И что же?

Machine Learning / Data Science

Обратил внимание на статью от модератора Хабра @Exosphere. Цитата:
Пользователя может слить компания … , пользователя могут слить участники каких-то таинственных масонских кружков хабрачатов, пользователя могут слить группы авторов, конкурента может слить конкурент. Могу сказать совершенно точно: ещё ни один такой «слив» не прошёл мимо нас. У нас есть отработанная схема быстрого определения таких нарушителей — все они банятся и/или лишаются кармы, и их жизнь на Хабре начинается с чистого листа. Причём совершенно неважно, идёт речь о частном или корпоративном аккаунте — перед правилами Хабра все равны.
Правда ли все равны, или кто-то является "более равным"?

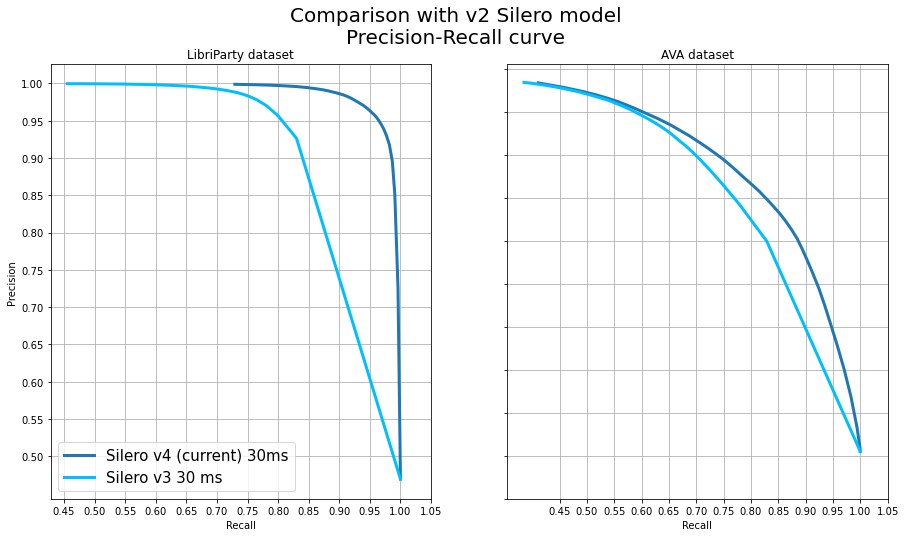
Вчера OpenAI выпустили Whisper. По сути они просто опубликовали веса набора больших (и не очень) рекуррентных трансформеров для распознавания речи и статью (и самое главное, в статье ни слова про compute и ресурсы). И естественно уже вчера и сегодня утром мне в личку начали сыпаться сообщения, мол всё, распознавание речи решено, все идеально классно и быстро работает, расходимся.
Постараемся разобраться под катом. Короткий ответ, если вам лень читать - для языков, кроме английского, скорее всего это далеко от правды (проверил я на русском). На английском наверное стоит сделать отдельный и чуть более подробный разбор, если эта статья наберет хотя бы 50 плюсов.
Пользователи жаловались, что демку наших моделей синтеза тяжело запускать в колабе. Поэтому мы сделали бесплатного телеграм-бота, который основан на наших последних моделях синтеза речи.
С ботом можно общаться только напрямую. Бот содержит весь основной функционал последних моделей (работает мгновенно, имеет максимально высокое качество, есть автоматическая простановка ударений и буквы ё). Более подробно об ограничениях и особенностях работы можно узнать в методах /help и /faq.
Также в ближайшем будущем мы раскатим небольшое "полу-праздничное" обновление, которое как нам кажется порадует многих пользователей.

In this article, we shall provide some background on how multilingual multi-speaker models work and test an Indic TTS model that supports 9 languages and 17 speakers (Hindi, Malayalam, Manipuri, Bengali, Rajasthani, Tamil, Telugu, Gujarati, Kannada).
It seems a bit counter-intuitive at first that one model can support so many languages and speakers provided that each Indic language has its own alphabet, but we shall see how it was implemented.
Also, we shall list the specs of these models like supported sampling rates and try something cool – making speakers of different Indic languages speak Hindi. Please, if you are a native speaker of any of these languages, share your opinion on how these voices sound, both in their respective language and in Hindi.

Под одной из наших недавних статей на Хабре я упомянул исследование, подробно рассматривающее вопрос "обмана" коммерческих систем биометрической идентификации с помощью открытых инструментов по клонированию голоса. Завязалась дискуссия на тему "стоит ли бояться, что ваш голос украдут".
Естественно, исследование четкого однозначного ответа не дает, но скорее говорит, что на пути злоумышленников в первую очередь встает несовершенство систем клонирования голоса, количество и качество записей полученных мошенниками, акценты и прочие несовершенства мира. Проценты "обмана" при наличии ряда таких затруднений там не впечатляющие.
Так уж получилось, что один из наших заказчиков, заказывал у нас голос для синтеза … как раз с целью сделать пен-тест коммерческой системы биометрической идентификации. Не могу назвать (и даже не знаю) вендора этой системы, но заказчик это довольно крупная и известная фирма (они попросили не упоминать какие-либо названия).
Короткий ответ на вопрос из заголовка - да, причем весьма успешно. Длинный ответ - скорее всего вам этого бояться не следует. Постараюсь объяснить почему. Поехали.

Буду краток. На днях Телеграм выкатил премиум-подписку и Дуров высказался за все хорошее, мол цитата: "This will herald a new, user-centric era in the history of social media services".
Сейчас я случайно натолкнулся на пункт 7.4 Terms of Service Телеграма, согласно которому ваши голосовые сообщения отправляются в "Google LLC, subsidiary of Alphabet Inc.".
Личную оценку этому давать я не буду, но постараюсь собрать какие-то интересные факты на эту тему, которые проскакивали в публичном поле. Было бы интересно послушать какие-то инсайды в комментариях.

В нашей прошлой статье мы ускорили наши модели в 10 раз, добавили новые высококачественные голоса и управление с помощью SSML, возможность генерировать аудио с разной частотой дискретизации и много других фишек.
В этот раз мы добавили:
eugeny);ё со словарем в 4 миллиона слов и точностью 100% (но естественно с рядом оговорок);Пока улучшение интерфейсов мы отложили на некоторое время. Ускорить модели еще в 3+ раза мы тоже смогли, но пока с потерей качества, что не позволило нам обновить их прямо в этом релизе.
Попробовать модель как обычно можно в нашем репозитории и в колабе.

Недавно натолкнулся на статью в корпоративном блоге Home Credit Bank на Хабре.
Там есть ссылка на нашу статью на Хабре, статья в свою очередь ведет на наш проект, который опубликован под лицензией GNU Affero General Public License v3.0:
Вероятно вы уже поняли, куда это все идет. Данная лицензия подразумевает публикацию кода проекта, который использует наши модели. Но банк естественно этого делать не будет, потому что это банк. А значит лицензия де факто означает некоммерческое использование.
Но Home Credit Bank естественно не обращался к нам за коммерческой версией или лицензией для данной модели.

In our last article we made a bunch of promises about our speech synthesis.
After a lot of hard work we finally have delivered upon these promises:
This is a truly break-through achievement for us and we are not planning to stop anytime soon. We will be adding as many languages as possible shortly (the CIS languages, English, European languages, Hindic languages). Also we are still planning to make our models additional 2-5x faster.
We are also planning to add phonemes and a new model for stress, as well as to reduce the minimum amount of audio required to train a high-quality voice to 5 — 15 minutes.

В нашей прошлой статье про синтез речи мы дали много обещаний: убрать детские болячки, радикально ускорить синтез еще в 10 раз, добавить новые "фишечки", радикально улучшить качество.
Сейчас, вложив огромное количество работы, мы наконец готовы поделиться с сообществом своими успехами:
Это по-настоящему уникальное и прорывное достижение и мы не собираемся останавливаться. В ближайшее время мы добавим большое количество моделей на разных языках и напишем целый ряд публикаций на эту и смежные темы, а также продолжим делать наши модели лучше (например, еще в 2-5 раз быстрее).
Попробовать модель как обычно можно в нашем репозитории и в колабе.

Статья не про майнинг и не для майнеров.
Недавно на Хабре была статья про сравнение карточек для вычислений. На мой взгляд статья получилась очень даже неплохой, но в ней никак не отразили позиции RTX 3090 Turbo и как-то подозрительно мало времени уделили А10.
На мой взгляд среди карточек с "большим" объемом памяти (более 12 гигабайт) по рекомендованной рыночной цене (РРК) 3090 является лидером хит-парада, а по рыночной цене — скорее уже А10. Детальный разбор почему и как я подходил к выбору карточек и тестированию — прошу под кат.
Также так случилось, что у меня под рукой оказалось большое количество рейзеров разной степени говённости. И сначала я замахивался, чтобы поставить некую точку в вечных дебатах про райзеры (а мнения разнятся от такого до банального "не работает" или "для DL нельзя использовать"), но в итоге все получилось чуть более сумбурно. Но я постарался подойти к тестированию райзеров тоже структурированно и аналитически.
И последнее — в прошлой статье я сокрушался, что мол нет на рынке большого выбора однослотовых решений по вменяемой цене. Теперь на выбор решений много, но с доступностью и ценами ситуация лучше не стала (есть как минимум 2 поколения карточек Quadro и Tesla A10, но геймерских нет, насколько я знаю).

В 16 лет я увидел панорамный снимок на фото выше и, уже успев натерпеться стоматологии и врачей, я загрустил. Я спросил врача в Красноярске, который анализировал снимок, мол что же делать с лишними зубами (а тогда они еще не особо мешали и только слегка прощупывались)? Я получил довольно точный ответ в духе - нужно надрезать десну, отворачивать ее, сверлить кость и удалять зубы. Это меня впечатлило настолько, что я отложил решение этого вопроса аж до 29 лет. Да и не до этого как-то было.
В 29 лет у меня встал ребром другой вопрос. Я сломал зуб, у меня испортились зубы мудрости (2 из 4) и стало понятно, что этот вопрос комплексный и системный. Откладывать нельзя и половинчатые решения неприемлемы. Зубы мудрости удаляются парами. Испортились зубы с 2 сторон. Да и сверхкомплектные зубы стали немного беспокоить, а один из них аж показался и пошел вверх. А для комплексного решения вопроса … нужно удалить сразу 7 зубов: 4 зуба мудрости, 2 ретинированных сверхкомплектных зуба и один сломанный зуб. Понятно, что надо было подойти к этому вопросу основательно.
Я успешно прошел через этот процесс. И признаться был удивлен и шокирован, в первую очередь тому, что это далеко не так страшно как я думал. И самые неприятные сюрпризы ждали меня не там, где я ожидал. В этой статьей я постараюсь рассказать вам про свой опыт. Статья будет полезна тем, кто находится в похожей жизненной ситуации: мешают зубы мудрости, сломался зуб, есть "лишние" зубы или все вместе. Я в аналогичной ситуации банально боялся. Бояться не надо, надо бороться со страхом информацией.

Пожалуйста, не спешите сразу закрывать или идти в комментарии. Выслушайте, буду краток. Нет, я не считаю, что Хабр движется в правильном направлении в целом. Но в современных реалиях я считаю, что по сравнению с прочими ресурсами с хоть какой-то похожей аудиторией Хабр не такой уж и токсичный. Грубо говоря — интернет "испортился", Хабр тоже, но в меньшей степени.
Недавно я попробовал примерить на себя роль автора контента сразу на нескольких площадках и естественно разложить их модели на составляющие и сравнить их с Хабром. За деталями прошу под кат.
Заранее прошу всех уважать друг друга в комментариях, тема дискуссионная.

Мы сделали бесплатного телеграм-бота, который переводит аудио в текст. В отличие от нашего бесплатного публичного решения для транскрибации длинных аудио, этот бот скорее настроен для удобства работы с короткими голосовыми сообщениями, заметками и аудио средней длины (несколько минут).
Боту можно послать аудио как напрямую, так и добавить в группу. В группе бот будет реагировать на все аудиофайлы (но сообщения об ошибках выводиться не будут). Более подробно об ограничениях и особенностях работы можно узнать в методах /help и /faq.
Основная UX фишка работы бота — проработанный и удобный формат чтения и навигации по распознанным сообщениям и заметкам (а не стена текста).

На Хабре часто висят в топе: политика и очередные запреты, трактор, ну и конечно сенсационные новости про "очередные достижения AI". Также журналисты маркетологи любят перепечатывать нормальные статьи наподобие этой но под максимально кричащими заголовками в духе "AI поработит мир, ваш голос уже украли".
Не секрет, что имея бюджет на вычисления в единицы или десятки миллионов долларов, напоказ достичь можно многого. Но реальность как правило оказывается более сложной и прозаической.
Вопреки этому тренду, в этой статье мы постараемся на пальцах и близко к народу:
И также мы конечно поделимся новостями нашего публичного синтеза речи.


Working with speech recognition models we often encounter misconceptions among potential customers and users (mostly related to the fact that people have a hard time distinguishing substance over form). People also tend to believe that punctuation marks and spaces are somehow obviously present in spoken speech, when in fact real spoken speech and written speech are entirely different beasts.
Of course you can just start each sentence with a capital letter and put a full stop at the end. But it is preferable to have some relatively simple and universal solution for "restoring" punctuation marks and capital letters in sentences that our speech recognition system generates. And it would be really nice if such a system worked with any texts in general.
For this reason, we would like to share a system that:
To reiterate — the purpose of such a system is only to improve the readability of the text. It does not add information to the text that did not originally exist.
При разработке систем распознавания речи мы сталкиваемся с заблуждениями среди потребителей и разработчиков, в первую очередь связанными с разделением формы и сути. Одним из таких заблуждений является то, что в устной речи якобы "можно услышать" грамматически верные знаки препинания и пробелы между словами, когда по факту реальная устная речь и грамотная письменная речь очень сильно отличаются (устная речь скорее похожа на "поток" слегка разделенный паузами и интонацией, поэтому люди так не любят монотонно бубнящих докладчиков).
Понятно, что можно просто начинать каждое высказывание с большой буквы и ставить точку в конце. Но хотелось бы иметь какое-то относительно простое и универсальное средство расстановки знаков препинания и заглавных букв в предложениях, которые генерирует наша система распознавания речи. Совсем хорошо бы было, если бы такая система в принципе работала с любыми текстами.
По этой причине мы бы хотели поделиться с сообществом системой, которая:
На всякий случай явно повторюсь — цель такой системы — лишь улучшать читабельность текста. Она не добавляет в текст информации, которой в нем изначально не было.
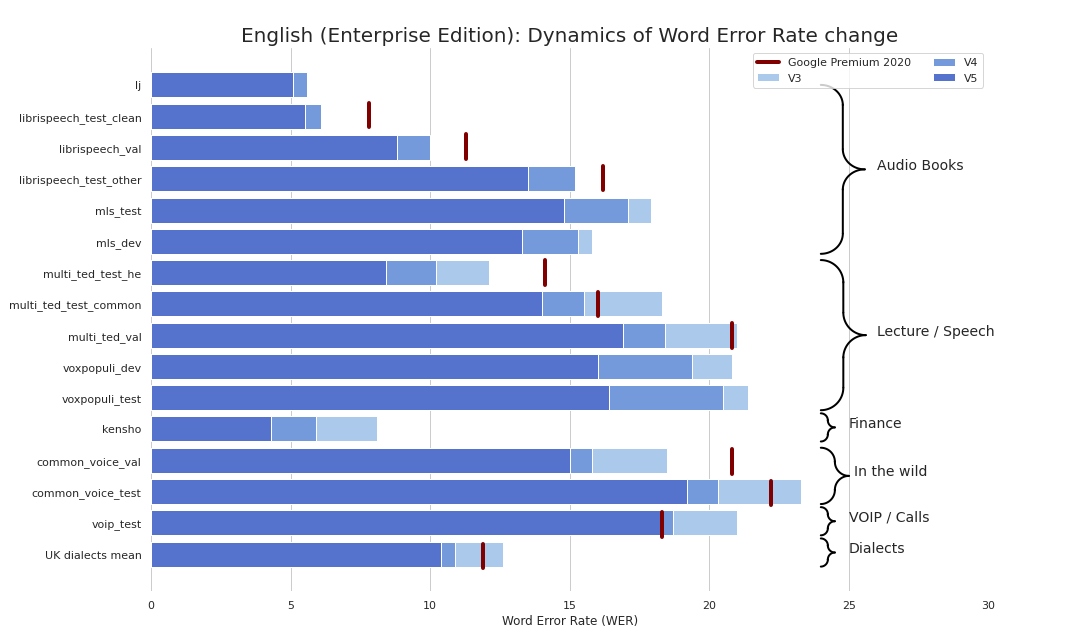
Мы опубликовали уже пятую версию наших моделей для распознавания английского языка и четвертую — для немецкого. На картинке выше — прогресс роста качества для английского языка.
В этот раз мы можем порадовать вас:
small и скоро ожидается xsmall) и их квантизованными версиями;
Сейчас в сфере ML постоянно слышно про невероятные "успехи" трансформеров в разных областях. Но появляется все больше статей о том, что многие из этих успехов мягко говоря надуманы (из недавнего помню статью про пре-тренировку больших CNN в компьютерном зрении, огромную MLP сетку, статью про деконструкцию достижений в сфере трансформеров).
Если очень коротко просуммировать эти статьи — примерно все более менее эффективные нерекуррентные архитектуры на схожих вычислительных бюджетах, сценариях и данных будут показывать примерно похожие результаты.
Тем не менее у self-attention модуля есть ряд плюсов: (i) относительная простота при правильной реализации (ii) простота квантизации (iii) относительная эффективность на коротких (до нескольких сотен элементов) последовательностях и (iv) относительная популярность (но большая часть имплементаций имеет код раздутый раз в 5).
Также есть определенный пласт статей про улучшение именно асимптотических свойств self-attention модуля (например Linformer и его аналоги). Но несмотря на это, если например открыть список пре-тренированных языковых моделей на основе self-attention модулей, то окажется, что "эффективных" моделей там буквально пара штук и они были сделаны довольно давно. Да и последовательности длиннее 500 символов нужны не очень часто (если вы не Google).
Попробуем ответить на вопрос — а как существенно снизить размер и ускорить self-attention модуль и при этом еще удовлетворить ряду production-ready требований: