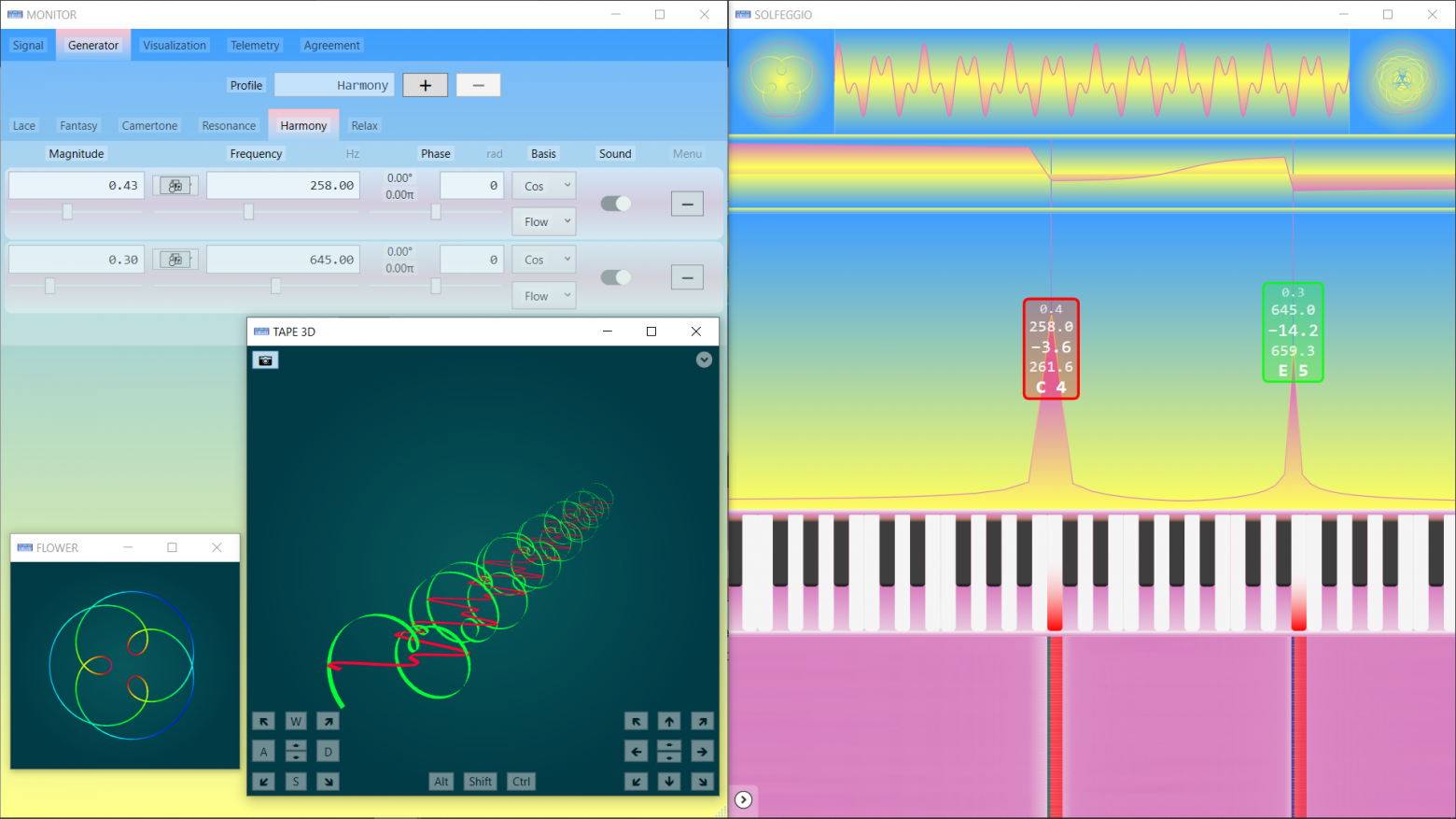
Удивительно, но существуют строгие математические методы, которые в буквальном смысле позволяют услышать визуальные геометрические формы и наоборот узреть красоту музыкальных гармоний...

Пользователь
Удивительно, но существуют строгие математические методы, которые в буквальном смысле позволяют услышать визуальные геометрические формы и наоборот узреть красоту музыкальных гармоний...
Алгоритмы важны. Но реализовать их можно очень по-разному.
При одном и том же алгоритме, оптимизированная библиотека будет в тысячу раз быстрее наивной.
Любите оптимизации, специализированные структуры данных и трюки с битами? Тогда скорее под кат!


В данном гайде будем устанавливать пакет sing-box на OpenWRT на примере стабильной 22.03.5 и 23.05.0. Рекомендуется роутер минимум с 128 МБ RAM (256 предпочтительно) и памятью более 16 Мб, так же будет описан способ установки sing-box в оперативную память (подходит для устройств с малым количеством ПЗУ <16 Мб)
Sing-Box — это бесплатная прокси-платформа с открытым исходным кодом, которая позволяет пользователям обходить интернет-цензуру и получать доступ к заблокированным веб-сайтам. Это альтернатива v2ray-core и xray-core. Его можно использовать с различными клиентами таких платформах, как Windows, macOS, Linux, Android и iOS.
Помимо поддержки протоколов Shadowsocks (в т.ч. 2022), Trojan, Vless, Vmess и Socks, он также поддерживает ShadowTLS, Hysteria и NaiveProxy.
Руководство будет включать:
1. Установку из репозитория
2. Настройку sing-box для shadowsocks, vless, vmess, trojan и обход блокировок с помощью SagerNet GeoIP, Geosite
3. Настройку обхода блокировок с помощью GeoIP, Geosite от L11R
4. Установку sing-box в оперативную память и настройку автозапуска

Это третья и заключительная статья из цикла, в которой рассмотрим стандартную модель ранжирования документов в Elasticsearch.
После того как определено множество документов, которые удовлетворяют параметрам полнотекстового запроса, Elasticsearch рассчитывает метрику релевантности для каждого найденного документа. По значению метрики набор документов сортируется и отдается потребителю.
В Elasticsearch существует несколько моделей ранжирования документов. По умолчанию используется Okapi BM25.

В этой статье вы узнаете, как создать свою первую модель машинного обучения на Python. В частности, вы будете строить регрессионные модели, используя традиционную линейную регрессию, а также другие алгоритмы машинного обучения.

Установка клиента Outline (shadowsocks) одним скриптом.
Понадобится любая версия OpenWRT (проверялось на 19.07, 21.02, 22.03 и 23.05-rc1) и установленные пакеты kmod-tun и ip-full, а так же настроенный сервер Outline (shadowsocks).
Рекомендую роутер не меньше чем с 128 Мб ОЗУ, будут показаны варианты установки в ПЗУ и ОЗУ.
Использоваться будет пакет xjasonlyu/tun2socks.

UPD: у нас всё получилось, сайт работает kapi.bar, доработки ещё ведутся.
Пикабу долгое время было уютным уголком для обмена историями, опытом, творчеством, мнениями и эмоциями. Однако ряд нововведений, таких как отмена баянометра, изменение алгоритмов и скрытие отрицательных оценок, привели к потере духа оригинального портала. Многие из нас, пришедшие туда в молодости и теперь ставшие взрослыми, почувствовали, что наши ценности и мнения игнорируются. В ответ на это, мы, группа энтузиастов, создали "Капибару" – проект, который стремится сохранить лучшие стороны Пикабу, предоставляя пространство где пользователи сами решают какой контент "годный" и какой контент хотят видеть в своей ленте.


Привет, Хабр! Сегодня мы поднимаем тему недорогих ПК. Такие бывают очень даже нужны там, где нужен хоть какой-то компьютер, но бюджет сильно ограничен. Это может быть компьютер для школьника или для развлечений в офисе (пока никто не смотрит). Может быть даже компьютер для бабушки (сейчас есть очень продвинутые пенсионеры). И понятное дело, что любой читатель Хабра может сопоставить между собой сокет материнской платы и процессор, частоты памяти и разъем SSD-накопителя. Но вот вопрос как укомплектовать недорогой ПК, не переплатить за что-то в его составе и не потратить кучу времени — остается открытым. Ответ на него мы ищем под катом и обсуждаем в комментариях.

Привет! Меня зовут Глеб, я разработчик команды продукта «Сервис персонализации» в SM Lab. В цикле из трех постов я расскажу про основы полнотекстового поиска в Elasticsearch.
Данный цикл статей предназначен для всех, но будет особенно актуальным для тех читателей, кто только начинает свое знакомство с Elasticsearch. Я надеюсь, каждый из вас найдет что-то полезное для себя.
В первой части обсудим самые базовые понятия Elasticsearch. Во второй части разберем механизмы анализа текста и полнотекстового поиска. В заключительной части взглянем на стандартную модель ранжирования документов в Elasticsearch.
Итак, начнём с самых базовых понятий.

Это вторая статья из цикла. В первой части я рассказывал про самые базовые понятия Elasticsearch. В этом же посте разберем устройство анализа текста и немного пощупаем полнотекстовый поиск.
Несколько слов про анализ текста
Анализ текста — процесс преобразования оригинального текста в структурированный формат, оптимизированный под эффективное хранение и быстрый поиск.
Мы уже познакомились с некоторыми типами Elasticsearch, но в этом разделе будем рассматривать только два — keyword и text. Тип text анализируется для полнотекстового поиска. Тип keyword преимущественно остается без изменений для точного поиска, сортировки и агрегации.

Как и множество больших сервисов, Яндекс Еда основана на микросервисной архитектуре. В общей сложности у нас чуть больше 200 микросервисов. Но есть один сервис, который совсем не микро – легаси-монолит.
Он написан на PHP 7.2 разработчиками разного уровня и в разное время. Мы подумали, что так больше нельзя, и решили навести порядок. В ходе разбирательств выяснилось, что версия языка, на котором всё написано, устарела и уже не поддерживается, что ведёт к рискам безопасности. Делать нечего — мы приняли решение обновиться до 8-й версии.
В этой статье я расскажу, чего стоило нам проапгрейдить монолит, сколько тестов мы сломали и как в этом проекте поучаствовали почти все PHP-разработчики Яндекс Еды. Это интересный и уникальный опыт, которым я хотел бы с вами поделиться. В конце дам несколько советов тем, кто тоже захочет ввязаться в подобную авантюру.

"Не используйте регулярки - иначе вместо 1 проблемы, у вас их станет 2!" - как то так говорят знатоки... А что остается делать непослушным, желающим эффективный поиск по большому количеству шаблонов?
Да, для такой довольно специфичной проблемы существуют крутые решения вроде Ragel или re2c. Тем не менее, для своего проекта мне показалось нецелесообразным пока осваивать эти прекрасные технологии.
В этой статье мы рассмотрим альтернативы стандартной библиотеке для регулярных выражений в Go, проведем их бенчмарк по скорости и потребляемой памяти. А также с практической точки зрения рассмотрим различия между ними.

Доброго дня! Представляю вашему вниманию очередной дайджест новостей из мира PHP.
В этом выпуске: новые версии PHP, новости RFC, новости популярных фреймворков, обзор интересных статей и многое другое.
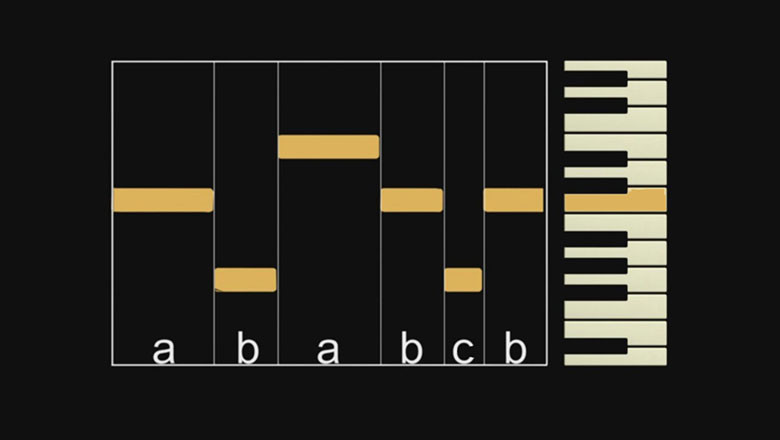
Простая идея: длительность каждой ноты мелодии в паре с длительностью соседней ноты, прошедшей или будущей, образуют пропорцию золотого сечения. Что из этого вышло - расскажу в небольшой статье.
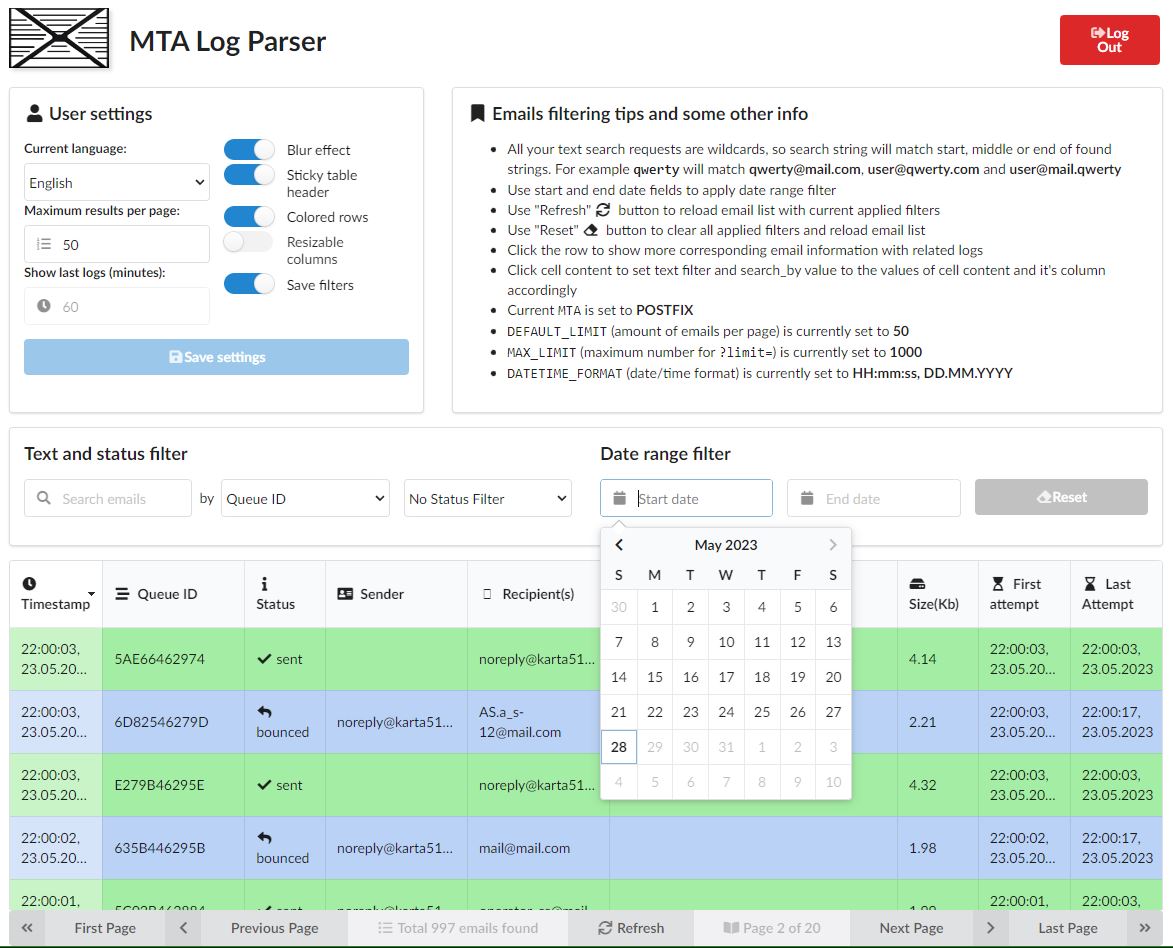
Эта моя первая коротенькая статейка на Хабре в попытке сделать проект, который делал для себя в целях самообразования и применения на работе, полезным кому-то еще. Можно было бы написать больше букв, но ввиду особенностей профессиональной деятельности, времени на это мягко говоря не очень много. Кто заинтересуется, всегда может подробности почерпнуть самостоятельно на гитхабе.

Привет, Хабр! Меня зовут Евгений Лабутин, я разработчик в МТС Digital. Расскажу вам о том, как мы на нашем проекте МТС Твой бизнес собираем логи с клиентских веб‑приложений. А еще обсудим вспомогательный микросервис логирования, который мы вывели в Open source, и поговорим о том, как устроено логирование в принципе.

Привет! Предлагаем вашему вниманию перевод не новой, но способной оказаться полезной статьи. Автор делится полезными возможностями утилиты Mysqldump.
