
Цель статьи - рассказать про простой и в тоже время рабочий вариант создания системы распознавания лиц, используя только модели из коробки, а именно ,библиотеку InsightFace для обнаружения и предобработки лиц и Catboost для их классификации.

User
Цель статьи - рассказать про простой и в тоже время рабочий вариант создания системы распознавания лиц, используя только модели из коробки, а именно ,библиотеку InsightFace для обнаружения и предобработки лиц и Catboost для их классификации.

Плагины VS Code, без которых техническим писателям и разработчикам документации жить можно, но сложно. В подборке — линтеры, форматирование, работа с git, проектирование API, подготовка схем и милота для удобной разработки.

Представьте себе, что в мире есть волшебное средство, которое в 7 раз повышает эффективность обучения — быстрее выучить английский, быстрее освоить программирование, быстрее понять что угодно в мире.
Удивительно, но такое средство было найдено в 1990 году американским социологом Майклом Хоу. Он провел серию тестов среди студентов и определил, что пользователи «волшебного средства» в 7 раз лучше запоминали материал, легко вспоминали факты и легко применяли знания на практике.
Тот, кто использовал «волшебное средство» был наголову выше обычных студентов. «Обычные» хуже помнили материал и хуже его понимали, более того, даже одаренные отличники были слабее тех, кто использовал это «волшебное средство».
Это удивительное средство...
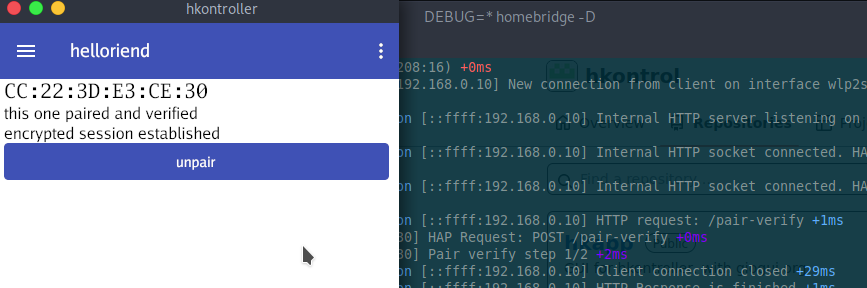
В данной статье речь пойдет про Apple HomeKit Accessory Protocol (HAP): внутренности и разработку контроллера.
Apple HomeKit создан для взаимодействия контроллера (по умолчанию iOS-устройства, приложение Home) и множества устройств(аксессуаров). Протокол открыт для некоммерческого использования, загрузить его можно с сайта Apple. На основе этой версии протокола создано несколько open-source проектов, и когда говорят про HomeKit на каком-нибуль Raspberry Pi обычно подразумевают установку homebridge и плагинов для создания совместимых аксессуаров.
Обратная же задача - создание контроллера - не такая распространенная и из проектов мне удалось найти лишь pypi.org/project/homekit/.
Поставим задачу создать контроллер, например, для управления аксессуарами с Android-телефона и попробуем ее решить. Для простоты будем работать только с IP-сетями, без Bluetooth.
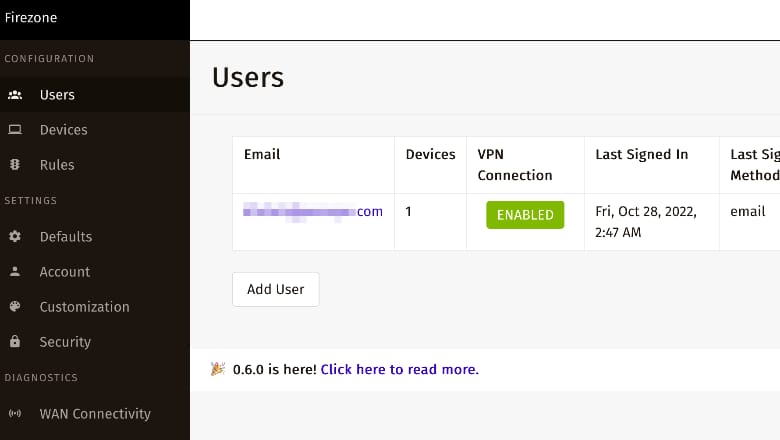
Задача организовать VPN в Москве или Спб для работы с сервисами не доступными с зарубежных IP и шифрования трафика для доступа к ресурсам компании при использовании публичного WiFi заграницей.
Остро потребность в VPN в России возникла после вынужденного отъезда части сотрудников зарубеж. Необходима возможность управлять пользователями, чтобы легко выдавать доступ сотрудникам.

Казалось бы, с документацией всё просто — пишешь, публикуешь, поддерживаешь актуальность. Например, вот у нас в Ozon есть пользовательские инструкции на docs.ozon.ru: выглядит просто как текст на сайтике, что ж необычного-то в его размещении и в целом в работе техписателей?
Если начать раскапывать, всплывёт ещё несколько вопросов:
• где хранить тексты и почему Confluence не подходит?
• как красиво оформить документацию с помощью статических генераторов сайтов
• зачем техписателям знать git и CI/CD?
• в какой момент пора искать разработчиков в команду и превращать документацию в платформу?
На связи Катя — руководитель отдела технических писателей в Ozon, и сегодня расскажу о платформе Docs Ozon изнутри.
В этой статье я разберу по косточкам все тайны квантовых компьютеров: что такое суперпозиция (бесполезна) и запутанность (интересный эффект), могут ли они заменить обычные компьютеры (нет) и могут ли они взломать RSA (нет). При этом я не буду упоминать волновую функцию и столь раздражающих Bob и Alice, которых вы могли встречать в других статьях про квантовые машины.
Первое и самое главное, что нужно знать - квантовые компьютеры не имеют ничего общего с обычными. Квантовые компьютеры по своей природе - аналоговые, там нет бинарных операций. Вероятно, вы уже слышали про Кубиты, что у них есть состояние 0, 1 и 0-1 одновременно, и благодаря этому вычисления выполняются очень быстро: это заблуждение. Кубит - это магнит (обычно атом или электрон), подвешенный в пространстве, который может вращаться по всем трем осям. Собственно, вращение магнита в пространстве - это и есть операции квантового компьютера. Почему это может ускорить вычисления? Было очень сложно найти ответ, но самые стойкие читатели увидят его в конце статьи. Начнем разоблачения.

Месяц назад я написал пост про то, как запили API + сайт демо на сайте Ternaus.com, где можно потыкать мышкой, чтобы оценить качество поиска.
Сейчас, в дополнение к картинкам добавлены bounding boxes и пост об этом.

Привет, Хабр! Сегодня расскажу о том, как мы в Fix Price закрыли проблему организации единой авторизации и аутентификации для наших сервисов с помощью Keycloak. Хотелось бы, чтобы эта статья оказалась полезной для всех, кто планирует внедрять это решение.
Начнем с общих моментов, а если хотите сразу перейти к коду, примеры вы найдете ниже. Их у нас целых 4, и все расписаны очень подробно. Поехали!

Сегодня мы с нашими друзьями из Snaplet открываем исходники postgres-wasm — запускаемый в браузере сервер PostgreSQL с полным набором функционала, включая сохранение состояния в браузере, восстановление из pg_dump и логическую репликацию из удалённой базы данных.
Впервые Postgres в браузере запустили в Crunchy Data, их потрясающая версия выложена на HN месяц назад. Вместе со Snaplet мы решили сделать версию с открытым кодом. Посмотрим, как она разрабатывается и какой функционал мы добавили. Подробности — к старту нашего флагманского курса по Data Science.

В этой статье я хочу затронуть проблемы построения алгоритмов масштабирования изображения.
Наверняка когда вы пытались найти алгоритмы масштабирована вы находили в первую что-то вроде: Существуют несколько алгоритмов самое простое это алгоритм Ближайший сосед потом билинейная , бикубическая интерполяция и.т.д
И какие могут быть проблемы?
Ну начнем с того, что по сути своей реализует масштабирована только алгоритм Ближайшего соседа, оставшиеся лишь реализуют сглаживание более пикселизированого и грубого изображения полученного таким способом. Нет вы конечно можете реализовать другие алгоритмы и без Ближайшего соседа, только ваш алгоритмом будет встроен тот же принцип. И вы просто сделаете свой код менее гибким и более усложненным.
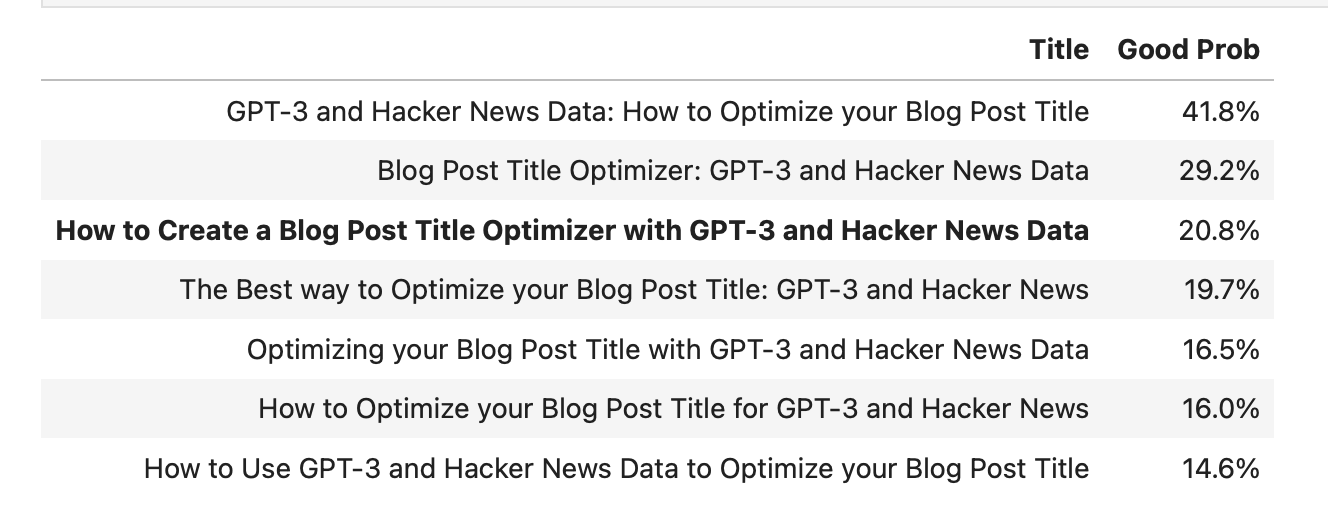
Система, основанная на GPT-3, сообщает о том, что заголовок для этой статьи (How to Create a Blog Post Title Optimizer with GPT-3 and Hacker News Data) очень плох.
Я, с объективной точки зрения, очень плохо умею придумывать заголовки для своих статей. И это — проблема, так как в наши дни всем известно, что хороший заголовок может оказаться единственным фактором, влияющим на то, «завирусится» ли статья, или останется никем не замеченной. Особенно это справедливо для таких сфер, как наука о данных и машинное обучение. Пишу я обычно именно об этом.
Почему бы мне не воспользоваться приёмами из вышеупомянутых областей знаний для создания оптимизированных заголовков для блог-постов?
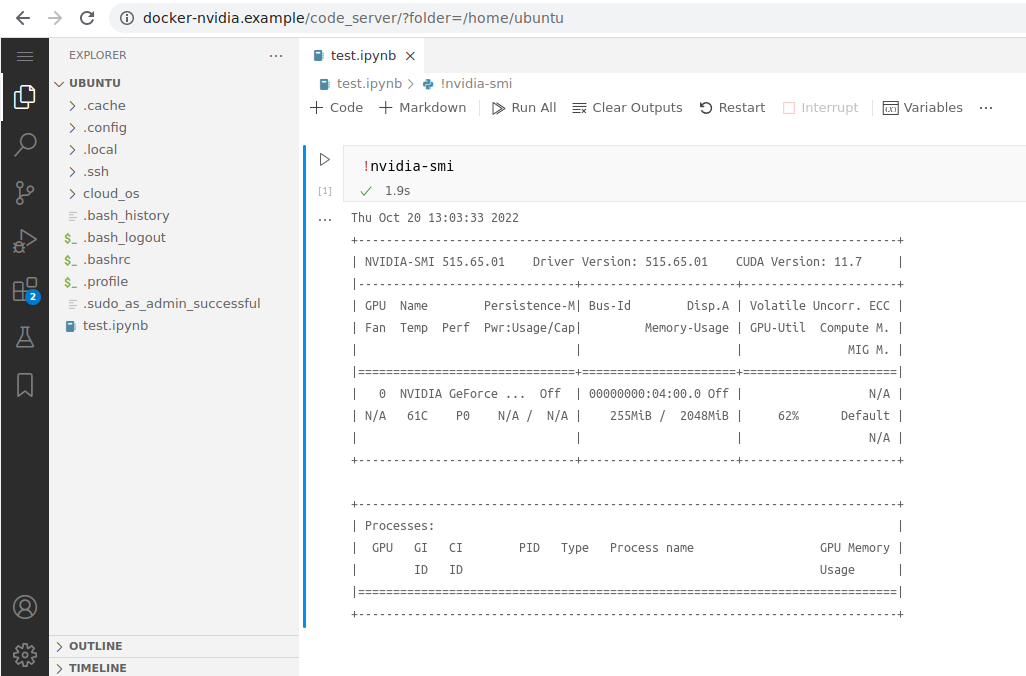
Привет Хабр! Меня зовут Ильдар. Сегодня я расскажу вам как настроить Visual Studio Code Server с плагином Jupyter ноутбук для работы с нейронными сетями в браузере на выделенном сервере используя Облачную ОС.

Сейчас можно найти довольно много файлов весов нейронных сетей, разработчики которых уже решили частые задачи и выложили результат под свободной лицензией. Это позволяет сэкономить время на обучении нейросети. Часто они были натренированы в фреймворке, который слишком громоздок для поставки на продакшн. Но их преобразование в более удобный вид может иметь подводные камни...

В этой статье, я опишу некоторые основные понятия в теории анализа временных рядов, классические статистические алгоритмы прогнозирования и интересные алгоритмы машинного обучения, которые применяются для временных рядов
Если Вы готовы погрузиться в одну из очень интересных тем статистики и Вы любитель машинного обучения, продолжайте читать :-)

Генеративно-состязательные сети (GAN) приобрели известность не так давно. Наиболее популярны эти сети в области машинного зрения. К старту нашего флагманского курса по Data Science рассказываем, какая математика у них под капотом.


PyTorch — среда глубокого обучения, которая была принята такими технологическими гигантами, как Tesla, OpenAI и Microsoft для ключевых исследовательских и производственных рабочих нагрузок.
PyTorch-Ignite — это библиотека высокого уровня, помогающая гибко и прозрачно обучать и оценивать нейронные сети в PyTorch. Основная проблема с реализацией глубокого обучения заключается в том, что коды могут быстро расти, становиться повторяющимися и слишком длинными. Рассматривать данную библиотеку буду, решая задачу оценки вероятности отнесения изображения к определенному классу на примере датасета CIFAR10. Чуть позже расскажу о нем подробнее. А сейчас начнем подготовку с установки и импорта необходимых библиотек.