
Генетический советник для торговли опционами
11 min
При торговле опционами одна из главных задач состоит в определении справедливой цены опциона. На основании нее можно понять какие опционы недооценены рынком, а какие переоценены в данный момент. Исходя из этого и принимаются решения о покупке или продаже конкретного опциона. В данной статье рассматривается опыт создания советника в основе которого лежит Генетический Алгоритм (ГА), позволяющего как раз автоматизировать процесс выбора опционов для продажи и покупки соответственно Советник, в отличие от торговых роботов (или Механических Торговых Систем — МТС), не производит сделок, он лишь дает рекомендации трейдеру, который уже самостоятельно принимает решение совершать сделку или нет.
Для начала — пару слов о генетическом алгоритме:
Подробно описывать генетический алгоритм не имеет смысла, поскольку эта тема хорошо представлена и на данном ресурсе и вообще на просторах Интернета. Остановлюсь только на основных моментах, которые необходимы для понимания концепции генетического советника в целом.







 Посмотрим на то, как с ними работать в Python, какие возможные методы и модели можно использовать для прогнозирования; что такое двойное и тройное экспоненциальное взвешивание; что делать, если стационарность — это не про вас; как построить SARIMA и не умереть; и как прогнозировать xgboost-ом. И всё это будем применять к примеру из суровой реальности.
Посмотрим на то, как с ними работать в Python, какие возможные методы и модели можно использовать для прогнозирования; что такое двойное и тройное экспоненциальное взвешивание; что делать, если стационарность — это не про вас; как построить SARIMA и не умереть; и как прогнозировать xgboost-ом. И всё это будем применять к примеру из суровой реальности. 



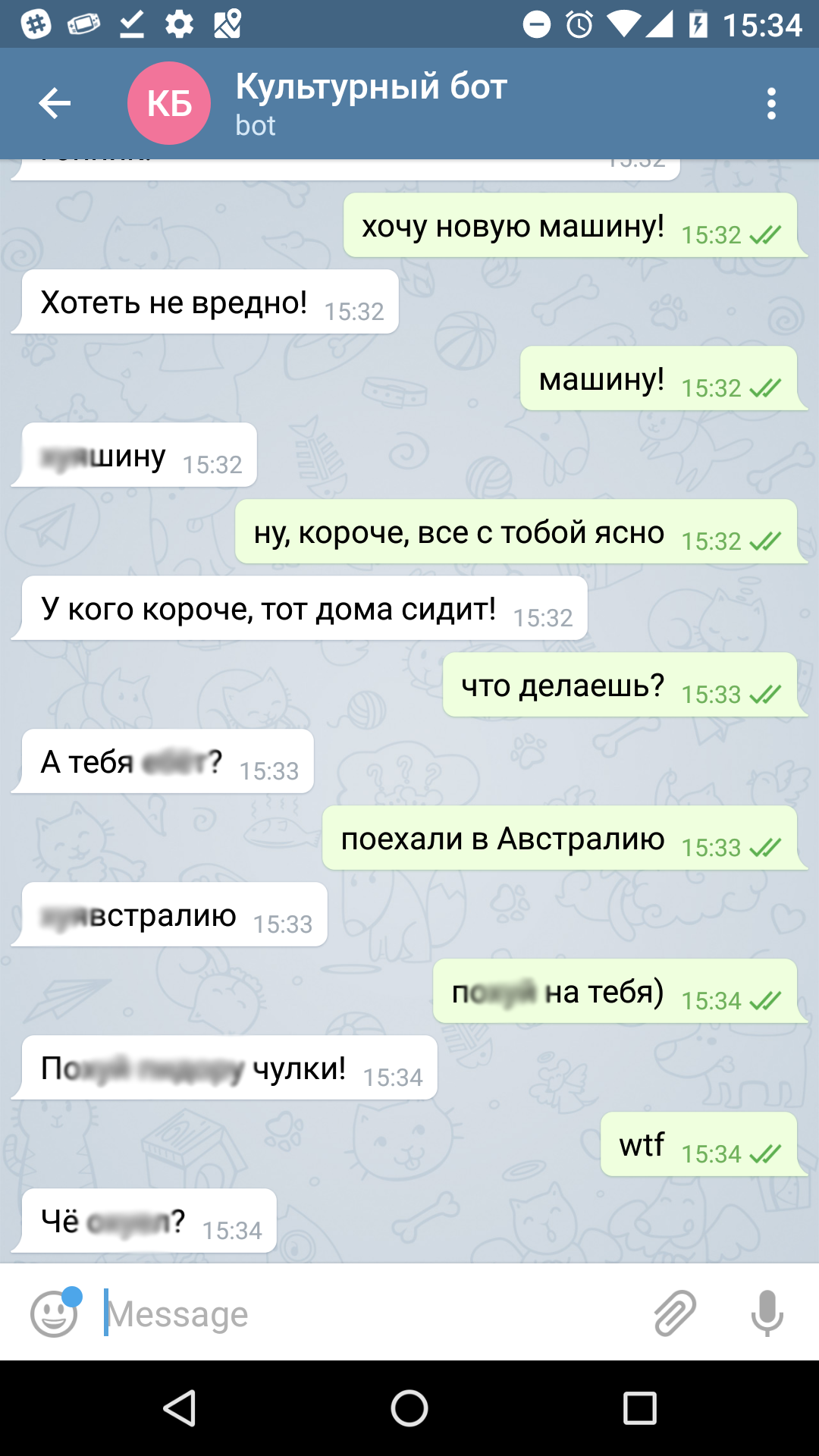 Недавно, в попытках разобраться с nlp, мне пришла идея написать простого telegram бота, который будет разговаривать, как дерзкий гопник. То есть:
Недавно, в попытках разобраться с nlp, мне пришла идея написать простого telegram бота, который будет разговаривать, как дерзкий гопник. То есть: