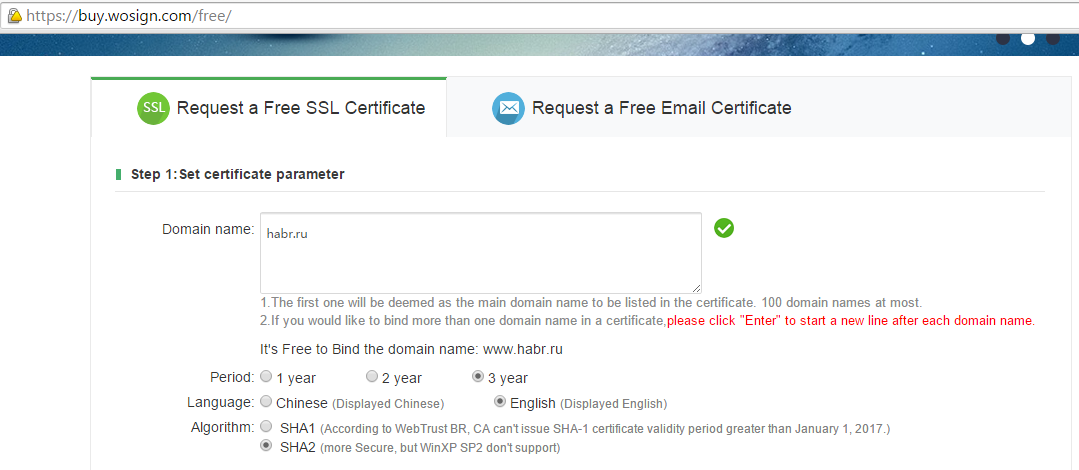
Вчера обнаружил, что WoSign дает бесплатно сертификат, теперь уже на 3 года.

Программист



 Предлагаем Вашему вниманию интервью с Сергеем Семеновым aka Serge (на Хабре ion2), одним из самых продуктивных разработчиков в проекте KolibriOS.
Предлагаем Вашему вниманию интервью с Сергеем Семеновым aka Serge (на Хабре ion2), одним из самых продуктивных разработчиков в проекте KolibriOS. Разработка веб API это нечто большее чем просто URL, HTTP статус-коды, заголовки и содержимое запроса. Процесс проектирования – то, как будет выглядеть и восприниматься ваш API – очень важен и является хорошей инвестицией в успех вашего дела. Эта статья кратко описывает методологию для проектирования API с опорой на преимущества веба и протокола HTTP, в частности. Но не стоит думать, что это применимо только для HTTP. Если по какой-то причине вам необходимо реализовать работу ваших сервисов используя WebSockets, XMPP, MQTT и так далее – применяя большую часть всех рекомендаций вы получите практически тот же API, который будет хорошо работать. К тому же полученный API позволит легче разработать и поддерживать работу поверх нескольких протоколов.
Разработка веб API это нечто большее чем просто URL, HTTP статус-коды, заголовки и содержимое запроса. Процесс проектирования – то, как будет выглядеть и восприниматься ваш API – очень важен и является хорошей инвестицией в успех вашего дела. Эта статья кратко описывает методологию для проектирования API с опорой на преимущества веба и протокола HTTP, в частности. Но не стоит думать, что это применимо только для HTTP. Если по какой-то причине вам необходимо реализовать работу ваших сервисов используя WebSockets, XMPP, MQTT и так далее – применяя большую часть всех рекомендаций вы получите практически тот же API, который будет хорошо работать. К тому же полученный API позволит легче разработать и поддерживать работу поверх нескольких протоколов.
Рекурсия: см. рекурсия.
 Все программисты делятся на 112 категорий: кто не понимает рекурсию, кто уже понял, и кто научился ею пользоваться. В общем, гурилка из меня исключительно картонный, так что постигать Дао Рекурсии тебе, читатель, всё равно придётся самостоятельно, я лишь постараюсь выдать несколько волшебных пенделей в нужном направлении.
Все программисты делятся на 112 категорий: кто не понимает рекурсию, кто уже понял, и кто научился ею пользоваться. В общем, гурилка из меня исключительно картонный, так что постигать Дао Рекурсии тебе, читатель, всё равно придётся самостоятельно, я лишь постараюсь выдать несколько волшебных пенделей в нужном направлении.— Как она сложена?
— Превосходно! Только рука немного торчит из чемодана.
def fib(n):
if n<0: raise Exception("fib(n) defined for n>=0")
if n>1: return fib(n-1) + fib(n-2)
return n
@memoized
def fib(n):
if n<0: raise Exception("fib(n) defined for n>=0")
if n>1: return fib(n-1) + fib(n-2)
return n
def fib(n):
if n<0: raise Exception("fib(n) defined for n>=0")
n0 = 0
n1 = 1
for k in range(n):
n0, n1 = n1, n0+n1
return n0

Расскажи мне полуправду, как полуэльф полуэльфу...