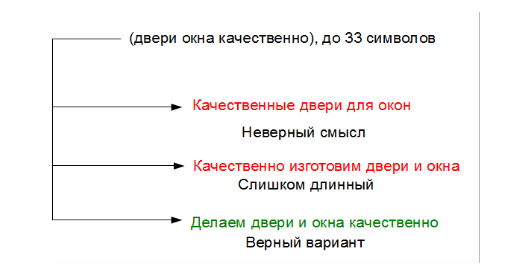
Преамбула
Здравствуйте. Я являюсь главным разработчиком крупнейшего в СНГ сервера Minecraft (не буду рекламировать, кому надо, те знают). Уже почти год мы пишем свою реализацию сервера, рассчитанную на больше чем 40 человек (мы хотим видеть цифру в 500 хотя бы). Пока всё было удачно, но последнее время система начала упираться в то, что из-за не самой удачной реализации сети (1 поток на ввод, 1 на вывод + 1 на обработку), при 300 игроках онлайн работает более 980 потоков (+ системные), что в сочетании с производительностью дефолтного io Явы даёт огромное падение производительности, и уже при 100 игроках сервер в основном занимается тем, что пишет/читает в/из сети.
Поэтому я решила переходить на NIO. В руки совершенно случайно попала библиотека
Netty, структура которой показалась просто идеально подходящей для того, чтобы встроить её в уже готовое работающее решение. К сожалению, мануалов по Netty мало не только на русском, но и на английском языках, поэтому приходилось много экспериментировать и лазить в код библиотеки, чтобы найти лучший способ.
Здесь я постараюсь расписать серверную часть работы с сетью через Netty, может быть это кому-то будет полезно.





 Самая простая сеть нашлась в статье "
Самая простая сеть нашлась в статье "