В первой статье этого цикла я рассказал, как и почему мы выбрали опенсорсный Graylog2 для централизованного сбора и просмотра логов в компании. В этот раз я поделюсь, как мы разворачивали грейлог в production, и с какими столкнулись проблемами.
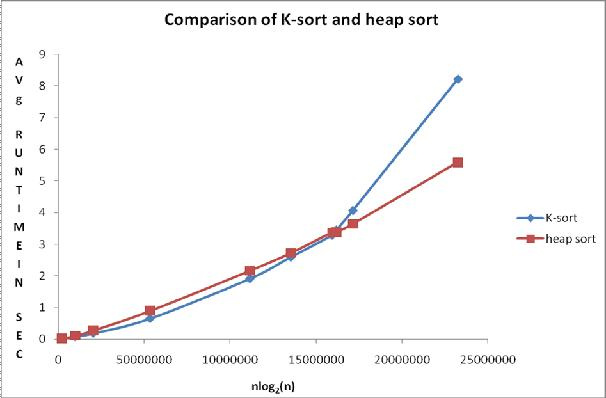
Напомню, кластер будет размещаться на площадке хостера, логи будут собираться со всего мира по TCP, а среднее количество логов — около 1,2 Тб/день при нормальных условиях.
В настоящее время мы используем CentOS 7 и Graylog 2.2, поэтому все конфигурации и опции будут описываться исключительно для этих версий (в Graylog 2.2 и Graylog 2.3 ряд опций отличается).








 Юнит тесты помогают нам удостовериться, что код работает так, как мы этого хотим. Одной из метрик тестов является процент покрытия строк кода (Line Code Coverage).
Юнит тесты помогают нам удостовериться, что код работает так, как мы этого хотим. Одной из метрик тестов является процент покрытия строк кода (Line Code Coverage).