
Анализ тональности — это метод обработки естественного языка (NLP), используемый для определения того, являются ли данные(текст) положительными, отрицательными или нейтральными.
Анализ тональности имеет фундаментальное значение, поскольку помогает понять эмоциональные оттенки языка. Это, в свою очередь, помогает автоматически сортировать мнения, стоящие за отзывами, обсуждениями в социальных сетях, комментариями и т. д.
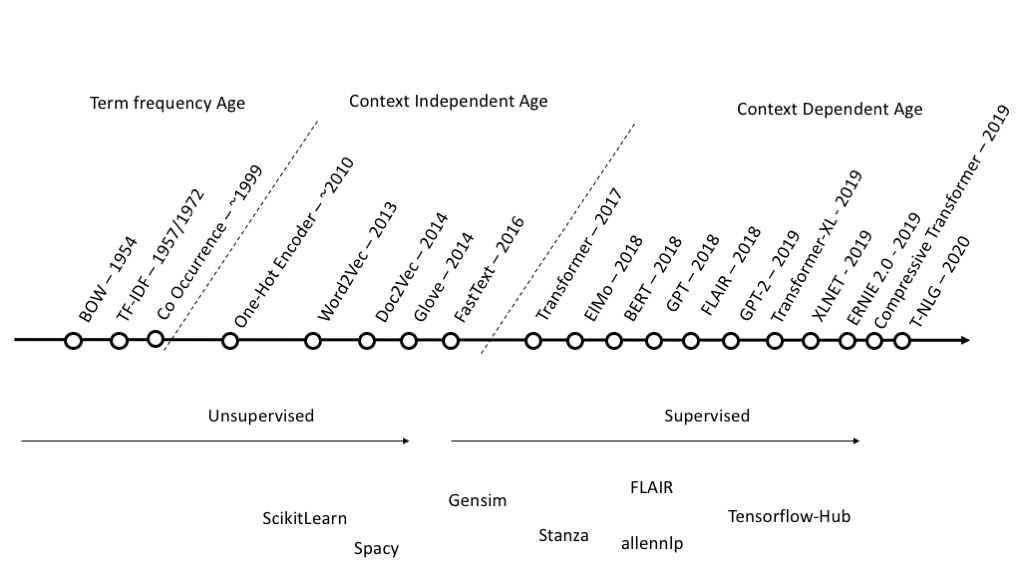
Хотя сентиментальный анализ стал чрезвычайно популярным в последнее время, работы над ним продолжаются с начала 2000-х годов. Традиционные методы машинного обучения, такие как наивный байесовский метод, логистическая регрессия и машины опорных векторов (SVM), широко используются для больших объемов, поскольку они хорошо масштабируются. На практике доказано, что методы глубокого обучения (DL) обеспечивают лучшую точность для различных задач NLP, включая анализ тональности; однако они, как правило, медленнее и дороже в обучении и использовании.














