить к вершине еще какие-то полезные данные и тогда выборка произвольных данных по ID будет занимать log(N) времени
Плохая новость – одинаковые ID как следует из определения в нем существовать не могут. Придется делать финт ушами, один способ сделать вместо каждой вершины список вершин с одинаковым ID, другой – изменить алгоритм балансировки.
Bitcoin. Как это работает
10 min
 О Bitcoin я узнал относительно недавно, но он меня сразу подкупил своей идеей p2p. Чем глубже я зарывался в их Wiki, тем больше проникался этой идеей. Ее реализация красива и элегантна с технической точки зрения.
О Bitcoin я узнал относительно недавно, но он меня сразу подкупил своей идеей p2p. Чем глубже я зарывался в их Wiki, тем больше проникался этой идеей. Ее реализация красива и элегантна с технической точки зрения.Поиск хабра по Bitcoin выдает два топика. Но это скорее новости. По комментариям заметно, что у многих людей, особенно не знакомых с Bitcoin напрямую, возникает много вопросов насчет принципов его работы. Также много догадок, зачастую неверных. Чтобы как-то прояснить ситуацию, было решено написать эту статью.
B-tree
6 min
Введение
Деревья представляют собой структуры данных, в которых реализованы операции над динамическими множествами. Из таких операций хотелось бы выделить — поиск элемента, поиск минимального (максимального) элемента, вставка, удаление, переход к родителю, переход к ребенку. Таким образом, дерево может использоваться и как обыкновенный словарь, и как очередь с приоритетами.
Основные операции в деревьях выполняются за время пропорциональное его высоте. Сбалансированные деревья минимизируют свою высоту (к примеру, высота бинарного сбалансированного дерева с n узлами равна log n). Большинство знакомо с такими сбалансированными деревьями, как «красно-черное дерево», «AVL-дерево», «Декартово дерево», поэтому не будем углубляться.
В чем же проблема этих стандартных деревьев поиска? Рассмотрим огромную базу данных, представленную в виде одного из упомянутых деревьев. Очевидно, что мы не можем хранить всё это дерево в оперативной памяти => в ней храним лишь часть информации, остальное же хранится на стороннем носителе (допустим, на жестком диске, скорость доступа к которому гораздо медленнее). Такие деревья как красно-черное или Декартово будут требовать от нас log n обращений к стороннему носителю. При больших n это очень много. Как раз эту проблему и призваны решить B-деревья!
B-деревья также представляют собой сбалансированные деревья, поэтому время выполнения стандартных операций в них пропорционально высоте. Но, в отличие от остальных деревьев, они созданы специально для эффективной работы с дисковой памятью (в предыдущем примере – сторонним носителем), а точнее — они минимизируют обращения типа ввода-вывода.
Дерево Фенвика
3 min
Здравствуй, Хабрахабр. Сейчас я хочу рассказать о такой структуре данных как дерево Фенвика. Впервые описанной Питером Фенвиком в 1994 году. Данная структура похожа на дерево отрезков, но проще в реализации.
Дерево Фенвика — это структура данных, дерево на массиве, которая обладает следующими свойствами:
• позволяет вычислять значение некоторой обратимой операции F на любом отрезке [L; R] за логарифмическое время;
• позволяет изменять значение любого элемента за O(log N);
• требует памяти O(N);
Что это?
Дерево Фенвика — это структура данных, дерево на массиве, которая обладает следующими свойствами:
• позволяет вычислять значение некоторой обратимой операции F на любом отрезке [L; R] за логарифмическое время;
• позволяет изменять значение любого элемента за O(log N);
• требует памяти O(N);
Структуры данных: двоичная куча (binary heap)
4 min
Двоичная куча (binary heap) – просто реализуемая структура данных, позволяющая быстро (за логарифмическое время) добавлять элементы и извлекать элемент с максимальным приоритетом (например, максимальный по значению).
Для дальнейшего чтения необходимо иметь представление о деревьях, а также желательно знать об оценке сложности алгоритмов. Алгоритмы в этой статье будут сопровождаться кодом на C#.
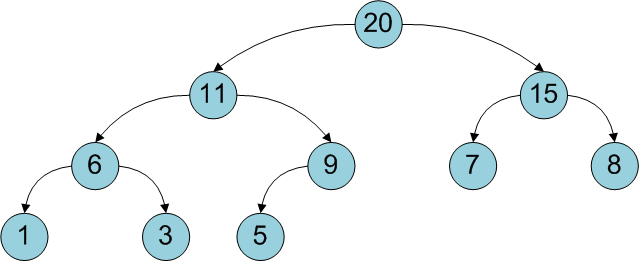
Двоичная куча представляет собой полное бинарное дерево, для которого выполняется основное свойство кучи: приоритет каждой вершины больше приоритетов её потомков. В простейшем случае приоритет каждой вершины можно считать равным её значению. В таком случае структура называется max-heap, поскольку корень поддерева является максимумом из значений элементов поддерева. В этой статье для простоты используется именно такое представление. Напомню также, что дерево называется полным бинарным, если у каждой вершины есть не более двух потомков, а заполнение уровней вершин идет сверху вниз (в пределах одного уровня – слева направо).
Для дальнейшего чтения необходимо иметь представление о деревьях, а также желательно знать об оценке сложности алгоритмов. Алгоритмы в этой статье будут сопровождаться кодом на C#.
Введение
Двоичная куча представляет собой полное бинарное дерево, для которого выполняется основное свойство кучи: приоритет каждой вершины больше приоритетов её потомков. В простейшем случае приоритет каждой вершины можно считать равным её значению. В таком случае структура называется max-heap, поскольку корень поддерева является максимумом из значений элементов поддерева. В этой статье для простоты используется именно такое представление. Напомню также, что дерево называется полным бинарным, если у каждой вершины есть не более двух потомков, а заполнение уровней вершин идет сверху вниз (в пределах одного уровня – слева направо).
Декартово дерево: Часть 3. Декартово дерево по неявному ключу
12 min
Оглавление (на данный момент)
Часть 1. Описание, операции, применения.
Часть 2. Ценная информация в дереве и множественные операции с ней.
Часть 3. Декартово дерево по неявному ключу.
To be continued...
Очень сильное колдунство
После всей кучи возможностей, которые нам предоставило декартово дерево в предыдущих двух частях, сегодня я совершу с ним нечто странное и кощунственное. Тем не менее, это действие позволит рассматривать дерево в совершенно новой ипостаси — как некий усовершенствованный и мощный массив с дополнительными фичами. Я покажу, как с ним работать, покажу, что все операции с данными из второй части сохраняются и для модифицированного дерева, а потом приведу несколько новых и полезных.
Вспомним-ка еще раз структуру дерамиды. В ней есть ключ x, по которому дерамида есть дерево поиска, случайный ключ y, по которому дерамида есть куча, а также, возможно, какая-то пользовательская информация с (cost). Давайте совершим невозможное и рассмотрим дерамиду… без ключей x. То есть у нас будет дерево, в котором ключа x нет вообще, а ключи y — случайные. Соответственно, зачем оно нужно — вообще непонятно :)
На самом деле расценивать такую структуру стоит как декартово дерево, в котором ключи x все так же где-то имеются, но нам их не сообщили. Однако клянутся, что для них, как полагается, выполняется условие двоичного дерева поиска. Тогда можно представить, что эти неизвестные иксы суть числа от 0 до
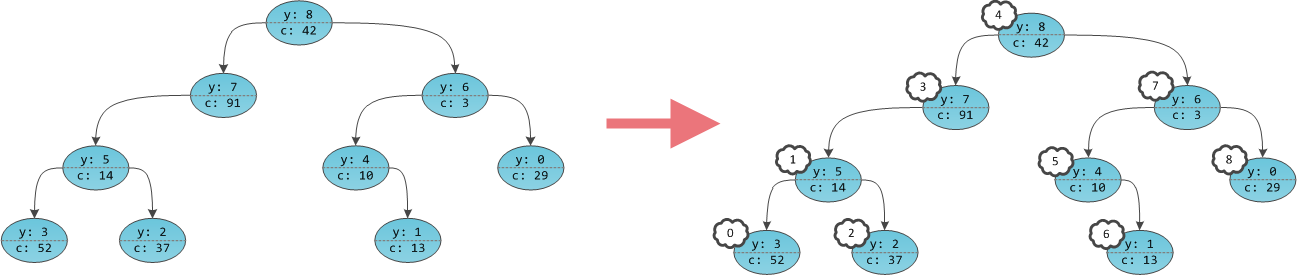
Получается, что в дереве будто бы не ключи в вершинах проставлены, а сами вершины пронумерованы. Причем пронумерованы в уже знакомом с прошлой части порядке in-order обхода. Дерево с четко пронумерованными вершинами можно рассматривать как массив, в котором индекс — это тот самый неявный ключ, а содержимое — пользовательская информация
c. Игреки нужны только для балансировки, это внутренние детали структуры данных, ненужные пользователю. Иксов на самом деле нет в принципе, их хранить не нужно.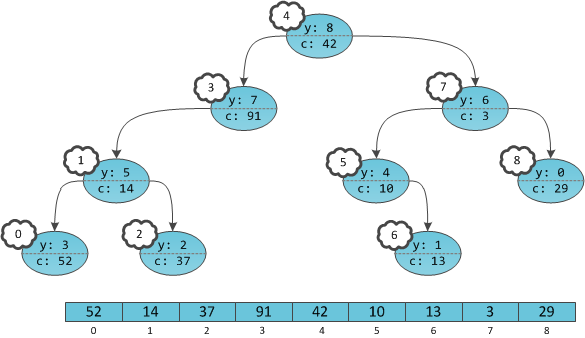
В отличие от прошлой части, этот массив не приобретает автоматически никаких свойств, вроде отсортированности. Ведь на информацию-то у нас нет никаких структурных ограничений, и она может храниться в вершинах как попало.
Декартово дерево: Часть 2. Ценная информация в дереве и множественные операции с ней
14 min
Оглавление (на данный момент)
Часть 1. Описание, операции, применения.
Часть 2. Ценная информация в дереве и множественные операции с ней.
Часть 3. Декартово дерево по неявному ключу.
To be continued...
Тема сегодняшней лекции
В прошлый раз мы с вами познакомились — скажем прямо, очень обширно познакомились — с понятием декартового дерева и основным его функционалом. Только до сих мы с вами использовали его одним-единственным образом: как «квази-сбалансированное» дерево поиска. То есть пускай нам дан массив ключей, добавим к ним случайно сгенерированные приоритеты, и получим дерево, в котором каждый ключ можно искать, добавлять и удалять за логарифмическое время и минимум усилий. Звучит неплохо, но мало.
К счастью (или к сожалению?), реальная жизнь такими пустяковыми задачами не ограничивается. О чем сегодня и пойдет речь. Первый вопрос на повестке дня — это так называемая K-я порядковая статистика, или индекс в дереве, которая плавно подведет нас к хранению пользовательской информации в вершинах, и наконец — к бесчисленному множеству манипуляций, которые с этой информацией может потребоваться выполнять. Поехали.
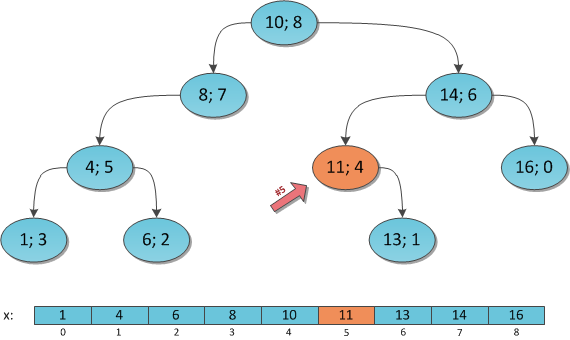
Ищем индекс
В математике, K-я порядковая статистика — это случайная величина, которая соответствует K-му по величине элементу случайной выборки из вероятностного пространства. Слишком умно. Вернемся к дереву: в каждый момент времени у нас есть декартово дерево, которое с момента его начального построения могло уже значительно измениться. От нас требуется очень быстро находить в этом дереве K-й по порядку возрастания ключ — фактически, если представить наше дерево как постоянно поддерживающийся отсортированным массив, то это просто доступ к элементу под индексом K. На первый взгляд не очень понятно, как это организовать: ключей-то у нас в дереве N, и раскиданы они по структуре как попало.
Декартово дерево: Часть 1. Описание, операции, применения
15 min
Оглавление (на данный момент)
Часть 1. Описание, операции, применения.
Часть 2. Ценная информация в дереве и множественные операции с ней.
Часть 3. Декартово дерево по неявному ключу.
To be continued...
Декартово дерево (cartesian tree, treap) — красивая и легко реализующаяся структура данных, которая с минимальными усилиями позволит вам производить многие скоростные операции над массивами ваших данных. Что характерно, на Хабрахабре единственное его упоминание я нашел в обзорном посте многоуважаемого winger, но тогда продолжение тому циклу так и не последовало. Обидно, кстати.
Я постараюсь покрыть все, что мне известно по теме — несмотря на то, что известно мне сравнительно не так уж много, материала вполне хватит поста на два, а то и на три. Все алгоритмы иллюстрируются исходниками на C# (а так как я любитель функционального программирования, то где-нибудь в послесловии речь зайдет и о F# — но это читать не обязательно :). Итак, приступим.
Введение
В качестве введения рекомендую прочесть пост про двоичные деревья поиска того же winger, поскольку без понимания того, что такое дерево, дерево поиска, а так же без знания оценок сложности алгоритма многое из материала данной статьи останется для вас китайской грамотой. Обидно, правда?
Следующий пункт нашей обязательной программы — куча (heap). Думаю, также многим известная структура данных, однако краткий обзор я все же приведу.
Представьте себе двоичное дерево с какими-то данными (ключами) в вершинах. И для каждой вершины мы в обязательном порядке требуем следующее: ее ключ строго больше, чем ключи ее непосредственных сыновей. Вот небольшой пример корректной кучи:
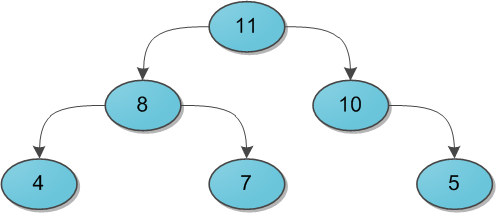
На заметку сразу скажу, что совершенно не обязательно думать про кучу исключительно как структуру, у которой родитель больше, чем его потомки. Никто не запрещает взять противоположный вариант и считать, что родитель меньше потомков — главное, выберите что-то одно для всего дерева. Для нужд этой статьи гораздо удобнее будет использовать вариант со знаком «больше».
Сейчас за кадром остается вопрос, каким образом в кучу можно добавлять и удалять из нее элементы. Во-первых, эти алгоритмы требуют отдельного места на осмотр, а во-вторых, нам они все равно не понадобятся.
Структуры данных: бинарные деревья. Часть 2: обзор сбалансированных деревьев
6 min
Первая статья цикла
Во второй статье я приведу обзор характеристик различных сбалансированных деревьев. Под характеристикой я подразумеваю основной принцип работы (без описания реализации операций), скорость работы и дополнительный расход памяти по сравнению с несбаланчированным деревом, различные интересные факты, а так же ссылки на дополнительные материалы.
Интро
Во второй статье я приведу обзор характеристик различных сбалансированных деревьев. Под характеристикой я подразумеваю основной принцип работы (без описания реализации операций), скорость работы и дополнительный расход памяти по сравнению с несбаланчированным деревом, различные интересные факты, а так же ссылки на дополнительные материалы.
Структуры данных: бинарные деревья. Часть 1
6 min
Интро
Этой статьей я начинаю цикл статей об известных и не очень структурах данных а так же их применении на практике.
В своих статьях я буду приводить примеры кода сразу на двух языках: на Java и на Haskell. Благодаря этому можно будет сравнить императивный и функциональный стили программирования и увидить плюсы и минусы того и другого.
Начать я решил с бинарных деревьев поиска, так как это достаточно базовая, но в то же время интересная штука, у которой к тому же существует большое количество модификаций и вариаций, а так же применений на практике.
Структуры данных в memcached/MemcacheDB. Часть 2
9 min
Продолжение статьи про структуры данных в memcached. В этой завершающей части мы рассмотрим еще три структуры данных: лог событий, массив и таблицу.
Структуры данных в memcached/MemcacheDB. Часть 1
8 min
Достаточно часто нам приходится хранить данные в memcached или MemcacheDB. Это могут быть относительно простые данные, например, закэшированные выборки из базы данных, а иногда необходимо хранить и обрабатывать более сложные структуры данных, которые обновляются одновременно из нескольких процессов, обеспечивать быстрое чтение данных и т.п. Реализация таких структур данных уже не укладывается в комбинацию команд memcached
Memcached и MemcacheDB в данной статье рассматриваются вместе, потому что имеют общий интерфейс доступа и логика работы большей части структур данных будет одинаковой, далее будем называть их просто «memcached». Зачем нам нужно хранить структуры данных в memcached? Чаще всего для распределенного доступа к данным из разных процессов, с разных серверов и т.п. А иногда для решения задачи хранения данных достаточно интерфейса, предоставляемого MemcacheDB, и необходимость в использовании СУБД отпадает.
Иногда проект разрабатывается изначально для нераспределенного случая (работа в рамках одного сервера), однако предполагая будущую необходимость масштабирования, лучше использовать сразу такие алгоритмы и структуры данных, которые могут обеспечить легкое масштабирование. Например, даже если данные будут храниться просто в памяти процесса, но интерфейс к доступа к ним повторяет семантику memcached, то при переходе к распределенной и масштабируемой архитектуре достаточно будет заменить обращения к внутреннему хранилищу на обращения к серверу (или кластеру серверов) memcached.
get/set. В данной статье будут описаны способы хранения некоторых структур данных в memcached с примерами кода и описанием основных идей.Memcached и MemcacheDB в данной статье рассматриваются вместе, потому что имеют общий интерфейс доступа и логика работы большей части структур данных будет одинаковой, далее будем называть их просто «memcached». Зачем нам нужно хранить структуры данных в memcached? Чаще всего для распределенного доступа к данным из разных процессов, с разных серверов и т.п. А иногда для решения задачи хранения данных достаточно интерфейса, предоставляемого MemcacheDB, и необходимость в использовании СУБД отпадает.
Иногда проект разрабатывается изначально для нераспределенного случая (работа в рамках одного сервера), однако предполагая будущую необходимость масштабирования, лучше использовать сразу такие алгоритмы и структуры данных, которые могут обеспечить легкое масштабирование. Например, даже если данные будут храниться просто в памяти процесса, но интерфейс к доступа к ним повторяет семантику memcached, то при переходе к распределенной и масштабируемой архитектуре достаточно будет заменить обращения к внутреннему хранилищу на обращения к серверу (или кластеру серверов) memcached.