Дано: собственные и аутсорс-проекты, некоторые участники работают удаленно.
Требуется: необходимо быстро назначать задачи исполнителям, планировать спринты, трекать выполнение и статусы, визуализировать процессы и делиться результатами с заказчиками.
Выбирая для себя сервисы, с помощью которых мы могли бы работать над проектами в несколько раз эффективнее, у нас сложился целый список различных сервисов таск- и тайм-менеджмента, для управления и планирования проектов, командной работы, построения онлайн диаграмм и т.д.
Изначально сервисов было более 100, но постепенно список сокращался, и мы остановили наш выбор на трех, удовлетворяющих вместе наши нужды лучше всего: Jira, Slack и GanttPro. Но, если вдруг эти сервисы не помогут вам в планировании задач и работы с командой, делюсь с вами полным списком:

Требуется: необходимо быстро назначать задачи исполнителям, планировать спринты, трекать выполнение и статусы, визуализировать процессы и делиться результатами с заказчиками.
Выбирая для себя сервисы, с помощью которых мы могли бы работать над проектами в несколько раз эффективнее, у нас сложился целый список различных сервисов таск- и тайм-менеджмента, для управления и планирования проектов, командной работы, построения онлайн диаграмм и т.д.
Изначально сервисов было более 100, но постепенно список сокращался, и мы остановили наш выбор на трех, удовлетворяющих вместе наши нужды лучше всего: Jira, Slack и GanttPro. Но, если вдруг эти сервисы не помогут вам в планировании задач и работы с командой, делюсь с вами полным списком:
Процесс поиска очень часто усложняется тем, что все сервисы, как один, пишут «Лучший сервис, помогающий превратить ваши идеи в реальность и реализовать ваши проекты. Сегодня.». Так, а что вы делаете-то? Поэтому в этом списке без лишних эпитетов, только что какой сервис умеет. :)



 Поиск по Хабру не нашел подробных статей по системе Alfresco. В данной статье попробую убить сразу двух зайцев: рассказать что представляет из себя система Alfresco и как мы используем ее в нашей работе.
Поиск по Хабру не нашел подробных статей по системе Alfresco. В данной статье попробую убить сразу двух зайцев: рассказать что представляет из себя система Alfresco и как мы используем ее в нашей работе.


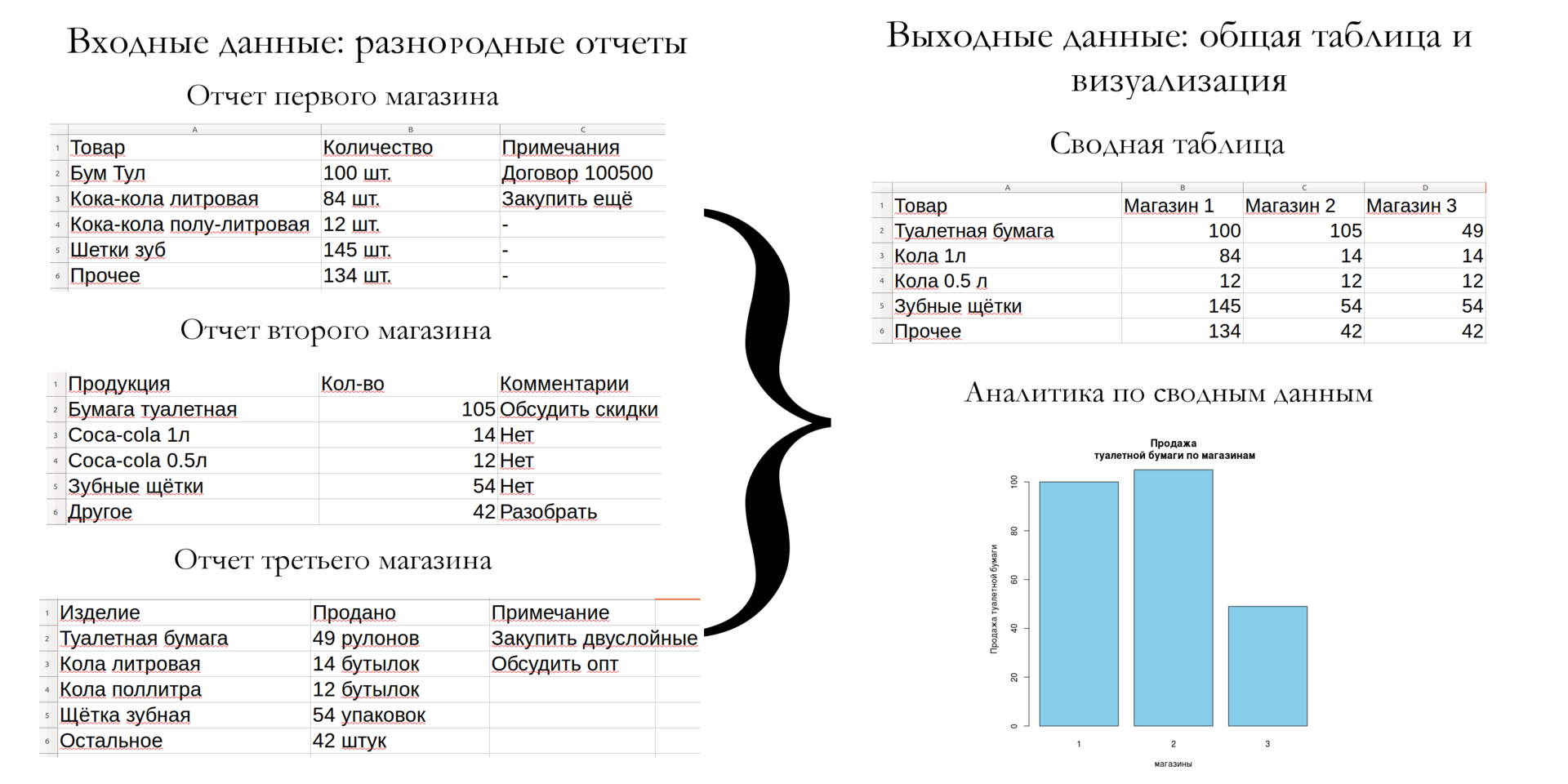
 Реляционные базы данных (РБД) используются повсюду. Они бывают самых разных видов, от маленьких и полезных SQLite до мощных Teradata. Но в то же время существует очень немного статей, объясняющих принцип действия и устройство реляционных баз данных. Да и те, что есть — довольно поверхностные, без особых подробностей. Зато по более «модным» направлениям (большие данные, NoSQL или JS) написано гораздо больше статей, причём куда более глубоких. Вероятно, такая ситуация сложилась из-за того, что реляционные БД — вещь «старая» и слишком скучная, чтобы разбирать её вне университетских программ, исследовательских работ и книг.
Реляционные базы данных (РБД) используются повсюду. Они бывают самых разных видов, от маленьких и полезных SQLite до мощных Teradata. Но в то же время существует очень немного статей, объясняющих принцип действия и устройство реляционных баз данных. Да и те, что есть — довольно поверхностные, без особых подробностей. Зато по более «модным» направлениям (большие данные, NoSQL или JS) написано гораздо больше статей, причём куда более глубоких. Вероятно, такая ситуация сложилась из-за того, что реляционные БД — вещь «старая» и слишком скучная, чтобы разбирать её вне университетских программ, исследовательских работ и книг.