
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
C++ — это такой ужасный монстр. И иногда вместо C++ нужно использовать C. Чтобы вместо вот этого монстра использовать монстрика поменьше
Я считаю, у C++ нет самодостаточных подмножеств, не считая самого C++, разумеется (C, к сожалению, не является подмножеством C++). Попытка выделить некоторое подмножество C++ для своего проекта обречена на провал. Вот допустим, есть проект "в стиле C" для UNIX, я хочу заюзать в нём RAII для файловых дескрипторов (fd). Окей, написал свой объект-обёртку для fd. Потом выясняется, что нужно либо запретить копирование для этого объекта, либо реализовать в конструкторе копирования dup. И не зависимо от выбранного варианта нам нужно уметь возвращать наш объект из функции, а для этого уже нужен конструктор перемещения, а это уже C++11. Ну и так далее, так постепенно вы притянете весь C++ во всей своей красе.
When you’re programming C++ no one can ever agree on which ten percent of the language is safe to use. There’s going to be one guy who decides, “I have to use templates.” And then you discover that there are no two compilers that implement templates the same way
https://gigamonkeys.wordpress.com/2009/10/16/coders-c-plus-plus
Потом выясняется, что нужно либо запретить копирование для этого объекта, либо реализовать в конструкторе копирования dup. И не зависимо от выбранного варианта нам нужно уметь возвращать наш объект из функции, а для этого уже нужен конструктор перемещения, а это уже C++11
https://gigamonkeys.wordpress.com/2009/10/16/coders-c-plus-plus
Уже лет 20 нет ни одной причины не использовать вместо него си с плюсами, даже для системных вещей, тем более что в с-стиле можно и на плюсах прекрасно писать.
Есть. libstdc++ во флешу не пролазит. Толстая слишком.
4ГБ
У нас 32КБ
То, что это в публичном стайлайде гугла написано, так это сильно не так внутри и сильно зависит от команд и наличия легаси кода
Вот что написано в публичном стайлгайде гугла.
On their face, the benefits of using exceptions outweigh the costs, especially in new projects.
А изначально это пошло из-за плохой реализации исключений в старых компилярах с точки зрения производительности.
Так в том-то и дело, что, по слухам, раньше включенная поддержка исключений замедляла программу даже в неисключительных ситуациях.
libstdc++ во флешу не пролазит. Толстая слишком.Давно, если честно, не смотрел, но были же проекты uclibc++ и подобные, все умерли?
И эти файлы надо заново читать и заново парсить при каждом вызове ls -l! Было бы гораздо лучше использовать бинарный формат. Или БД. Или некий аналог реестра. Как минимум для вот таких вот критичных для производительности ОС файлов.
printf внезапно является далеко не самым быстрым способ вывода информации на экран или в файл
Собственно, какая вам разница, будет ли конец строки обозначать символ \0 или символ \n?
Форматируемый вывод оказывается не самый быстрый вывод! Я прямо-таки потрясен этим откровением. А нет, не потрясен. Это все написано в любой книге по С.
Окей, может быть вы это уже знали. А я это в своё время не знал. Я и подумать не мог, что, оказывается, вот этот вот дефолтный момент в C неэффективен. Я думал, что не могли же умные дядьки ошибиться и какую-то ерунду мне подсунуть. Естественно, в какой-то момент я начал догадываться, что форматный вывод неэффективен. Но опять-таки, я подумал, что раз C делали умные дядьки, то, видимо, он не до такой степени медленный. Но нет, как я выяснил от автора H20, форматный вывод таки существенно медленнее неформатного. Ну вот я сейчас этим откровением с Хабром делюсь.
Вдобавок, во многих реализациях стандартной библиотеки C++ (как минимум до недавнего времени) потоки ввода-вывода были реализованы поверх форматных функций C! (Facepalm!) То есть в API C++ строк формата уже нет, внутри всё можно реализовать без них. Но эти идиоты всё равно внутри пихают форматные строки. Чтоб медленнее было. Я-то думал, что программисты умные. Что реализуют всё всегда как надо. Как бы не так! Есть ли этот баг по-прежнему в основных реализациях стандартной библиотеки C++, я не знаю. Вполне мог остаться
Согласен — начиная с 7ки, угрохать регистр падением системы стало практически невозможно.
На каком?
У меня есть многострадальный комп, которым мне лень заниматься. Для кино и всякого. У него что-то с железом, что он часто ресетится. Иногда не включается. Но проводом подергал и завелось. Пару раз вис и не загружалась винда из за одного диска. Я его и сам не жалею. Долго выключается — ресет, долго думает — ресет, долго не включается — ресет. Винде по барабану. Живет не тужится.
Долго выключается — ресет, долго думает — ресет, долго не включается — ресет
Про существование зомби-процессов все говорят: «It's for design».
Обычном kill'ом зомби не убиваются
Если есть зомби, то скорее всего родителя уже нет. Просто нет. Нет, от слова совсем. Со всеми данными.
Зомби-процесс — это дочерний процесс, родитель которого не удосужился получить код завершения через wait. Если родитель умирает, то зомби наследуется init, который его без сожалений убивает.
То есть, наличие зомби говорит о том, что родитель как раз есть. Другое дело, что в нём баг, но процесс есть.
Не понимаю, за что заминусовали tgz.
Да, согласен. Просто осиротевшего зомби в *NIX усыновляет процесс с PID=1, а его по инерции часто init называют. Хотя, конечно, всё может быть и по-другому.
Это как-то подтверждает ваши слова, что наличие зомби свидетельствует о смерти родителя? Или что вы хотели сказать?
Или что вы хотели сказать?
29755 pts/0 Ss 0:01 \_ /bin/zsh
6123 pts/0 S+ 0:00 | \_ ./zombie
6124 pts/0 Z+ 0:00 | \_ [zombie]
[some magic]
29755 pts/0 Ss 0:01 \_ /bin/zsh
6123 pts/0 S+ 0:00 | \_ ./zombie
И зомби умер. Без убивания папы.
20157 ? Ssl 0:09 gvim
20163 ? Z 0:00 \_ [python3]
Зомби мне не нужен, а vim содержит несохраненные данные. То есть вы утверждает, что где-то в стандарте posix описывается способ удаления zombie, который не сводится к вызову wait со стороны процесса родителя и гарантированно работает? Поделитесь выдержкой из Posix или SUS.
# gdb
(gdb) attach 19595
(gdb) call waitpid(19698,0,0)
$1 = 19698
(gdb) detach
Ну так и на линуксе народ автоматизацию на питоне сейчас каком-нибудь пишет.
Ну, а если вам надо что-то автоматизировать в юниксах, то вы можете взять даже шелл. А можете любой вариант из десятков других. Но в простейш4м варианте даже на шелл можно что-то делать вменяемое.
К сожалению, их более новые и продуманные системы, где решены многие из упомянутых проблем — OS Plan9, OS Inferno — не взлетели. Не нужны народу элегантные системы, в которых нет этих костылей — наверное, скучно без них. Я много лет работал с OS Inferno, и это буквально "открыло глаза" на многие проблемы *NIX. Пока радует только рост популярности Go, может хоть одна из их попыток хоть немного исправить сверх-популярные UNIX и C спустя 40 лет окажется относительно успешной.
Не нужны народу элегантные системы
Итак, я не хочу сказать, что UNIX — плохая система. Просто обращаю ваше внимание на то, что у неё есть полно недостатков, как и у других систем. И «философию UNIX» я не отменяю, просто обращаю внимание, что она не абсолют.
Вот именно что обернуты а не выкинуты. В этом и суть костылей. ..
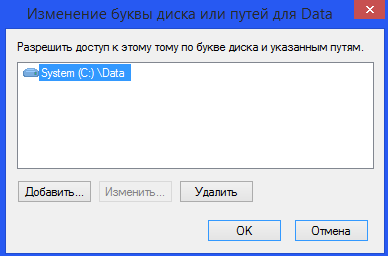
Откройте в винде (XP или 7) "Управление компьютером", далее "Управление дисками", выберите какой-нибудь раздел и там "Сменить имя диска или путь к диску". Там можно удалить букву диска и назначить ему вместо этого путь, куда надо монтировать. Далее в винде есть ключ/ветка реестра MountedDevices, я вот тут писал: https://geektimes.ru/post/156749/
но если мы посмотрим на атрибуты файловой системы NTFS мы увидим расширения UNIX, такие как пользователь, группа и режим доступа (они есть, на самом деле).
Начнем с самого простого и очевидного (то что на виду), любое устройство является файлом,
но если мы посмотрим на атрибуты файловой системы NTFS мы увидим расширения UNIX, такие как пользователь, группа и режим доступа (они есть, на самом деле).
Дальше — это организация архитектуры процессов и…
ACL в NTFS были изначально, ещё до того, как появились эти самые «расширения UNIX», и до того юниксоидам приходилось извращаться с политикой доступа через rwxrwxrwx, что намного менее гибко. И причём тут символические и жёсткие ссылки?
Или некий аналог реестра
gconf/dconf, разве нет? Да и транзакционную sqlite некоторые приложения используют. А благодаря тому что конфиги отдельной программы потенциально находятся во вполне определённых директориях становится воможным ПОЛНОЕ удаление приложения так, что система вернется к состоянию когда приложение не было установлено (в Windows большинство приложений не могут собственную папку удалить из Program Files при деинсталляции, не говоря уже о жести с происходящим в реестре).
Не пытаются, а успешно занимаются. Но как вы правильно заметили, только системными, которые устанавливались с пакетами и, возможно, менялись пользователем. Но я ни разу не видел приложения, которые удаляют конфиги из домашней папки. К счастью есть всего несколько папок и несколько веток в dconf где с 99% вероятности будут конфиги приложения. Почистить это совсем не сложно.
Хотя (в теории) можно повесить хук на удаление и подчищать даже пользовательские конфиги, но, повторюсь, ни разу такого не видел.
В домашней директории пользователей лежат не конфиги, а файлы пользователей.
файл пользователя, который пользователь или явно написал сам, или натыкал в графическом меню программы softname
Но как лирическое отступление, например, пакетный менеджер apt (Ubuntu/Debian/etc) поддерживает команду purge, которая пытается удалять программу вместе с ее конфигами. Так что по мере возможностей, некоторые более или менее популярные пакетные менеджеры, по крайней мере в Linux, пытаются заниматься конфигами.
В том-то и дело, что программа не должна лезть куда-либо за пределы своей песочницы. Пусть пишет в свои ./user/ и ./local/ а система уже разберётся что в эти директории примонтировать.
Он должен контролировать что и где ей позволено делать и изолировать результаты её деятельности от других установленных приложений, если иное явно не разрешено пользователем.
Не зацикливайтесь на термине "пакетный менеджер". Почитайте, например, про докер, который и скачает, и поставит, и соединит, и проконтролирует, и сбалансирует, и изолирует, и залогирует, и заверсионирует. И для этого не надо править сотню конфигов в десятках мест. Именно так должны выглядить OS в 2017.
Вы не поверите: http://rancher.com/rancher-os/
Что не OS, что оверкилл, что ничего не контролирет и пр. Или за ОС вы только ядро считаете?
Думаете суть бы изменилась, если бы её назвали DockerOS? Или если бы функционал докера перенесли в ядро?
А судя по картинке — использует.
Может — вообще имело смысл хранить все программы их модули, конфиги и библиотеки, в базе данных с версионированием, зависимостями, горячей заменой в памяти и прочими полезными вещами.
Но, во времена создания юникса всё это можно было реализовывать только в мечтах — по причине недостаточного технического и научного уровня тех лет. А без исходного кривого юникса не было бы современной идеи свободного ПО и самого ПО.
Поэтому в историческом плане юникс с потомками и язык С — все таки вещи положительные.
И, самое главное, опыт их применения и собранные грабли дают понимание того, как не надо в будущем делать и использовать ОС и языки — особенно, огромными группами разных людей и организаций, с разными целями и возможностями, никогда не пересекающихся между собой в пространстве и времени, расходясь на тысячи километров и десятилетия.
Ни один язык программирования или иная технология пока даже не пытается взвалить на себя такую неподъёмную задачу, но, сделать это все равно кому то когда то придётся — хотя бы для того, чтобы попытаться перестать терять деньги от замены дублирования старого кода.
А, так как отправить на пенсию существующие технологии пока не получается, то, наверное, значит, что предел их прочности ещё не достигнут.
Советую почитать о flatpak и snap
В винде проблема с удалением именно в том, что у каждой программы свой деинсталятор, а разработчики деинсталятора забивают на качество его работы.Такие люди и на качество самого приложения обычно тоже забивают. Например, положат в виндовом реестре в HKLM то, что должно лежать в HKCU, а потом ещё пишут свой собственный велосипед для реализации HKCU внутри узла из HKLM.
В винде проблема с удалением именно в том, что у каждой программы свой деинсталятор, а разработчики деинсталятора забивают на качество его работы.
Если бы у этого MSI было чуть-чуть по-больше документации… Потому что сейчас "не могут в MSI" даже сами Microsoft.
Посмотрите на те же VC redistributable packages. Хоть одна доступна в формате MSI?
PS Привет пакету, кажется, от 2008, который при установке выдавал ошибку если он был уже установлен в системе :)
Да бардак с конфигами и линуксе и в винде. Где-то sqlite (читай — у каждого приложения свой формат в виде схемы БД), где-то gconf, где-то ini, где-то xml.
Разрабатывал программы (под windows), где одновременно используется 3-4 вида конфигов. Привести их к единому реестроподобному формату, кстати, не получилось. Файлы конфигов, конечно, можно удалять, но этот зоопарк всё-таки не выглядит "чисто".
Мне как пользователю совершенно не важно какой там конфиг. Главное чтобы я мог его очень легко найти в совершенно конкретном месте и удалить при желании (чтобы сбросить настройки или после удаления приложения). В Windows у меня этого никогда не получалось. Начиная с рядовых приложений разного калибра, и заканчивая компонентами с обновлениями самой ОС. Система постоянно патологически накапливает мусор.
gconf/dconf, разве нет?
Единственное, еще бы договорились, который из них оставить. Вот в упор не понимаю, зачем их ДВА.
Установили php7.0-fpm, в папку apache2 скопировался его конфиг для этого веб-сервера. Удалите пакет — удалится и директория. Всё под контролем менеджера пакетов. Да, кривовато слегка, но всё вполне логично.
И не должен. Есть пакет, в котором прописано его содержимое и куда это содержимое должно быть установлено, и откуда после удаления должно быть удалено. Да, сам пакет мог бы иметь соответствующие хуки, но мейнтейнеры пакета, видимо, не стали заморачиваться.
Как в Windows, так и в UNIX-системах можно полностью удалить любое приложение. При условии, что разработчик позаботился о корректном удалении. И зачастую при условии, что этим приложением пользовался только один юзер (иначе придётся во всех юзерских папках потом вручную удалять ошмётки).
В Windows это делается через панель управления, в UNIX-системах — через менеджер пакетов либо (если собирали из сорцов) с помощью make uninstall.
Другое дело, если разработчик накосячил с удалением. Тогда уже для винды нужно использовать всякие там full remover, а в случае с UNIX — всякие там checkinstall и пр.
И в случае обоих систем (Windows и UNIX-подобное) если вам нужна абсолютная гарантия полного удаления пакета — восстанавливайте ОС из бекапа. (Замечу, что NixOS [как минимум в теории] поддерживает абсолютное удаление; так, как если бы система была восстановлена из бекапа; потому что там состояние всей ОС определяется всего небольшим количеством конфигов)
Лучше всё же формат Tree, он и машиной и человеком легко читается, чего не скажешь о JSON и XML.
Вы так говорите, будто написание тривиального парсера/сериализатора — это самая существенная проблема при переписывании всех этих текстовых утилит на структурированную выдачу.
Может именно поэтому линукс и утопает в легаси и не способен выбраться из этой трясины? Вместо стремления к стройности и простоте, во главу угла ставится совместимость с древними костылями, которые все ненавидят, но продолжают плакать, но есть.
Что значит "менять"? Сейчас приложения выдают плоский текст без какой-либо структуры. Так что вкручивать любой формат одинаково сложно и выбирать нужно не по принципу "для какого там формата есть либы для большего числа языков" (ответ — XML, но слишком громоздкий во всех смыслах), а по принципу "какой формат лучше подойдёт", а либы под разные языки быстро появятся, если формат не такой сложный, как YAML, последней версии которого, до сих пор почти нигде нет.
Неужели в IT всё оценивается чисто экономически?
А как же красивый код, идеальная архитектура, тяга к прекрасному, и прочая ерунда)
Я все это говорю к тому, что переход на новое возможет только тогда, когда возможности старого абсолютно исчерпаны и написание костыля обойдется дороже, чем просто взять и написать заново.
Исправить ошибку как можно скорее можно только когда поезд еще не ушел.
Грамотный системный архитектор так ведь делать не станет. А заранее продумает всё так, чтобы было хорошо и красиво. А если уже продумано неправильно, и поезд ушёл — исправит ошибку как можно скорее, а не дожидаясь того момента, когда «всё, катастрофа, поддерживать это не реально». Имхо
Если это стартап, то ситуация может быть следующая:
Отдельным пунктом, если стартап нанимает аутсорсинг, желая сэкономить на расходах, добавляется возможное отсутствие ТЗ как такового либо наличие очень сильно чернового и неполного варианта. Не забудем что на нормальное тестирование у стартапа денег тоже нет и тестирование многих фич происходит на основании неполного ТЗ самими аутсорсерами в сжатые сроки.
З.Ы. Добро пожаловать в мой мир
А что мешает потратить неделю-две на дизайн до пункта 2?.. Там-то никто не гонит :)
Ничего, кроме торопливости начальства и ТЗ с детализацией уровня "как-то так должно работать".
Если проект очень сложный — может, займёт и дольше, но мы же про относительно простые стартапы, верно?
Ну, в том случае о котором я говорю, проект с огромным количеством разного функционала. Не назвал бы его простым.
З.Ы. Я говорю со стороны аутсорса и, будь моя воля, закончил бы отношения с этим стартапом уже через месяц. Все более или меннее нормализуется только на 3й год разработки после длительного хождения по одним и тем-же граблям, которые заказчик сам себе заботливо перекладывает вперед.
Я почему-то думал, что в стартапе разработчики — сами себе начальство. Ну и кто-то один главный. Так только в кино бывает? :)
Ну, по-началу, оно может так и есть, но со временем количество людей растет и появляются начальники и стартап становится нормальной компанией. Правда бывают стартапы-переростки: начальники есть, а порядка нет. Тогда-то и начинается беда.
Потому и писал, что к пункту 2 времени в теории — неограниченное количество, если конечно нет конкурентов с той же идеей.
А как же теория спелых яблок?
Мне казалось, что popov654 шутит...
А в этих "других языках" вы использовали какие-то индексные структуры? По-хорошему этот дамп нужно впихнуть в любую БД, построить индексы и искать по ним. В redis, наверно, так и получилось. sqlite, думаю, тоже подойдёт (да хоть MS Access, бывало и такое).
grep использует всякие продвинутые алгоритмы строкового поиска, которые вряд ли есть в стандартных библиотеках php/python/etc. Вручную быстрее вряд ли напишете.
Вы только представьте! Вот допустим, нужно удалить все файлы в текущей папке с размером, большим 1 килобайта. Да, я знаю, что такое надо делать find'ом. Но давайте предположим, что это нужно сделать непременно ls'ом.
Вот допустим, нужно забить гвоздь. Да, я знаю, что такое надо делать молотком. Но давайте предположим, что это нужно сделать непременно микроскопом...
Так в данном случае это как раз прекрасно, что система позволяет забить гвоздь микроскопом (если очень хочется, или религия не позволяет молоток использовать, или старшина приказал). Но тут уж не стоит удивляться тому, что сделать это сложнее, чем молотком.
Однажды постучался я по ssh на девайс, ввожу find . -iname "*.jpg" -exec cp {} ./ \;, а он мне такой: а нету тут find-а!
Статья написана наскоро, «полировать» дальше не хочу, скажите спасибо, что написал.
@DexterHD, nightvision, стиль статьи, слова "бугога" и пр. — это типичное явление в американских блогах, в том числе в переводах статей из американских блогов на Хабре, почитайте их (хотя у меня не перевод). Особый стиль нужен, что "встормошить" читателя, который и вправду фанатеет от UNIX. Сказать ему, так сказать: "Проснись, UNIX давно устарел!"
Посмотрите мой коммент выше, DexterHD (я не уверен, что парсер Хабра вас с первого раза пинганул)
@basilbasilbasil, kirillaristov, сарказм, отсылка к философии UNIX? Что? А, вон оно что! :) В общем, нет, я об этом не подумал, это было сказано в прямом смысле
сарказм, отсылка к философии UNIX? Что? А, вон оно что! :)

Посмотрите мой коммент выше, basilbasilbasil, я не уверен, что парсер Хабра вас пинганул
Назовите хоть одну вещь из Windows, которой не хватает в нынешних *NIX?
Also есть scons.
Э… Debian wheezy? :)
Как вы еще разрешите всем пользователям компьютера создавать папки в корне диска, но запретите им "залезать" в чужие?
Это nested groups, а не nested acl. Данная фича относится к модели безопасности системы, а файловая система работает с группами пользователя как с данностью.
Добавьте в linux возможность одни группы включать в другие (если ее там еще нет) — и все файловые системы получат поддержку этих групп автоматически.
Лол, по-моему все новомодние FS включают настолько всего много, что ACL там есть по дефолту.
Кстати ACL были в UFS с 2005, а acl nfs уровня с 2009, бородато. Не знаю насчет EXT но другие ФС поддерживают это давно.
ZFS это включает из коробки почти с рождения, если мне не изменяет память.
Конечно если жить во времена FreeBSD 4, когда мелгкомягкие перли все у всех для своей новой Win NT, тогда да, NTFS был крупным апгрейдом.
А сейчас когда я могу делать мгновенные снапшоты для 250 ZFS датасетов в одну секунду, делать ограничения на разных уровнях, иметь файловый доступ к снапшотам без маунтинга, возможность атомарного восстановления, компрессии разного рода, дедубликации, возможности дописывать метки и кастомные метаданные к датасетам (для конфигурирования бекапа например).
Все это с резервированием разного уровня и главное возможностью репликации по сети только изменений!
После этого NTFS выглядит древним мамонтом, который все ждут когда он вымрет.
Нет таймлайн корректен. FreeBSD 4 была all the rage back then, т.к. Linux был bleeding edge. Однако ФС была хоть и стабильной, но достаточно устаревшей на момент релиза. Windows NT 4 был all the rage, 3.1 3.5 не так известны, но несли в себе красивую NTFS.
ZFS в релизе с 7ки, с 8ки уже сплит пошел. С 7ки уже 9 лет прошло...
Все это с резервированием разного уровня и главное возможностью репликации по сети только изменений!
powershell?
Thanks but no thanks :D
Смайлик, конечно, классный аргумент, но не могли бы вы поделиться с нами, почему упоминание powershell вызывает у вас истеричный смех?
Без проблем, я не буду искать статьи в бложиках, напишу отсебятину.
Powershell, конечно, отличная замена CMD, однако это по сути "у нас 13 стандартов… теперь 14". Шеллы конечно не прелести, но powershell кажется чем-то вроде интерпретатора, в котором случаем прикручена консоль и атрибуты командных ключей.
В итоге часто не ясно, команда это или шелл вызов или же .NET вызов.
В шелле *nix всегда ясно, что пайп, а что нет, ясность многое дает, когда необходимо делать дела быстро.
powershell имеет проблемы с запуском внешних утилит даже на винде. Точнее, с разбором их вывода.
Во-первых, любой вывод в stdout парсится как строка в текущей консольной кодировке. Если кодировка не совпадает — исходные байты восстановить может уже не получиться.
Во-вторых, любой вывод в stderr рассматривается как ошибка. Правильнее было бы вовсе не перенаправлять этот поток — но powershell так не умеет.
В-третьих (хотя на линуксе этот пункт будет неактуален) — задать кодировку консоли довольно сложно. Особенно при запуске через WinRM...
Если собираетесь сделать проект свободного ПО, не юзайте scons. Сам я ничего про него не знаю, но в debian upstream guide не рекомендуют: https://wiki.debian.org/UpstreamGuide. Во всех остальных случаях, т. е. если это просто некий проект, не предназначенный для выкладывания на публику в виде сорцов, то, видимо, можно
Возможно дело в том, что "самое удобное средство из доступных" никуда не годится?
То, что им пришлось навелосипедить своих костылей вокруг — замечательно иллюстрирует тезис о "никуда не годится". И я тоже нигде не говорил, про "самую удобную для всех и каждого", не выдумывайте.
Так, вместо make давно бы уже перешли на qbs.
qbs хорош, но кажется он рип, сам Qt не будет на него переходить, а будет переходить на cmake, а так аналог qbs, но без зависимости от Qt и с умением докачивать и собирать зависимости был бы неплох.
В принципе на замену make есть ninja, где все, вроде бы, сделано по уму, и на него таки потихоньку переползают.
У yaml все с отступами странно, можно огрести неплохих проблем с непривычки.
С моей точки зрения главный принцип философии юникс это декомпозиция на небольшие программы которые делают что-то одно и ему альтернатив не видать.
Если считать философией UNIX именно это (без отсылки к UNIX shell и пайпам), то ничего против такой философии я не имею (с оговоркой, что иногда большие и сложные программы типа Photoshop или [о боже!] Microsoft Office всё же подходят лучше). Проблема в том, что многие люди начинают относить к философии UNIX её конфиги, многие особенности написания скриптов на shell
они вполне могут соответствовать философии юникс, например быть гуём ко множеству утилит, философия гуй не запрещает
@worldmind предлагает сделать ворд более философским :)
del
Когда я делал очень большие документы в Word, там было не меньше проблем. Только эти проблемы в принципе устранить было нельзя. Если в latex можно еще раз перечитать мануал, попытаться что-то переделать, в крайнем случае, залезть в исходники, то если что-то не работает в Word, чаще всего нет никакого выхода. И latex все-таки работает по четко описанной логике. А в Word если 10 раз накликал мышкой новую строку в таблицу, а на 11 раз вся таблица исчезла или сморщилась, никакой логики нет — просто проявление очередного бага, и даже если удастся найти workaround, это не дает никакого бонуса — работать дальше не станет легче.
Правда в последний раз работал и с тем и с другим очень давно, более 10 лет назад. Надеюсь, что с тех пор качество Word поднялось.
"иногда большие и сложные программы типа Photoshop или [о боже!] Microsoft Office всё же подходят лучше"
например когда?
Представьте себе workflow некоего сотрудника. Это может быть программист, художник, писатель, кто угодно. Если workflow уже "устаканился", т. е. уже известно, что, в общем-то нужно будет делать сегодня, завтра и так далее, то всякие интегрированные среды, всякие IDE, фотошопы, офисы подходят лучше. Потому что там нужно сделать меньше телодвижений для выполнения действий. Там всё "просто работает".
Понимаете? Есть много видов деятельности, которые уже так сказать формализованы, чей workflow уже уложен в некую схему и разные интегрированные решения для этого workflow работают лучше.
А если ещё не "устаканился" и нужно постоянно решать новые непредусмотренные задачи, то типичный UNIX environment подходит лучше. Там можно вообще всё, если захотеть.
У программистов нужда в таком окружении происходит чаще, поскольку они чаще сталкиваются с разными нестандартными задачами. Поэтому программисты выбирают никсы чаще, чем художники, скажем.
Но даже программистам работать во всяких IDE обычно проще. Просто если ты разрабатываешь нечто совсем новое, скажем, новую ОС, тут уже IDE подход даёт сбой, т. к. там такого не предусмотрено. Тут уже берёшь в руки vim, emacs и прочее
Честно говоря, какой-то сырой текст, пытающийся разжечь холивор, но без изюминки. Вроде лет 25 назад написали The Unix Haters Handbook, по-моему, большинство вашей критики взято еще из этой книги, но все войны по ее содержанию уже лет 15 как отгремели, даже скучно уже ввязываться.
Первую треть еще как-то прочитал. Особенно насмешило про «недостаток» текстового формата /etc/passwd. Дальше уже было сложно заставить себя тратить время на текст, который сам автор признает сырым.
Осталось еще два соображения. Как это такая плохая система существует уже более 40 лет, пережила уже и многих критиков, и волны различных hype, адаптировалась и к gui, и к мейнфремам, и к маленьким компьютерам, переход на Unicode и многое другое, и все это без значительных усилий? Неужели это признак плохой продуманности?
Ну и раскритиковать можно что угодно, потому что любая вещь созданная людьми неидеальна.
Вы, наверно, не поверите, но с ВАЗом все обстоит именно так, как вы сказали. Просто классический жигуль разрабатывался для страны и людей, которых уже нет. Другое время, другие запросы.
Возможно, автору стоило бы отвести душу издав продолжение "The Unix Haters Handbook". Но, разумеется, уровень критики должен быть выше — ведь за прошедшие годы и *никсы подросли и задачи их и уровень ответственности ОС и видение её достоинств и недостатков, требований одновременно изменилось и прошло проверку временем.
Предложите что-нибудь на замену. К сожалению, 99% нынешних систем набиты костылями под завязку — даже перечислять не буду.
О, господи, ну и маразм с тем что все в файлах. Интерфейс у UNIX текстовый, соответственно хранить конфиги в тексте намного проще и понятнее человеку.
Разбирать не хуманизированный JSON или не дай бог XML глазками врагу не пожелаешь. INI или же банальные конфиги намного проще. Да сейчас есть YAML, но тогда его не было, а сейчас менять все на YAML поломает легаси.
Использовать реестр — вообще дурость, зачем нужна БД если есть кеш файлов? Реестр виндовый все равно не достаточно оптимизирован. Прелесть текстового формата в том, что ты открыл его и прочел, СРАЗУ осознав всю информацию, совершил необходимые манипуляции и закрыл его.
Да при 1000 юзеров уже надо использовать какую-то БД, однако утилиты для работы и так присутствуют так что этот вопрос тоже решен.
Человек что писал эти комментарии явно не понимает что UNIX использует KISS потому что необходимо понять и разобраться на месте, а не звонить Microsoft Support и ждать человека на следующей неделе если Вы не льете миллионы долларов в карманы мелгкомягких.
а сейчас менять все на YAML поломает легаси.
На мой взгляд — основная проблема как раз в поломке этой возведенной в абсолют и обожествляемой legacy. Да, все признают, что напрямую его не используют, все через обертки, костыли, подпорки, но вот взять и выкинуть все это подгнившее нутро и заменить внутри на что-то более современное — не-е-е-е, это ж legacy, а вдруг у какого Васи Пупкина две с половиной программы сломаются? Так и живем.
А ведь стоило бы начать хотя бы с давно уже предлагаемых ключиках к стандартным программам для структурированного вывода в JSON. Даже просто как JSON-текст выдавать в пайп (а не как уже готовый JSON-объект) — все лучше, чем современный бардак.
Так большинство конфигов не нужно далее CSV или KV хранилищей. Так оно и есть.
passwd это CSV без экранирования и с: в качестве разделителя. Остальные конфиги либо все K=V хранилища, либо уже в своем языке программирования тоже K=V хранилища, либо же на крайний случай INI, где вместо комментариев используют секции (что конечно же дурость микрософтовская, но что поделать).
Даже на винде большинство программ используют реестр только для регистрации ибо corruption реестра известная проблема издревле. Реестр Windows — это полнейший failure и очередной костыль.
Я даже написал администрирование и установку почтового сервера полностью БЕЗ использования БД ибо это намного проще в работе и с новыми ФС (ZFS) в частности желательно ИХ использовать как БД (где возможно). Ибо БД по сути костыль для древних систем, то самое легаси (соединительное между ФС и памятью). Сейчас набегут архитекторы SQL и будут меня разносить, на что я отвечу что перенести SQL язык в ФС проще, чем ФС в БД. В итоге меньше возможных точек поломок, меньшее количество администрирования, проще дебаггинг, стабильность со 99,99% годовым аптаймом. Со второй системой или отдельным закрытым ФС сервером можно аптайм до 100% поднять.
KISS в UNIX не от того что все дибилы, а от того что усложнение систем к стабильности не приводит.
Я думаю реализовать это так.
вызываем sub получаем список дочерних объектов:
/www/ sub
\demo
\index.html
\index.jsХотим вывести не всё — фильтруем:
/www/
sub
filter type \file
\index.html
\index.jsХотим конкретную инфу — дёргаем соответствующие инструкции для каждого объекта:
/www/
sub
filter type \file
map type
name
created
subCount
sub
count
file
name \index.html
created \2016-01-01T00:01:02Z
subCount 0
file
name \index.js
created \2016-01-01T00:01:02Z
subCount 0Хотим вывода в виде таблички — используем table:
/www/
sub
filter type \file
map type
name
created
table
| type | name | created
|------|------------|---------------------
| file | index.html | 2016-01-01T00:01:02Z
| file | index.js | 2016-01-01T00:01:02Z
Из предложенных вами вариантов можно выбрать какой-нибудь один, не сильно важно, какой именно. Это будет уже лучше, чем просто текст. Далее, опция -R вообще не свойственна ls. Здесь я согласен со старой статьёй Пайка, которая "cat -v considered harmful". -R не свойствена ls, как и -v не свойствена cat. Вместо ls -R нужно использовать find или find -ls. А вообще, да, вместо shell нужно использовать какой-нибудь другой скриптовый язык. :)
Окей, конфиги кешируются. Но парсить их нужно всё равно каждый раз
Человек что писал эти комментарии явно не понимает что UNIX использует KISS потому что необходимо понять и разобраться на месте, а не звонить Microsoft Support и ждать человека на следующей неделе если Вы не льете миллионы долларов в карманы мелгкомягких.
Так против KISS я ничего не имею. Я говорил про другие аспекты философии UNIX, читайте внимательно
Как сейчас модно говорить, у автора разорвало пукан!
Когда я только перешёл работать на linux (лет 10 назад) с windows у меня тоже было подобное настроение. Всё было неудобно, нелогично и убого. Вони было побольше, чем у автора. Но спустя пару лет я вдруг понял насколько проще работать и разрабатывать под Linux. На венду меня теперь не загнать. 25 лет пишу софт. Уж поверьте. :)
Так вот. Текстовые конфиги в большинстве своём имеют настолько примитивный формат, что парсятся на раз. И это огромная сила unix. В итоге, для настройки системы достаточно текстового редактора и интеллекта!
JSON и XML не годятся для человека. Они требуют сложного парсинга, трудно читаемы и их структуру легче поломать.
Для бинарных форматов вообще будут нужны специальные утилиты. И, если их форматы универсальны, так же требуют парсинга. В обратном случае хранимые бинарные структуры будут платформо-зависимы и требовать регулярного обновления при добавлении новых полей.
По поводу языка C тоже скажу. По сути это кроссплатформенный ассемблер. Он должен обеспечивать полный контроль над аппаратурой. Разве что он оффициально не подпускает к регистру состояния процессора со всякими там битами переноса, но во всём остальном он хорош. И если бы вы попробовали написать синтаксический парсер этого языка, то больше бы не докапывались до него. Я вообще считаю, что он во много просто гениален. Очень простой и при этом мощный.
По поводу модульности в C. Разве sudo apt-get install libevent не похоже на npm i libevent?
Язык Shell. Не стоит на нём писать что-то большое. Разбейте задачу на отдельные функции и сделайте их на подходящем для этого языке и только затем совместите их функционал в одном sh-сценарии. Это я пишу потому, что есть некоторые личности, которые пишут JSON парсеры/генераторы на Sh и потом жалуются.
Про printf вообще смешно. Если вы не понимаете как работает эта функция, то согласитесь, что проблема не в ней.
Ну и так далее...
И кстати, я не говорю, что unix идеальна. Очень много бардака. Особенно там, где разработку вело много народа. И на мой взгляд, историческое наследие в виндовс на много тяжелее и буквально жирнее.
Конфиги у нетривиального софта могут иметь еще и логику (если-то-иначе), и циклы, и много чего еще. Это не описать JSON. Теоретически годится XML, но XML — это ужас-ужас. Как вспомню XSLT.
Мне кажется, проблема высосана из пальца. Почти никогда не испытывал проблем с конфигами. Да, они часто очень разные, но так и программы разные, с разными требованиями. Никому не приходится работать с конфигами всех программ каждый день. Необходимый минимум легко запоминается по мере работы, в случае затруднений можно посмотреть man.
Например, я уже лет 5 или больше не трогал конфигурацию grub. Не было надобности. Если понадобится, разберусь с форматом конфига, и он мне еще 5-10 лет не понадобится.
У grub реально есть свой CLI. Так что всё логично. :)
Внедряя JSON везде вы усложняете жизнь простым программам. Для хранения разобранного дерева надо использовать динамическую память, хеш таблицы, списки и пр. Это типичный подход прикладника. Зафигачить всё с помощью толстых библиотек, лишь бы не думать. :) Без обид. Но именно прикладники заблуждаются про стоимость printf и strcmp.
Для большинства маленьких утилит как раз достаточно пробежаться по строчкам и выделяя ключи распихать значения по статическим переменным. И никаких лишних зависимостей и динамических структур.
Большие и жирные программы могут и в JSON хранить, если им так удобнее. Но ведь не хранят. Почему? Может простые форматы эффективнее для их решения?
Кто-то там сверху писал про строки. В C++ std::string это кромешный ад и обман. За как будто ясным API скрывается ужас реализации с колоссальным дублированием кода и потреблением ресурсов. Я в 90-ых годах фанател от C++ и думал, что ООП очень помогает эффективности. Но когда познакомился с реальностью был в ужасе. Люди не умеют пользоваться ООП.
Лично мне в C не хватает строгой типизации и объявления функций в функциях с доступом к локальным переменным. Но даже имеющийся С годен. Достаточно просто делать продуманные API.
И кстати, про C 2.0 согласен. Можно было бы сделать :) Просто чуточку выправить. Но как грузить модули динамически со статической типизацией без извратов?
В целом спор бесполезен пока мы не договоримся о целях и приоритетах. Кто-то пишет компактно и эффективно, а кто-то пишет без оглядки на ресурсы, но с как бы комфортом. Отсюда и вкусы разные.
Я про модули не понял. Он же по сути состоит из двух частей: объявления и непосредственно кода. Объявления подгружаются с помощью include ибо они не должны быть большими(у разумных людей). А код уже скомпилированный в виде архива/объектника/библиотеки.
В объявлениях могут быть макросы коие никак не представляются в коде. Т.е. заголовки модулей не могут обладать всей мощью include. Следовательно модуль придётся упростить до набора внешних функций, переменных или констант.
Где-то в исходнике модуля надо ввести аттрибут 'extern' из которого в неявном виде будет выделяться объявление(такой уже есть).
Текстовые include вы не хотите, но всё равно придётся вводить директиву подключения модуля. Что-то вроде #import <stdio>. Оно чем-то принципиально лучше #include?
Может, Вам будет интересно это:
Gustedt "Modular C"
Gregor "Modules"
Хотя я бы тоже хотел почитать про модули понятным языком и без Паскаля.
А как вы хотели генерировать общий precompiled header для разных проектов с разными настройками компиляции, разными инклюдами и прочим?
Если же все это у них — общее, то я не понимаю почему вы не смогли создать для них общий precompiled header.
Ну, если вспомнить Turbo Pascal… Там тоже заголовок модуля прекомпилирован. Но, как правильно замечено в следующем комментарии, шаблоны C++, некий аналог макросов, очень сложно прекомпилировать.
Но самой главное препятствие — препроцессор. Модули возможно ввести только когда отказаться от него, а это полная перестройка всех исходников. Это будет другой язык.
Просто я хочу чтобы этот формат был стандартизирован и унифицирован, и чтобы тогда уж ничего кроме «ключ-значение» в него вставлять было нельзя.
Внедряя JSON везде вы усложняете жизнь простым программам. Для хранения разобранного дерева надо использовать динамическую память, хеш таблицы, списки и пр. Это типичный подход прикладника. Зафигачить всё с помощью толстых библиотек, лишь бы не думать. :) Без обид. Но именно прикладники заблуждаются про стоимость printf и strcmp.
Минимальная библиотека для работы с JSON занимает не так уж и много места. А если вам так уж нужно эффективно читать файл, то читайте бинарный файл. Это быстрее текстового.
Ну или хотя бы придумайте единый формат под названием "таблица" для таких вот файлов как passwd и fstab. Чтоб не нужно было иметь для passwd один парсер, а для fstab — другой.
Чтоб не нужно было иметь для passwd один парсер, а для fstab — другой
В общем, хотите текстовые конфиги — пожалуйста, но они должны иметь единый, унифицированный и стандартизированный формат для всей ОС. «Ключ = Значение». Ну еще комментарии. Все, точка.
Нужно просто принять
И реально никто не сделал такого для C? Там ведь тоже можно сделать что-то вроде package.json и придумать общую схему для подсасывания зависимостей и сбора include папки из пакетов.
А потом приложения будут таскать всё с собой и весить под две-три сотни мегабайт, если не больше. Зато ясно и предсказуемо, ага.
Я для кого объяснял? Я в своей статье разрушил аргументы типичных фанатиков UNIX, а вы тут опять с ними лезете. Объясню по пунктам что ли.
Текстовые конфиги в большинстве своём имеют настолько примитивный формат, что парсятся на раз
У них у всех разные форматы. И многие используют свои правила эскейпинга специальных символов (тот же fstab). То есть просто в тупую парсить fstab регексами, read'ом, cut'ом нельзя, нужно учитывать эти правила эскейпинга. Иначе вылезут баги, вплоть до багов с безопасностью. Поэтому у них должен быть один формат. JSON, YAML, что угодно. Который парсится стандартными библиотеками с гарантированной правильной работой с эскейпингом. И это не говоря попросту о том, что тогда не надо будет для каждого файла писать свой парсер.
В итоге, для настройки системы достаточно текстового редактора и интеллекта!
Так тут я не спорю. Просто используем единый формат всех конфигов.
JSON и XML не годятся для человека. Они требуют сложного парсинга, трудно читаемы и их структуру легче поломать.
JSON и XML (особенно JSON) достаточно хорошо пишутся и читаются человеком. Они требуют написания всего одного парсера для каждого языка программирования. Да, JSON можно попортить, как и, скажем, passwd и fstab.
Для бинарных форматов вообще будут нужны специальные утилиты. И, если их форматы универсальны, так же требуют парсинга. В обратном случае хранимые бинарные структуры будут платформо-зависимы и требовать регулярного обновления при добавлении новых полей.
Б@#, добавьте новый столбец во fstab! Вы этим поломаете кучу скриптов. А если бы использовался JSON или некий универсальный JSON-подобный бинарный формат, то почти ничего бы не сломалось. Просто в JSON-хеше появилось бы новое поле.
Для критичных для производительности файлов, особенно если их будет править не только человек, но и машина, нужен бинарный формат, я уже объяснял в статье. Плюсы бинарного представления перевешивают минусы. Кто-нибудь здесь правил вручную passwd последние пару лет? passwd как пишется, так и читается обычно машиной. Так зачем ему тогда текстовое представление? Кому нужно подредактировать passwd, тот пускай подредактирует, используя специальные инструменты.
По поводу языка C тоже скажу. По сути это кроссплатформенный ассемблер. Он должен обеспечивать полный контроль над аппаратурой. Разве что он оффициально не подпускает к регистру состояния процессора со всякими там битами переноса, но во всём остальном он хорош. И если бы вы попробовали написать синтаксический парсер этого языка, то больше бы не докапывались до него. Я вообще считаю, что он во много просто гениален. Очень простой и при этом мощный.
Я для кого тут объяснял? Я не придираюсь к арифметике указателей, отсутствию сборщика мусора и т. д. Всё это так и должно быть, для того язык и задумывался. Но у C есть куча реальных недостатков. Которые теоретически можно исправить, оставив язык при этом "кроссплатформенным ассемблером". Ужасный препроцессор вместо нормальных гигиенических макросов, отсутствие даже опциональной проверки границ массива неким единым и стандартным способом, отсутствие нормальной работы со строками (последние два пункта приводят к постоянным проблемам с безопасностью), отсутствие удобных инструментов без legacy (мультиплатформенный менеджер пакетов, система сборки).
По поводу модульности в C. Разве sudo apt-get install libevent не похоже на npm i libevent?
Нет. Потому что npm работает на UNIX-подобных системах и Windows. А apt-get — только в системах, основанных на Debian. Хочется иметь стандартный популярный обкатанный менеджер пакетов C для большого числа ОС, как минимум UNIX и Windows.
Понятное дело, сами пакеты необязательно будут мультиплатформенны. Но некоторые из них, хотя бы даже curl — будут. И сам менеджер пакетов будет мультиплатформенным.
Ещё в C нет namespace'ов.
Язык Shell. Не стоит на нём писать что-то большое. Разбейте задачу на отдельные функции и сделайте их на подходящем для этого языке и только затем совместите их функционал в одном sh-сценарии. Это я пишу потому, что есть некоторые личности, которые пишут JSON парсеры/генераторы на Sh и потом жалуются.
А я с этим не спорю.
Про printf вообще смешно. Если вы не понимаете как работает эта функция, то согласитесь, что проблема не в ней.
Я с самого начала понимал, как она работает. И знал, что printf парсит строку формата в рантайме. Но я думал, что так и надо, что раз так сделано, значит, это занимает не так уж и много времени. Потому что писали какие-то умные дядьки. А потом (когда увидел тесты от H2O) понял, что это не так. Что printf, как и многое в C и UNIX — это тупо кем-то оставленный костыль. Ну вот этой моей находкой я и делюсь.
И кстати, я не говорю, что unix идеальна. Очень много бардака. Особенно там, где разработку вело много народа. И на мой взгляд, историческое наследие в виндовс на много тяжелее и буквально жирнее.
Возможно. Тут я тоже не спорю.
И я не предлагаю всё переделать в UNIX'е. Я просто хочу, чтобы люди кое-что про него знали.
Вообще язык C разрабатывался одновременно с UNIX, поэтому критикуя UNIX, нужно покритиковать и C тоже
Скажу лишь вот что. В C до сих пор не научились удобно работать со строками
И это не говоря об отсутствии простой, удобной и мультиплатформенной системы сборки <...> стандартного менеджера пакетов
void (*signal(int sig, void (*func)(int)))(int)
Статья написана наскоро, «полировать» дальше не хочу, скажите спасибо, что написал
Было бы лучше, если бы утилиты выдавали вывод в виде XML, JSON, некоего бинарного формата или ещё чего-нибудь.
Вы только представьте! Вот допустим, нужно удалить все файлы в текущей папке с размером, большим 1 килобайта. Да, я знаю, что такое надо делать find'ом. Но давайте предположим, что это нужно сделать непременно ls'ом. Как это сделать?
Я не закончил про UNIX shell. Рассмотрим ещё раз пример кода на shell, который я уже приводил: find foo -print0 | while IFS="" read -rd "" A; do touch — "$A"; done. Здесь в цикле вызывается touch (да, я знаю, что этот код можно переписать на xargs, причём так, чтобы touch вызывался только один раз; но давайте пока забьём на это, хорошо?).А почему не find foo -exec touch {} \;?
Код на любом другом языке программирования будет работать быстрее этого. Просто на момент появления UNIX shell он был одним из немногих языков, которые позволяют написать это действие в одну строчку.
Вы только представьте! Вот допустим, нужно удалить все файлы в текущей папке с размером, большим 1 килобайта. Да, я знаю, что такое надо делать find'ом. Но давайте предположим, что это нужно сделать непременно ls'ом. Как это сделать?
Я не закончил про UNIX shell. Рассмотрим ещё раз пример кода на shell, который я уже приводил: find foo -print0 | while IFS="" read -rd "" A; do touch — "$A"; done.
Более того, на любом языке можно написать код, который будет медленнее этого…
Начнём с того, что сравнивать C с Rust (Cargo) — это какое-то читерство :)
У авторов Rust/Cargo была возможность внимательно изучить все предыдущие подходы, взять из них всё самое лучшее и выкинуть всё плохое. Авторы C были первопроходцами, естественно они допускали ошибки.
Теперь к самой сути статьи.
Очевидно, что идеальная программа/система, написанная за бесконечное количество времени и денег никому не нужна.
Людям нужно нечто достаточно хорошее, способное решать задачи прямо сейчас.
Поэтому победил UNIX, несмотря на все его недостатки.
Поэтому никто не готов "ломать весь мир" и переписывать все программы, переходя на Plan 9 или что-нибудь ещё, проще вставить костыль в UNIX, чтобы оно работало прямо сейчас.
Что с этим делать? Ничего. Мир жесток, несправедлив и совсем не идеален. Нужно просто научиться жить с этим дальше. Научиться решать реальные задачи, обходя подводные камни.
А вообще, спасибо за статью, очень много интересных исторических и технических фактов. О многих из них я раньше не знал, но теперь почитаю про них подробнее.
Начнём с того, что сравнивать C с Rust (Cargo) — это какое-то читерство :)
У авторов Rust/Cargo была возможность внимательно изучить все предыдущие подходы, взять из них всё самое лучшее и выкинуть всё плохое. Авторы C были первопроходцами, естественно они допускали ошибки.
Ну да. Всё правильно. Просто есть на свете люди, которые этого не понимают. И которые считают Rust посягательством на святой неприкосновенный C. Вот для них и предназначена моя статья. И вообще со всем вашим комментом я согласен. :)
Что с этим делать? Ничего.
Почему ничего? Ломать костыли. Исправлять. Проблема лишь в том, что пока груз поддержки легаси не превышает выгод от его избавления. Что лучше — один раз поломать написанное плохо и написать лучше и потом все оставшееся время получать профит или и дальше продолжать жевать кактус, накапливая ненависть? Когда-то чаша переполнится и костыли сломают. Будут новые костыли, более прямые и долговечные :) Но мне кажется, многие этого не понимают и цепляются за старое. Думаю, именно их автор назвал фанатиками.
Вообще говоря, какие-то подвижки вроде начинаются уже. Тот же systemv. Есть какое-то понимание проблемы и это хорошо, кто бы что ни говорил.
Что лучше — один раз поломать написанное плохо и написать лучше и потом все оставшееся время получать профит или и дальше продолжать жевать кактус, накапливая ненависть?Всегда есть некий баланс — но он гораздо ниже, чем многим бы хотелось. В узких нишах можно позволить себе отбрасывать костыли лет через 5-10 (MacOS, к примру достаточно давно не поддерживает на MacOS Classic приложений, ни даже приложений для PowerPC!), в более широких — это занимает десятилетия (пример: MS-DOS 1.x использовала для работы с файлами FCB, а появившайся через 2 года MS DOS 2.x — уже прогрессивные handleы… ещё через 18 поддержка FCB в DOS приложениях была выпилена — в Windows XP).
Вообще, забавно. Автор на скорую руку сляпал пост, разжигающий священную войну, и ни разу не появился в комментариях. Судя по прошлым постам из профиля — похож на полупрофессионального тролля.
Поставил источники на многие факты в статье
Как минимум на C++ или D переписать не так уж и сложно. D так вообще бинарную совместимость обеспечит.
2 Incidence
Я в курсе, и всего то на 18 лет. Это к свежести вопроса про utf в консоле. Мне лично он там никогда актуален не был.
А в венде юникод появился?) Или надо руками ставить unicow.dll ?)
Тут написано нахрена: https://habrahabr.ru/post/276227/
Примерно половина доводов в статье как всегда — просто раздувание слона из мухи, или просто непонимание каких-то моментов реальности. Но остальная половина, конечно, является доводом в определённой степени. В общем, главное — не бросаться из крайности в крайность. UNIX писали обычные люди. И вполне логично, что у него есть и недостатки. Но некорректно говорить, что это полностью плохая идеология.
И это не говоря уж о том, что критичные файлы UNIX (такие как /etc/passwd), который читаются при каждом (!) вызове, скажем, ls -l, записаны в виде простого текста. И эти файлы надо заново читать и заново парсить при каждом вызове ls -l!
А кеширование данных на уровне файловой системы на что было сделано? Не раздувайте слона из мухи, это вообще не проблема.
Вообще, конкретные обстоятельства, возникшие во время разработки оригинальной UNIX, сильно оказали на неё влияние. Скажем, читал где-то, что команда cp названа именно так, а не copy, потому что UNIX разрабатывали с использованием терминалов, которые очень медленно выдавали буквы
Это является каким-то минусом UNIX идеологии? Вроде как в целом мне и самому удобнее писать cp, а не copy.
Терминал в UNIX — жуткое legacy
Хрен его знает, чего в этом плохого, но я лично с большим удовольствием пользуюсь энтим самым легаси терминалом, подключаясь к своим серверам по ssh, будучи в какой-нибудь маршрутке, через 3G соединение своего мобильного телефона, который расшаривает на мой ноут Wi-Fi. Короче, опять муху из слона раздуваете, господин автор поста.
UNIX shell хуже PHP!
Да вы запарили со своими загонами в сторону PHP. PHP успешно используется в гигантских проектах, постоянно развивается и имеет некоторые особенности, дающие повод на то, чтобы указывать его как более правильный выбор чем тот же хвалёный Ruby On Rails. Это тоже, наверное, тоже о чём-то говорит.
«А? Что? Lisp? Что за Lisp?» Интересно, да?
Извините, но если честно — не особо. Я бы вполне мог и PHP для подобной задачи использовать, благо он умеет подключаться к серверам по SSH и даже управлять файлами на удалённых серверах, если это необходимо.
Да, так можно. Но часто photoshop'ом или gimp'ом всё-таки лучше. Хоть это и большие, интегрированные программы
Опять перекос непонятно куда. Если речь идёт об одной картинке — да, гимпом и фотошопом удобнее. Когда речь идёт и миллионах картинок и их пакетной обработке — тогда и возникает вся польза идеологии UNIX.
#Add more colors if proper TERM was not exported
if [[ $TERM != *-256* ]] && [[ $TERM != screen* ]]; then
#Workaround for Konsole setting TERM=xterm by default (https://bugs.kde.org/show_bug.cgi?id=212145)
#konsole-256color ломает цвета для ls -l, т.к. dircolors такого не знает, можно вылечить задав непустой $COLORTERM,
#в vim ломается переход между вкладками по Ctrl-PgUP/PgDown
[ -n "$KONSOLE_PROFILE_NAME" ] && export TERM=xterm-256color
[ "$COLORTERM" = 'xfce4-terminal' ] && export TERM=xterm-256color
fi
Окей, конфиги кешируются. Но парсить их нужно всё равно каждый раз
Конфиги большими не бывают. Для современных систем, распарсить пару тысяч строк — это ведь вообще мелочь. Тем более, парсинг конфига делается либо при запуске приложения, либо при конкретном вызове команды для обновления конфига.
В общем, всё равно это не является причиной для довода против идеологии UNIX. Тем более это не является доводом в пользу того, что только из-за этого надо теперь брать и внедрять везде реестр. Тем более это не является доводом в пользу того, что система на подобии реестра решит эту проблему и не добавит никаких других проблем.
Я говорил про ls -l. Он читает конфиг каждый раз. Так что что-то по-любому нужно сделать: или поместить passwd в бинарный вид, в БД или в реестр, или фиксить ls, чтобы он по-другому работал. Ни то, ни другое в дефолтных поставках дистров gnu/linux, к сожалению, делать не собираются.
А аргументом в пользу реестра является та ситуация с ext4.
А аргументом в пользу реестра является та ситуация с ext4.
Это про момент с потерей гномьих конфигов при резком выключении системы?
На самом деле не аргумент. В такой ситуации реестр будет просто способом гарантированно в аналогичной ситуации потерять все настройки одним махом, в то время как при наличии множества файлов есть вероятность, что навернутся не все.
Ведь что есть реестр? А это всего лишь файл, который хранит все те же настройки неважно в каком виде. И при сбое, связанном с выключением в момент записи в этот файл, этот файл может исчезнуть точно так же, как и настройки в приведенном случае.
А спасти от такой проблемы может не реестр, а резервирование (возможно, многократное).
Если обратиться к опыту винды, то там как раз осуществляется резервирование реестра при помощи различных механизмов (рядом с оригиналом хранится копия реестра, плюс копии в "точках восстановления"). Если сбой не затрагивает все копии реестра, то какая-нибудь из них вполне может быть восстановлена в качестве рабочей (естественно, без гарантии сохранения самых последних правок).
Соответственно гномопользователю (или разработчикам гнома) дляпредотвращения случаев с потерей конфигов нужно было всего лишь озаботиться резервными копиями гномоконфигов и механизмом их быстрогого восстановления.
Доводы разработчика, безусловно, понятны, но они говорят скорее о неправильной работе гнома с текстовыми конфигами, нежели о необходимости использовать реестр.
В частности в приведенной цитате пишется про некорректно написанные приложения, которые слишком часто занимаются записью в большое количество файлов.
Как touch'нуть все файлы в папке foo
man find | grep execДочитал пока до этого места имхо — посыл всё плохо. Но сравнения с чем то ещё не проводится за редким исключением.
Ну, говорить что всё плохо но не говорить как надо, имхо всё равно что светить на солнце.
Движение есть, прогресса нет (с).
И про венду/qnx/bugu|freertos/systemi/plan9/*dos и слова не было. Если вы, кроме unix-like, posix-совместимых и windows ничего не видели, то это не значит, что кто-то фанатик чего-то.
CC ?= gcc
LD ?= ld
CFLAGS := -g -m64 -mno-red-zone -mno-mmx -mno-sse -mno-sse2 -ffreestanding \
-mcmodel=kernel -Wall -Wextra -Werror -pedantic -std=c99 \
-Wframe-larger-than=1024 -Wstack-usage=1024 \
-Wno-unknown-warning-option $(if $(DEBUG),-DDEBUG)
LFLAGS := -nostdlib -z max-page-size=0x1000
INC := ./inc
SRC := ./src
C_SOURCES := $(wildcard $(SRC)/*.c)
C_OBJECTS := $(C_SOURCES:.c=.o)
C_DEPS := $(C_SOURCES:.c=.d)
S_SOURCES := $(filter-out $(SRC)/entry.S, $(wildcard $(SRC)/*.S)) $(SRC)/entry.S
S_OBJECTS := $(S_SOURCES:.S=.o)
S_DEPS := $(S_SOURCES:.S=.d)
OBJ := $(C_OBJECTS) $(S_OBJECTS)
DEP := $(C_DEPS) $(S_DEPS)
all: kernel
kernel: $(OBJ) kernel.ld
$(LD) $(LFLAGS) -T kernel.ld -o $@ $(OBJ)
$(S_OBJECTS): %.o: %.S
$(CC) -D__ASM_FILE__ -I$(INC) -g -MMD -c $< -o $@
$(C_OBJECTS): %.o: %.c
$(CC) $(CFLAGS) -I$(INC) -g -MMD -c $< -o $@
$(SRC)/entry.S: gen_entries.py
python3 gen_entries.py > $@
-include $(DEP)
.PHONY: clean
clean:
rm -f kernel $(SRC)/entry.S $(OBJ) $(DEP)
Вообще-то, на чистом make даже компиляция одного cpp-файла с учетом его зависимостей превращается в приключение и обрастает костылями...
Костыли есть в любой сколь-нибудь сложной системе. Среди прочего это часто связано с необходимостью в разумные сроки соединить результат творчества большого количества народа.
Но говорить на основании этого о крахе "философии UNIX" как минимум весьма странно. Тем более, что в статье об этом ни слова.
Большая часть примеров рассказывает об общих для всех систем костылях. В частности все, что касается работы с файлами, содержащими в имени символы, имеющие в командном интерпретаторе специальное значение (одни пробел со слэшем доставляют "удовольствие" в любой системе). Соответственно непонятно, причем тут вообще "философия UNIX"?
И, кстати, о make,
Разве эта утилита является частью ОС? Разве она не работает на всех ОС абсолютно одинаково?
Разве на всех ОС не существует систем сборки, в которых этот make вообще не используется (и еще больше тех, где он используется только после запуска сборки, получая на вход файл, созданный вообще без участия пользователя)?
Потеря данных при сбое системы вообще общая для всех систем тема, связанная с особенностями работы абсолютно любых файловых систем. Разве что журналируемые могут спасти от фатального полного разрушения всей ФС. И реестр тут не поможет. Поможет резервная копия поврежденного файла, будь то файл реестра или конфиг в /etc,
Большая часть примеров рассказывает об общих для всех систем костылях. В частности все, что касается работы с файлами, содержащими в имени символы, имеющие в командном интерпретаторе специальное значение (одни пробел со слэшем доставляют "удовольствие" в любой системе). Соответственно непонятно, причем тут вообще "философия UNIX"?
Файлы со спецсимволами в именах ломают много скриптов. Это проблема в UNIX. Да, в других системах такая проблема может быть. И я нигде не говорил, что это имеет прямое отношение к "философии". Это один из недостатков. Это моя попытка указать на то, что shell неидеален для тех, кто вдруг этого не знает.
И, кстати, о make,
Разве эта утилита является частью ОС? Разве она не работает на всех ОС абсолютно одинаково?
make — один из столпов UNIX. Это одна из основных UNIX-программ. В Windows же make используется как "пришелец из мира никсов".
А дело в том, что printf, как и сама UNIX в целом, был придуман не для оптимизации времени, а для оптимизации памяти. printf каждый раз парсит в рантайме строку формата.
C# и его интерполяция строк...
Например, в D это может быть не так. Конкретно printf на эту тему не оптимизировался, так как разбор шаблона — капля в море по сравнению с выводом в консоль, но вот регулярки, например, могут быть скомпилированы на этапе компиляции:
import std.stdio;
import std.regex;
void main()
{
auto number = ctRegex!`\d+(?:\.\d+)?`;
writeln( "1.2,34.56".matchAll( number ) ); // [["1.2"], ["34.56"]]
}
Как это вы так? :) Фотошоп? :)
Бгг, распаковал под Windows 7 32 бита с помощью 7-zip 9.20. Работает. Про замену не спросил. Выглядит именно так, как на скриншоте в архиве (его можно посмотреть прямо в интернете, ничего для этого скачивать не надо). Есть оба слеша в именах файлов. Но это сделано с помощью специальной фичи оболочки Windows (т. е. Windows Explorer, ну или Windows Shell, короче говоря та оболочка, которая показывает вам всякие там "Мой компьютер" и "Панель управления", хотя таких папок на самом деле нет), которая позволяет показывать не те имена файлов, которые реально есть в файловой системе. Т. е. на самом деле эти файлы и папки называются по-нормальному, просто имена не те отображаются. Принцип тот же, из-за которого называются папки в C:\Users\User по-английски, а отображаются в проводнике по-русски
Итак, я не хочу сказать, что UNIX — плохая система. Просто обращаю ваше внимание на то, что у неё есть полно недостатков, как и у других систем. И «философию UNIX» я не отменяю, просто обращаю внимание, что она не абсолют. Мой текст обращён скорее к фанатикам UNIX и GNU/Linux. Провокационный тон просто чтобы привлечь ваше внимание.
у Linux есть недостатки. Но сравнивать бесплатно и платное ПО
Write programs that do one thing and do it well.
Write programs to work together.
Write programs to handle text streams, because that is a universal interface.
- В самом начале make был программой, которую один человек написал для себя и нескольких своих знакомых. Тогда он, недолго думая, сделал так, что командами воспринимаются строки, которые начинаются с Tab. Т. е. Tab воспринимался отлично от пробела, что крайне некрасиво и нетипично ни для UNIX, ни за его пределами. Он так сделал, потому что не думал, что make будет ещё кто-то использовать кроме этой небольшой группы. Потом появилась мысль, что make — хорошая вещь и неплохо бы включить его в стандартный комплект UNIX. И тогда чтобы не сломать уже написанные мейкфайлы, т. е. написанные вот этими вот десятью людьми, он не стал ничего менять. Ну вот так и живём… Из-за тех десятерых страдаем мы все.
Мы все страдали понемногу О чем-нибудь и как-нибудь, Так что незнаньем мануалов, к сожаленью, У нас немудрено блеснуть.
$ info make2.1 What a Rule Looks Like
==========================
A simple makefile consists of "rules" with the following shape:
TARGET ... : PREREQUISITES ...
RECIPE
...
...
A "recipe" is an action that 'make' carries out. A recipe may have
more than one command, either on the same line or each on its own line.
*Please note:* you need to put a tab character at the beginning of every
recipe line! This is an obscurity that catches the unwary. If you
prefer to prefix your recipes with a character other than tab, you can
set the '.RECIPEPREFIX' variable to an alternate character (*note
Special Variables::).
- Вообще, названия утилит UNIX — это отдельная история. Скажем, название grep идёт от командй g/re/p в текстовом редакторе ed. (Ну а cat — от concatenation, я надеюсь, это все и так знали. :) Ну и для кучи: vmlinuz — Linux with Virtual Memory support gZipped.)
…
- Когда Кена Томпсона, автора UNIX (вместе с Деннисом Ритчи) спросили, что бы он поменял в UNIX, он сказал, что назвал бы функцию creat (sic!) как create. UPD от 2017-02-12: источников полно, например: en.wikiquote.org/wiki/Ken_Thompson. No comments. Замечу, что позже этот же Кен Томпсон вместе с другими разработчиками оригинальной UNIX создал систему Plan 9, исправляющую многие недостатки UNIX. И в ней эта функция называется create. :) Он смог. :)
Статью надо переделать, убрав все провокационное, и оставив только конструктив
Цель статьи в том, чтобы покритиковать, ничего не предлагая. Я обращаю внимание на то, какой же всё-таки legacy этот UNIX. Чтобы не было больше вот этих горящих глаз "Ах, UNIX, UNIX!" А использовать его и дальше можно. Если кому-то нужны альтернативы, посмотрите Plan 9 и прочие новые ОС. Но и сам UNIX не плох. Он стабилен и популярен. А провокационный стиль нужен был, чтобы встормошить читателя.
Я не закончил про UNIX shell. Рассмотрим ещё раз пример кода на shell, который я уже приводил: find foo -print0 | while IFS="" read -rd "" A; do touch — "$A"; done. Здесь в цикле вызывается touch (да, я знаю, что этот код можно переписать на xargs, причём так, чтобы touch вызывался только один раз; но давайте пока забьём на это, хорошо?).
find foo -print0 | xargs -0 touch --В данном примере для демонстрации я использовал решение с пайпом и циклом. Можно было использовать решение с -exec или xargs, но это было бы не так эффектно
Поняли, фанатики, да? Ваш кумир отказался от своей же философии. Можете расходиться по домам.
Git написали за неделю на коленке. (Да, да, почитайте историю гита.) Далее, гит на самом деле очень тупо "лобовым" способом устроен внутри. Вон, почитайте: https://www.opennet.ru/base/dev/git_guts.txt.html. Там тупо считаются хеши от файлов, затем эти хеши складываются в текстовые (!) файлы (в этом я не совсем уверен), от них считаются ещё хеши, от них ещё хеши и т. д. А можно было как-нибудь умнее сделать. Чтоб папки были всё-таки бинарными объектами сразу. А не текстовыми файлами захешированными.
Ладно, я выдохся. В общем гит настолько прекрасен, что его покритиковать сложно. Если серьёзно, то гит прекрасен. В отличие от юникс, который реально плох :)
Ах да, в гите многие команды реализованы на б-гмерзком шеле :)
Чтоб папки были всё-таки бинарными объектами сразу.
Git игнорирует существование директорий как отдельного класса объектов. Вы не можете взять и добавить в репозиторий директорию без файлов.
UNIX – наихудшая операционная система, если не считать всех остальных.
(ц) почти Уинстон Черчилль
и эффективной замены пока что нет
Единственными аргументами могут быть параметры работы
1C и МС Офис и на Линуксах не пойдут)
С UNIX системами этого еще не произошло
Никогда не понимал за что ругают популярные системы/продукты? Мир не идеален и в нем нет ничего идеального, все может только стремиться. Пока Unix/Linux имеет столь огромое сообщество это доказывает, что дохрена людей считают ее лучшим выбором из существующих. Кто считает таковой Windows, кто-то MacOS. Люди сделали свой выбор в пользу той или иной системы по совокупности качеств и характеристик. Не нравиться конкретно Вам, ну не используйте. Вклад Unix и ее производных в развитие технологий неоспорим, если бы не она. Сейчас был бы совсем другой мир. Не все решения в ней идеальны, но если их перенимают другие системы это доказывает их целесообразность.
Но я скажу за автора — к сожалению, прямо сегодня можно найти сколько угодно восторженных статей типа «А вот есть такая замечательная фигня, как bash, щас я вам про нее расскажу...» — где unix way откровенно перехваливается неофитами. Это не помешает иногда компенсировать долей скепсиса.
Думаете было бы лучше, если бы система позволяла использовать в именах файлов спецсимволы, а для написания простой поисковой маски пришлось бы вместо простого "?.*" писать какое-то адское заклинание?
Ну, это же на самом деле проблема формата zip, а не винды и не линукса.

кто распакует в маздае, тот имеет право гнать на UNIX
Add-Type -Assembly System.IO.Compression.FileSystem
$zip = [IO.Compression.ZipFile]::OpenRead("R:\test.zip")
$zip.Entries | where {$_.Name -like '?.txt'} | foreach {[System.IO.Compression.ZipFileExtensions]::ExtractToFile($_, "R:\%3F.txt", $true)}
$zip.Dispose()
И вы утверждаете, что маздай эффективнее NIXов, в качестве файлового сервера?
А сколько NASов было выпущено и работает под виндой? Почему производители так не любят выньдовз (ну кроме Micro$oft конечно же), прямо заговор какой-то.
что работа по обработке и кодированию видеосигнала проделывается не центральным процессором НЕ вашего компьютера, а аппаратной частью в «тюнере антенном»! Это такой профессиональный термин, да? ))
Ну, поскольку существует WinPE, который умеет грузиться по сети (а значит. умеет работать вовсе без диска) — нет никаких непреодолимых препятствий чтобы проделать подобную удаленную переустановку системы.
Но, конечно же. это будет намного сложнее. В основном — из-за всяких лицензионных ограничений.
Достало, что хвалят UNIX way. Что считают UNIX красивым и ещё и других учат.
Абсолютно согласен. Именно из-за лютого ручного make, адского autotools или чудного cmake на C писать не особо комфортно. Все те же проблемы ассемблера, только теперь кроссплатформенные.
Лично для себя я пишу утилиты на node.js, а для production, учитывая специфику embedded, т.е. когда требуется быстродействие и компактность, пишу на си. И иной раз без подключения стандартной библиотеки. :)
В windows писать для консоли вообще не принято. Из-за чего приходится лепить окошки и тратить время на свистелки. Но окошки там красивее :)
Что программирование на «голом UNIX», с использованием C и Shell
В таком случае C рассматривать не стоит. Компилятор является не частью системы, а всего лишь дополнительной программой, которая устанавливается в систему.
А если мы рассматриваем С, то придется и про C++ вспомнить, и про Python, и даже про Fortran c Perl. А кое где в мире ...nix и Object Pascal встречается, и go, да и все "передовое и современное" тоже.
Но ещё и из-за всех этих quirks мейкфайлов, шела, языка C. Отсутствия удобных инструментов, систем сборки, менеджеров пакетов.
Ни разу не пришлось создавать руками make файл. А порой его даже физически на диске не создавалось. Альтернативные среды разработки разной удобности тоже имеются в изобилии от достаточно примитивных (вроде codeblocks), до универсальных (вроде Eсlipse)
Да ладно?.. И где вы этот "за щелчок" сделали?
perl -e '$i=0; for (<*.txt>) { do {$i++} while (-e "${i}.txt"); print `mv $_ ${i}.txt`;}'
Enough time has passed since the silly days of crazed Linux advocacy that I'm comfortable pointing out the three reasons Unix makes sense:
1. It works.
2. It's reliable.
3. It stays constant.
But don't--do not--ever, make the mistake of those benefits being a reason to use Unix as a basis for your technical or design aesthetic. Yes, there are some textbook cases where pipelining commands together is impressive, but that's a minor point. Yes, having a small tool for a specific job sometimes works, but it just as often doesn't.
Write programs that do one thing and do it well.
Write programs to work together.
Write programs to handle text streams, because that is a universal interface.
find -exec или xargs. Ну что вы хотите, наскоро написанная статья. Можно было привести примеры получше, просто мне не хотелось. Это не отменяет того, что в shell'е постоянно возникают проблемы со специальными символами. Которые нужно по-особому обходить. И вообще у shell'а полно quirks, которые нужно постоянно держать в голове. И он запускает новые программы на каждый чих.iTWire: Systemd seems to depart to a large extent from the original idea of simplicity that was a hallmark of UNIX systems. Would you agree? And is this a good or a bad thing?
Linus Torvalds: So I think many of the «original ideals» of UNIX are these days more of a mindset issue than necessarily reflecting reality of the situation.
There's still value in understanding the traditional UNIX «do one thing and do it well» model where many workflows can be done as a pipeline of simple tools each adding their own value, but let's face it, it's not how complex systems really work, and it's not how major applications have been working or been designed for a long time. It's a useful simplification, and it's still true at *some* level, but I think it's also clear that it doesn't really describe most of reality.
It might describe some particular case, though, and I do think it's a useful teaching tool. People obviously still do those traditional pipelines of processes and file descriptors that UNIX is perhaps associated with, but there's a *lot* of cases where you have big complex unified systems.
And systemd is in no way the piece that breaks with old UNIX legacy. Graphical applications seldom worked that way (there are certainly _echoes_ of it in things like «LyX», but I think it's the exception rather than the rule), and then there's obviously the traditional counter-example of GNU emacs, where it really was not about the «simple UNIX model», but a whole new big infrastructure thing. Like systemd.
Now, I'm still old-fashioned enough that I like my log-files in text, not binary, so I think sometimes systemd hasn't necessarily had the best of taste, but hey, details…
И он запускает новые программы на каждый чих.
Это не отменяет того, что в shell'е постоянно возникают проблемы со специальными символами.
Можно ли считать builtins отхождением от юникс-вея, кстати? Ну, что каждая программа делает одну задачу и делает её хорошо.
?!?!?! Эээ, а слабо самому почитать тот ман, на который вы ссылаетесь? touch — не builtin баша. Как минимум потому, что его нет упомянутом man builtins. Во всяком случае в моей версии баша (4.4-2 из дебиана).
А про специальные символы уже рассказано подробно в моей статье. Про эти 5 хаков, которые нужно запихнуть в цикл, чтобы он работал нормально со специальными символами. См. также UPD от 2017-02-18
Знаете, что я ещё скажу? Веб, node.js и javascript — это шаг назад.
Вот я щас сижу через веб интерфейс mail.ru и он ужасен. Я нажимаю "удалить письмо" и вынужден ждать, пока оно удалится прежде чем закрыть вкладку. И когда я в одной вкладке удалил письмо, в другой вкладке оно всё ещё видно во входящих.
В десктоп приложениях такой проблемы нет.
Не надо все приложения переносить в веб. Веб — для публикации инфы. :) Просто разрабатывать приложения в вебе дешевле и эффективнее с точки зрения бизнеса, чем для десктопа, вот всё и пихают в веб.
А на деле получаем, что эти веб приложения тормознутее, меньше интегрированы с ОС.
А уж инструменты, которыми пользуются веб разработчики — javascript, node.js — это такой бред. javascript имеет кучу костылей. node.js — это наскоро написанное гэ. Пользователи всех нормальных языков программирования и фреймворков, проверенных временем просто в шоке от такого гэ.
Почитайте историю node.js. Какие-то чуваки оказались в нужное время в нужном месте. Скрестили ежа с ужом. Сделали кашу из топора. Взяли libuv (ну или сами его написали, но это не так уж и много работы), добавили V8 и готово. Т. е. тупо взяли несколько технологий и соединили и готово. Типичный стартаперский подход. Написали, раскрутили, хайп, все дела. Proof of concept (PoC). И на этом PoC так и живём. Вместо нормальных продуманных технологий. Они просто перечеркнули многолетнюю историю действительно продуманных языков программирования и фреймворков, а их полно. Perl, python, haskell. И вместо этого пишем как можно быстрее как можно больше быдлокода и побыстрее сразу выкладываем в продакшн или в npm.
Я выговорился. Написал сюда. Решил новую статью не писать :)
И когда я в одной вкладке удалил письмо, в другой вкладке оно всё ещё видно во входящих.
В десктоп приложениях такой проблемы нет.
Да ладно? Тут на ru.SO регулярно появляются вопросы "я заполнил переменную на форме 1 — а на форме 2 она пустая ПОЧЕМУ?". Не уметь программировать можно на любом языке программирования :)
А javascript и node.js, в том числе, сформулированную вами проблему решают. "Шагом назад" оказался только веб, а javascript и node.js — это шаг обратно вперед.
Не уметь программировать можно на любом языке программирования :)
А мой опыт говорит обратное. Всевозможные веб-приложения взлетели в том числе и потому, что там многие вещи делаются проще.
там многие вещи делаются проще
Например, богатые возможности по управлению текстом. Лейауты, подстраивающиеся под размеры содержимого. Богатое редактирование текста. Кроссплатформенность. Ленивая подгрузка модулей. Крутейший отладочный инструментарий.
Лейауты, подстраивающиеся под размеры содержимого.
Кроссплатформенность.
Ленивая подгрузка модулей.
Крутейший отладочный инструментарий.
Может потому, что у JS с самого рождения было всё хорошо с юникодом в отличие от "крутых, правильно спроектированных языков"?
В обоих случаях будут нули, не выдумывайте.
'E̋'.length // 2 OLOLO
Тут проблема не столько в JS, сколько в юникоде, где один символ может образовываться несколькими кодовыми точками.
То есть вы считаете нормальным, что конкатенация двух односимвольных строк даст не двухсимвольную строку, а односимвольную, и разделить её обратно на две односимвольные уже не получится?
( "E"+"̋" ).length
Значит я ненормальный, раз для меня это выглядит противоестественным. Всё же length на мой взгляд должен выдавать число кодовых точек. То, что комбинация нескольких точек даёт на экране один символ, а некоторые — ни одного, — это особенности отображения. Учитывать их тоже иногда полезно, поэтому тут лучше было бы ввести отдельный метод "countOfVisibleCharacters".
Но касательно вашего примера, да, суррогатная пара фактически кодирует одну кодовую точку, но большинство реализаций JS хранит строки внутри в UCS2 кодировке, игнорирующую такие пары. Однако спецификация JS не ограничивает от использования UCS4 или UTF* кодировок.
Вот с чего начинался этот тред. Когда язык считает, что строка «Ö» — длины два, это значит у языка с юникодом все плохо, потому что это противоречит правилам работы с юникодом, предписываемым консорциумом.
Вас не затруднит процитировать это правило? Особенно интересно, какую длинну они предписывают возвращать для строк, целиком и полностью состоящих из непечатаемых символов.
. vintage, am-amotion-city, mayorovp
Давайте я что ли выскажусь по поводу этого вашего юникода.
Призываю всех участников этой дискуссии не путать между собой следующие два обстоятельства:
Первое обстоятельство является относительно естественным (и оно видно при работе с любыми юникодными кодировками, будь то UTF-8 или UTF-16), поэтому я считаю, что любой язык, претендующий на работу с юникодом, должен его учитывать, и должен уметь выдавать как количеcтво видимых символов, так и количество кодовых позиций в строке.
Второе обстоятельство имеет в себе исключительно исторические причины. И оно проявляется лишь при работе с UTF-16. Было бы здорово, если бы люди сразу придумали UTF-16, без предварительного придумывания UCS-2 (ну а лучше, чтобы вообще никогда не придумывали ни UTF-16, ни UCS-2, а использовали лишь UTF-8). Тогда проблемы под названием "одни программы не поддерживают суррогатные пары, а другие поддерживают" не было бы.
Поэтому я считаю, что любой язык должен abstract out, т. е. скрывать от программиста существование суррогатных пар, т. е. делать так, чтобы программист об их существовании вообще мог не думать. Для этого, разумеется, нужно считать суррогатную пару за одну кодовую позицию.
Так вот, любой язык, декларирующий возможность работы с юникодом (в том числе UTF-16), должен уметь:
Считать число пар байт в случае UTF-16 (т. е. нечто промежуточное между пунктами 2 и 3, иными словами количество кодовых позиций, при условии, что мы считаем их "втупую", без учёта того, что существуют суррогатные пары) не нужно, т. к. я не могу придумать задачу, где такое может понадобиться.
Какую именно из этих операций нужно назвать length — это вопрос вкуса. Суть в том, что все эти операции язык должен уметь. И документация должна предупреждать о том, какой length что делает. Она должна предупреждать, что, скажем, "вот это length возвращает число видимых символов, а потому конкатенация двух строк с length один может дать строку с length один"
. vintage
Может потому, что у JS с самого рождения было всё хорошо с юникодом в отличие от "крутых, правильно спроектированных языков"?
JS не поддерживает суррогатные пары (во всяком случае не поддерживает с рождения), так что не всё так хорошо. Т. е. он как раз не справляется с тем, чтобы скрыть от программиста существование суррогатных пар, он их предъявляет программисту, не объединяя их логически в одну кодовую позицию.
. mayorovp
не-юникодовые строк в языке быть не должно
Просто с массивами байт язык всё-таки должен уметь работать. Да и со строками в неюникодных кодировках, я считаю, тоже
У вас какое-то странное понимание того что нужно программисту от поддержки юникода. Любая проверка длины строки ущербна сама по себе, просто из-за своего наличия. И никакое следование спецификациям тут ничего не изменит.
А реально от поддержки юникода требуется следующее:
grep bar file > tmp; mv tmp file. Как быть? Если делать решение с циклом, то мы упираемся в те пять хаков, которые нужно сделать, чтобы не выстрелить себе в ногу. Результат будет таким, со всеми пятью хаками:find foo -print0 | while IFS="" read -rd "" A; do
grep -- bar "$A" > tmp
mv -- tmp "$A"
done
--. Но даже от этого хака я бы не советовал избавляться, т. к. постоянное использование -- даёт понять читающему: «Да, я подумал об этом». Это как условия Йоды.sh -c. Как будет выглядеть результат? Может быть, так?find foo -exec sh -c "grep -- bar '{}' > tmp; mv -- tmp '{}'" ';'
find foo -exec sh -c 'grep -- bar "$1" > tmp; mv -- tmp "$1"' dummy '{}' ';'
sh -c и опять нужно передавать аргументы через $1.find -delete -name '*~' вместо find -name '*~' -delete или что-то такое. Ну подумаешь, думал я, опции не в том порядке. Смысл же тот же. И find удалил всё. И снёс свои важные файлы. Потом восстановил из бекапа, так что всё ок. Это потом уже я понял, что -name имеет truth value true в случае, если файл соответствует маске. И если -name вернул true, то обработка опций продолжается.Синтетическую. :) Но подобные задачи возникали в реале, могу поискать в реальном коде, надо?
Вам именно пример, где нужно сделать find, и для каждого результата find'а выполнить больше одного действия?
Или пример на любую другую особенность shell, обозначенную в моей статье, не обязательно именно ту с find'ом и sh -c?
#!/bin/bash
# script.sh
filename="$1"
echo "Действие 1 над файлом $1"
echo "Действие 2 над файлом $1"
find . -type f -exec ./script.sh {} \;
#!/bin/bash
# script.sh
filename="$1"
echo "Действие 1 над файлом ${filename}"
echo "Действие 2 над файлом ${filename}"
Можно и так. Но тогда нужно ещё один скрипт создавать из-за запростецкой команды. В других языках программирования такое вообще почти не встречается, чтобы из-за какой-то ерунды нужно было новый файл с кодом создавать. Почти во всех языках можно всю огромную программу запихнуть в один файл.
Вообще, скажу ещё раз. Выполнение нескольких действий с файлом можно сделать разными способами. Цикл, -exec sh -c, xargs sh -c, отдельный скрипт. Суть в том, что самый лобовой спобов даёт сбой, нужно держать в голове разные особенности. И так в shell везде.
К shell применимы те же аргументы, которые приводят обычно против PHP. Мол, костыль на костыле, нужно всё время помнить то, помнить это, и всё это без всякой логики, везде кривость дизайна. И с shell то же самое. Ладно, окей, shell не до такой степени плох. Просто я пытаюсь в своей статье разубедить тех, кто считает, что якобы shell прекрасен. Я и сам так думал до определённого момента. Я чётко помню свою недавнюю реплику (несколько лет назад) в канал #linux на руснете: "sh прекрасен и отражает суть unix. Единственные проблемы sh в неинтуитивных названиях закрывающих ключевых слов (if — fi, for — done) и в том, что в POSIX sh не хватает фич bash"
UPD от 2017-02-18: ещё по поводу надуманных примеров на shell. Вы говорите, примеры надуманные, что можно сделать find -exec или xargs. Да, можно. Но как минимум сам факт того, что нужно постоянно держать в голове, что, мол, цикл нельзя и нужен -exec и xargs — это уже костыль. Проистекающий из принципа «всё есть текст», ну или из слишком тупой реализации этого принципа в UNIX shell.
Я вас наверное удивлю, но очень много где нужно "постоянно держать в голове, что можно а что нельзя". Например:
std::list (или LinkedList) доступ по индексу не сильно быстрый, а в vector добавление "тормозит"nil засунуть в NSArrayhashCode и equals зачем-то бывает нужно переопределять. Да еще и как попало написать нельзя. Я не спорю, что можно придумать задачу, которая тяжело решается используя unix shell. Особенно в интерактивном режиме (в смысле из интерактивного шелла). При чем более приближенных к реальности, чем 'положить в файл результат grep-а по нему же'. И да, таких задач очень много. Вы предложили изначально задачу с touch-ем, я показал решение в 1 элементарную строчку. shell идеально подошел для её решения.
Если задача становится слишком сложной для shell, то я просто возьму python/perl или что-нибудь еще. Вплоть до того что буду прям из кода на python вызывать command-line утилиты используя subprocess.check_output, если так проще/быстрей.
Я помню, как однажды жутко оплошался, не зная этих тонкостей. Я набрал find -delete -name '*~' вместо find -name '*~' -delete или что-то такое. Ну подумаешь, думал я, опции не в том порядке. Смысл же тот же. И find удалил всё. И снёс свои важные файлы.
А если кто-то случайно сделает cp old_file new_file вместо cp new_file old_file и начнет писать "подумаешь, опции не в том порядке", то виноват тоже будет shell? А если я, наконец, нож возьму не той стороной и вместо того чтобы колбасу отрезать, руку порежу?
Нужно было вместо этого сделать так, чтобы find только умел искать файлы. А всю остальную функциональность нужно вынести из него. Проверки на размер файла должны быть снаружи.
Эээ. А -type тоже оттуда уберем? И вообще, вас кто-то заставляет пользоваться "встроенной" проверкой на размер? Проверяйте снаружи, если так удобнее. Только для простых случаев кода так будет больше заметно. В этом же и всё удобство шелла, что часть задач легко решается в одну строку вроде find ~/tmp -mtime +5 -delete практически не задумываясь.
Чем вы предлагаете shell заменить? perl/python? Покажите решение с удалением всех файлов определенного размера и сравните количество кода.
Почему-то в списках aka std::list (или LinkedList) доступ по индексу не сильно быстрый, а в vector добавление "тормозит"
Это объяснимо
В C++ нельзя кидать исключение из деструктора
Это тоже объяснимо. Да, можно придумать язык, в котором исключения из деструктора кидать можно, но это уже нетривиально. Так что здесь действительно it's for design.
В Objective C нельзя nil засунуть в NSArray
В Java hashCode и equals зачем-то бывает нужно переопределять. Да еще и как попало написать нельзя.
Не знаю Objective C и Java.
В первых двух примерах речь идёт о вполне объяснимых, оправданных вещах. Чего нельзя сказать о моих претензиях к shell. У shell'а тупо недостатки, вызванные кривостью дизайна. Их могло бы не быть, но они есть.
Эээ. А -type тоже оттуда уберем?
Да. :) Потому что в shell уже есть свои методы проверки типа инода (test -f и прочие). А find дублирует эту функциональность. Во всяком случае так нужно сделать в некоей идеальной гипотетической замене shell'а.
Вообще, я не предлагаю исправить shell. Я просто объясняю, что можно теоретически представить себе нечто лучшее. Ну как у того ветерана программирования, "If you put it [UNIX] up on a pedestal as a thing of beauty, you lose all hope of breaking away from a sadly outdated programmer aesthetic". А в shell'е в его текущем виде, конечно, все эти -type у find'а сидят на месте.
Чем вы предлагаете shell заменить? perl/python? Покажите решение с удалением всех файлов определенного размера и сравните количество кода.
Нужно заменить на некий полноценный скриптовый язык (например, perl или python) и добавить в этот язык некие средства для быстрого выполнения типичных shell'овых задач, например, запуск команд и пайпов. В языки программирования же добавляют средства для удобного исполнения SQL-запросов? Чтоб невозможно было случайно не заэскейпить SQL-запрос и получить SQL-инъекцию? Вот точно так же нужно в perl или python добавить специальные средства для удобного запуска команд, пайпов и прочего. Чтобы shell был вообще не нужен.
Вообще, возможно, PowerShell как раз именно то, что и нужно. Судя по тому, что о нём пишут в инете, это как раз оболочка, лишённая многих обозначенных мной недостатков shell'а, да ещё и являющаяся полноценным языком программирования.
А если кто-то случайно сделаетcp old_file new_fileвместоcp new_file old_fileи начнет писать "подумаешь, опции не в том порядке", то виноват тоже будет shell?
Этот пример некорректен. Опции без дефиса в начале не зря называются позиционными. Опции с дефисом таковыми не являются (во всяком случае, это такое соглашение, которого придерживаются практически все программы. Можно конечно плевать на эти соглашения, что find и делает, но глупо при этом возмущаться тем, что кто-то считает это неочевидным поведением. Оно таковым и является).
info sed | grep 'delete'Выбирая не самый изящный способ, конечно же, получается не самый изящный результат.
Я не считаю себя большим специалистом по unix[-like] shell однако, большинство практических задач находят достаточно простое и изящное решение даже в моих неумелых руках. Особенно при анализе слабо структурированных данных.
Сама концепция всё есть текст не идеальна, но, хороша для своего класса задач: выборка по неструктурированным/слабо структурированным данным. Для итерации по более структурированным данным, несомненно нужны более точные инструменты, для fs таким является find.
Концепция всё есть объект, тоже имеет право на жизнь, однако, требует сильной регулирующей организации а так же стандартизации. Учитывая период, который понадобился, что бы стандартизировать такой простой язык как C, сложно представить, сколько потребовалось бы на разработку стандарта такого уровня даже сейчас(далеко ходить не надо, достаточно взглянуть на python, который насколько я знаю, до сих пор не стандартизирован). А кому-то нужно (было и есть) ехать а не шашечки...
авторы UNIX'а любили создавать по языку на каждый чих
Собственно суть unix-way, dsl/утилита для каждой отдельной задачи, иначе, всё можно было бы на перфокартах до сих пор в пакетном режиме шедулить:)
Кстати, для примера, есть ещё концепция всё есть запись в БД, используемая в systemi. И она накладывает определённый уровень ограничений — например максимальная вложенность файловой системы есть 3, так же как и даёт определённый ряд преимуществ.
echo вроде как предназначен, чтобы печатать на экран строки. Вот только использовать его для этой цели, если строчка чуть сложнее, чем «Hello, world!», нельзя.
echo "Hello, world!". Вот несколько абзацев текста, объясняющих суть проблемы и пути обхода. В новых bash такого нет, на моей системе не воспроизводится.-⟧, этот случай нужно учитывать отдельно. К счастью, в примерах выше это не проявляется, т. к. путь всё равно начинается с foo>Как touch'нуть все файлы в папке foo (и во вложенных)?
find foo/ -name "*" -exec touch {} \;
От это Вы не быстрый… Кроме того, ответ не совсем верный и не очень эффективный:
команда touch будет выполняться не только для файлов но и каталогов
параметр -name "*" ничего не делает
запуск процесса это долго и дорого, намного эффективнее запускать touch один раз для группы файлов чем один раз на каждый файл


UNIX-подобные системы содержат кучу костылей. Крах «философии UNIX»