
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
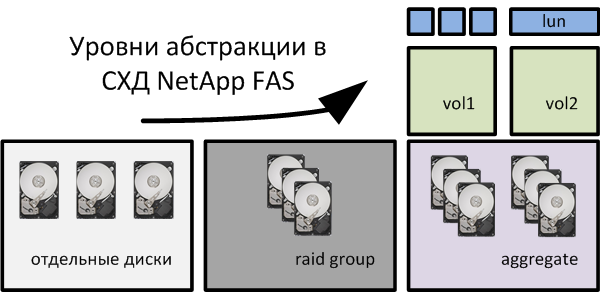
так была изобретена технология снепшотирования COW. Отличие этой технологии заключается в основном в том, что все другие файловые системы, как правило, не обладали встроенным механизмом записи «в новое место»,
Чем больше таких снепшотов тем больше дополнительных паразитических операций
{kind=link}
Парадигма резервного копирования NetApp