Меня зовут Пётр Ромов, я — data scientist в Yandex Data Factory. В этом посте я предложу сравнительно простой и надежный способ начать карьеру аналитика данных.
Многие из вас наверняка знают или хотя бы слышали про
Kaggle. Для тех, кто не слышал: Kaggle — это площадка, на которой компании проводят конкурсы по созданию прогнозирующих моделей. Её популярность столь велика, что часто под «кэглами» специалисты понимают сами конкурсы. Победитель каждого соревнования определяется автоматически — по метрике, которую назначил организатор. Среди прочих, Kaggle в разное время опробовали Facebook, Microsoft и нынешний
владелец площадки — Google. Яндекс тоже
несколько раз
отметился. Как правило, Kaggle-сообществу дают решать задачи, довольно близкие к реальным: это, с одной стороны, делает конкурс интересным, а с другой — продвигает компанию как работодателя с солидными задачами. Впрочем, если вам скажут, что компания-организатор конкурса задействовала в своём сервисе алгоритм одного из победителей, — не верьте. Обычно решения из топа слишком сложны и недостаточно производительны, а погони за тысячными долями значения метрики не настолько и нужны на практике. Поэтому организаторов больше интересуют подходы и идейная часть алгоритмов.

Kaggle — не единственная площадка с соревнованиями по анализу данных. Существуют и другие:
DrivenData,
DataScience.net,
CodaLab. Кроме того, конкурсы проводятся в рамках научных конференций, связанных с машинным обучением: SIGKDD, RecSys, CIKM.
Для успешного решения нужно, с одной стороны, изучить теорию, а с другой — начать практиковать использование различных подходов и моделей. Другими словами, участие в «кэглах» вполне способно сделать из вас аналитика данных. Вопрос — как научиться в них участвовать?

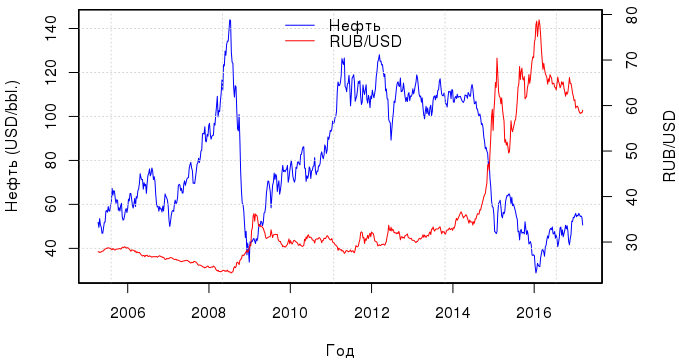



 Статистика приходит к нам на помощь при решении многих задач, например: когда нет возможности построить детерминированную модель, когда слишком много факторов или когда нам необходимо оценить правдоподобие построенной модели с учётом имеющихся данных. Отношение к статистике неоднозначное. Есть мнение, что существует три вида лжи: ложь, наглая ложь и статистика. С другой стороны, многие «пользователи» статистики слишком ей верят, не понимая до конца, как она работает: применяя, например, тест
Статистика приходит к нам на помощь при решении многих задач, например: когда нет возможности построить детерминированную модель, когда слишком много факторов или когда нам необходимо оценить правдоподобие построенной модели с учётом имеющихся данных. Отношение к статистике неоднозначное. Есть мнение, что существует три вида лжи: ложь, наглая ложь и статистика. С другой стороны, многие «пользователи» статистики слишком ей верят, не понимая до конца, как она работает: применяя, например, тест 




 Корректирующие (или помехоустойчивые) коды — это коды, которые могут обнаружить и, если повезёт, исправить ошибки, возникшие при передаче данных. Даже если вы ничего не слышали о них, то наверняка встречали аббревиатуру CRC в списке файлов в ZIP-архиве или даже надпись ECC на планке памяти. А кто-то, может быть, задумывался, как так получается, что если поцарапать DVD-диск, то данные всё равно считываются без ошибок. Конечно, если царапина не в сантиметр толщиной и не разрезала диск пополам.
Корректирующие (или помехоустойчивые) коды — это коды, которые могут обнаружить и, если повезёт, исправить ошибки, возникшие при передаче данных. Даже если вы ничего не слышали о них, то наверняка встречали аббревиатуру CRC в списке файлов в ZIP-архиве или даже надпись ECC на планке памяти. А кто-то, может быть, задумывался, как так получается, что если поцарапать DVD-диск, то данные всё равно считываются без ошибок. Конечно, если царапина не в сантиметр толщиной и не разрезала диск пополам. Здравствуй, Хабр! Цикл статей по инструментам для обучения нейронных сетей продолжается обзором популярного фреймворка Tensorflow.
Здравствуй, Хабр! Цикл статей по инструментам для обучения нейронных сетей продолжается обзором популярного фреймворка Tensorflow.