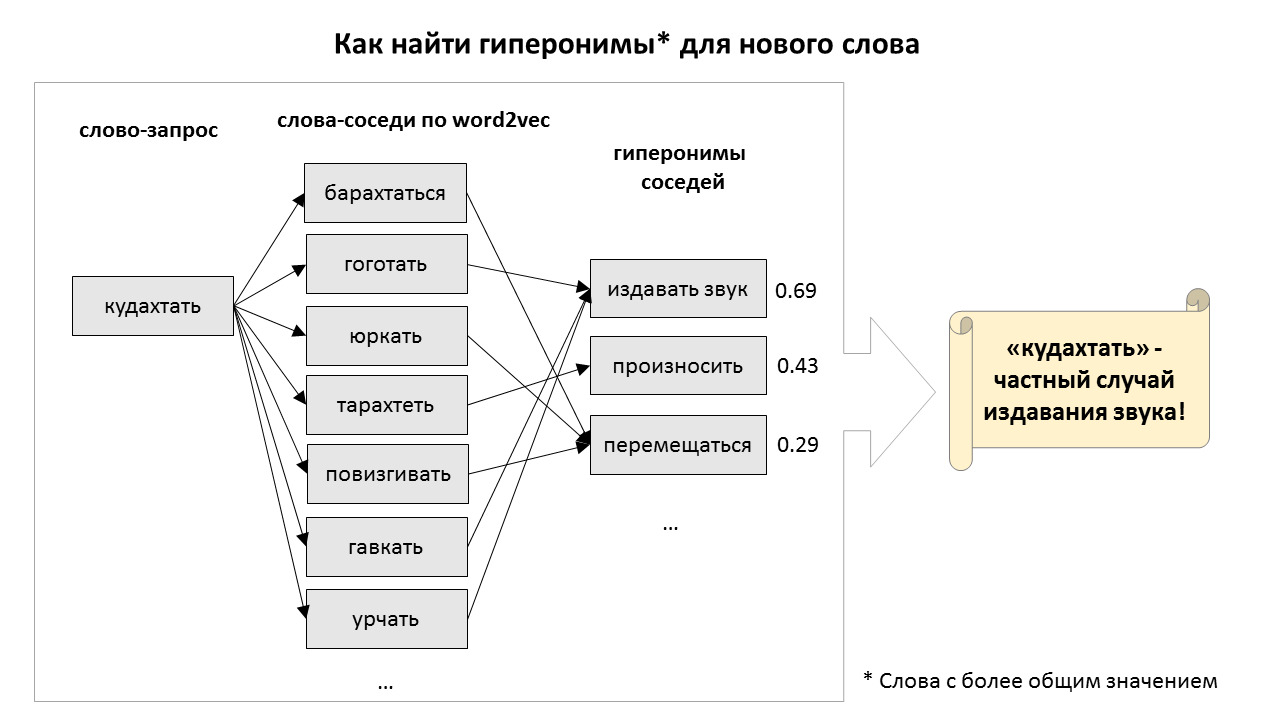
Как может машина понимать смысл слов и понятий, и вообще, что значит — понимать? Понимаете ли вы, например, что такое спаржа? Если вы скажете мне, что спаржа — это (1) травянистое растение, (2) съедобный овощ, и (3) сельскохозяйственная культура, то, наверное, я останусь убеждён, что вы действительно знакомы со спаржей. Лингвисты называют такие более общие понятия гиперонимами, и они довольно полезны для ИИ. Например, зная, что я не люблю овощи, робот-официант не стал бы предлагать мне блюда из спаржи. Но чтобы использовать подобные знания, надо сначала откуда-то их добыть.
В этом году компьютерные лингвисты организовали соревнование по поиску гиперонимов для новых слов. Я тоже попробовал в нём поучаствовать. Нормально получилось собрать только довольно примитивный алгоритм, основанный на поиске ближайших соседей по эмбеддингам из word2vec. Однако этот простой алгоритм каким-то образом оказался наилучшим решением для поиска гиперонимов для глаголов. Послушать про него можно в записи моего выступления, а если вы предпочитаете читать, то добро пожаловать под кат.