Добрый день!
Долгое время на просторах интернета я искал информацию о реализации AJAX загрузки файлов для CodeIgniter. Разные разработчики предлагали разные технологии и примеры реализации. Я перепробовал их все, но ни одна из них не была достаточно проста и функциональна одновременно. Лишь недавно я открыл для себя jQuery File Uploader. «Он ничем не отличается от остальных» — скажите вы, но это не так. Его главное отличие — это простота и хорошая документация с примерами. В документации разобраны все callback'и, описаны все options. Внедрение в любую систему не занимает много времени.
Сегодня я покажу как можно очень просто организовать multipart загрузку файлов на сервер + drug&drop в CodeIgniter.
Долгое время на просторах интернета я искал информацию о реализации AJAX загрузки файлов для CodeIgniter. Разные разработчики предлагали разные технологии и примеры реализации. Я перепробовал их все, но ни одна из них не была достаточно проста и функциональна одновременно. Лишь недавно я открыл для себя jQuery File Uploader. «Он ничем не отличается от остальных» — скажите вы, но это не так. Его главное отличие — это простота и хорошая документация с примерами. В документации разобраны все callback'и, описаны все options. Внедрение в любую систему не занимает много времени.
Сегодня я покажу как можно очень просто организовать multipart загрузку файлов на сервер + drug&drop в CodeIgniter.
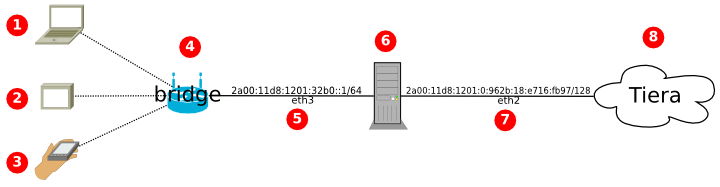
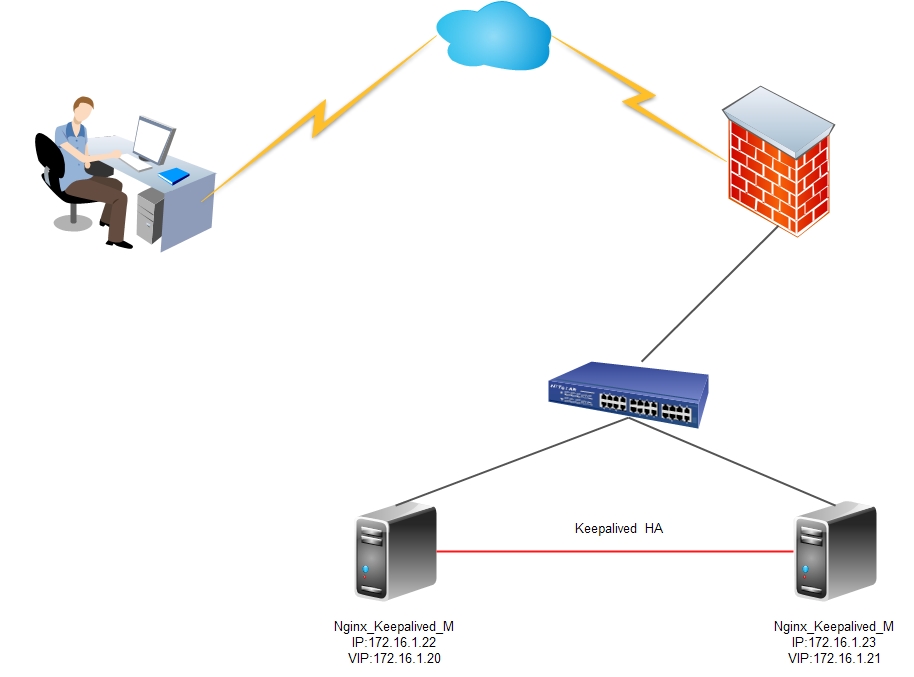

 +
+ 
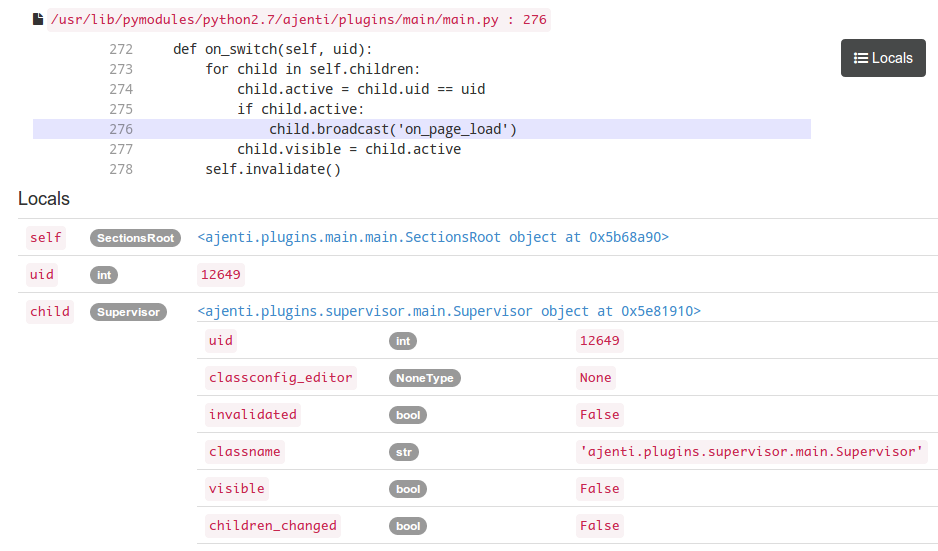
 В институтах студентов учат интегрировать аналитически, а потом обнаруживается, что на практике интегралы почти все считают численными методами. Ну или по крайней мере проверяют таким образом аналитическое решение.
В институтах студентов учат интегрировать аналитически, а потом обнаруживается, что на практике интегралы почти все считают численными методами. Ну или по крайней мере проверяют таким образом аналитическое решение.


 Сервис email-маркетинга
Сервис email-маркетинга