
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
1. Kotlin более проприетарный....
Не обязательно даже покупать. Вполне может случиться история как у Mozilla с Rust. Причем Mozilla, как я понимаю, изначально прикладывала усилия, чтобы создать здоровое сообщество вокруг языка, и по факту он смог продолжить самостоятельное плавание.
Как с этим у JB я не знаю, они сами говорят, что на данный момент над котлином работают более 100 штатных сотрудников компании. Звучит как довольно много, и непонятно, сможет ли язык развиваться, если этот ресурс вдруг иссякнет?
История то пока как раз хорошо развивается.
Вы возможно не в курсе, но теперь разработка языка финансируется из Rust Foundation, что то есть Rust теперь не "ничей", а "общий". Разница для некоторых может ускользать, но она существенная – сейчас в развитии Rust заинтересовано множество компаний и людей, а не только одна Mozilla.
Бинарные блобы в драйверах для Линукса тоже можно дизассемблировать, но это не делает такие драйвера open source в исконном смысле этого слова. Open source — это то, что любой может форкнуть и переписать под себя. Хранение ключевого кода компилятора в обфусцированном виде этому явно не способствует.
Про @Metadata можно прочитать в доке например https://kotlinlang.org/api/latest/jvm/stdlib/kotlin/-metadata/, а сами данные в протобафе и лежат в репозитории котлина https://github.com/JetBrains/kotlin/blob/master/core/metadata/src/metadata.proto. Для любого кому это интересно – не сложно найти это (я нашел прямо в интерфейсе гитхаба). Ну и конечно чтобы понимать это нужно понимать компилятор :) Интересно как много джава разработчиков умеет в сорцы javac)
Похоже, это никакой не "проприетарный код" в компиляторе, а просто способ для компилятора дописать дополнительную инфу в жестко заданном формате .class-файлов, который, естественно был заточен только под javac.
Компилятор Scala тоже пишет достаточно много метаинфы в .class-файлы. С этим можно огрести, если например использовать обфускаторы, работающие на уровне байткода. Но ничего криминального и проприетарного в метаинфе нет.
Нативная поддержка null, которая греет душу любого котлиниста, легко заменяется в Java на обёртку из
Optional.ofNullable
a) Вместо Optional всегда может прийти null
б) Optional никак не избавляет от проверок на null. Просто вместо if(it!=null)по всему коду будет if(optional.isPresent())
в) Опять же, таскать повсюду эту обёртку. Вместо `(arg: MyClass)` посвюду будут `(arg: Optional<MyClass>`. А джава и так не отличается лаконичностью.
г) Ну и самое главное. В котлине null safety проверяется на этапе компиляции, а не в рантайме, что, какбы, значительно интереснее
Пара корректировок:
вместо if(it!=null)по всему коду будет if(optional.isPresent())
Только по коду, который писали неумеющие в map, flatMap и иже с ними.
В котлине null safety проверяется на этапе компиляции, а не в рантайме
В джаве Optional это и есть способ обеспечения null safety на этапе компиляции. В рантайм это пролезает только в паталогических случаях, вроде Optional.get() или передачи null вместо Optional, но с такими случаями до какой-то степени можно бороться линтерами.
Только по коду, который писали неумеющие в map, flatMap и иже с ними.
В Котлин можно написать val notNullValue = calculateNullableValue() ?: return. Как вам тут поможет map и flatMap?
Мы обсуждали Optional в джаве, про котлин я ничего не говорил. Но если вы спрашиваете, как в аналогичном вашему кейсе в джаве обойтись без if(!optional.isPresent()) return, то очень просто:
void myFunc() {
...
optional.ifPresent(x -> ...);
}Конечно, если в целом окружающий код императивный, то лучше сделать if и return/break. Но если это какие-то преобразования на стримах, например, мой вариант будет более уместен.
Конечно, если в целом окружающий код императивный, то лучше сделать if и return/break.
Ну то есть вы понимаете, что вопрос не в умении или не умении map/flatMap, а в том, какая у нас вообще задача и какой код вокруг? Просто вы так написали, будто готовы уволить любого, кто isPresent() в коде напишет.
ifPresent — это уныло. Мы можем находиться во вложенном if/while/for, тогда это не поможет. Если же у нас несколько проверок на null подряд, то будет opt1.ifPresent(x -> opt2.ifPresent(y -> opt3.ifPresent( -> {...}))). Ну и, конечно, замена if(opt.isPresent()) на opt.ifPresent() не делает код лучше в 99% случаев. Он не становится более функциональным, менее зависимым от сайд-эффектов, при этом его становится сложнее отлаживать в пошаговом отладчике, удлиняются стектрейсы и т. д.
Я вообще делаю обычно так:
V v = computeOptional().orElse(null);
if (v != null) {
... используем v
}Некоторые приходят в ужас, но это самое удобное, что можно делать с optional.
Просто вы так написали, будто готовы уволить любого, кто isPresent() в коде напишет.
Я отвечал на "Optional никак не избавляет от проверок на null", что по факту не так. Использовать или нет — это воспрос стиля, принятого на конкретном проекте.
opt1.ifPresent(x -> opt2.ifPresent(y -> opt3.ifPresent( -> {...})))
Ну такой кейс во всей своей жести и на if'ах будет выглядеть неочень, особенно если есть else-часть.
Он не становится более функциональным, менее зависимым от сайд-эффектов, при этом его становится сложнее отлаживать в пошаговом отладчике, удлиняются стектрейсы и т. д.
Ну да, ifPresent — это для сайд-эффектов как раз и сделано. И да, есть плюсы и минусы. Но все-таки он вполне избавляет от проверок на null, о чем собственно и был изначальный тезис.
На ифах будет плоская структура:
X x = calcX();
if (x == null) return;
Y y = calcY(x);
if (y == null) return;
Z z = calcZ(y);
if (z == null) return;
// пользуемся x, y, z на здоровье.Optional не решает проблему с null. Её лучше решают nullability-аннотации и в целом массовый отказ от null (non-null by default). Но, конечно, в Котлине это сделано красивее и удобнее.
Optional не решает проблему с null. Её лучше решают nullability-аннотации
Непонятно, почему аннотации лучше. С использованием nullable-аннотаций, на мой взгляд, есть несколько проблем. Процитирую свой старый коментарий:
Для локальных переменных аннотации не нужны, любая нормальная IDE и без них справится. А средство композиции есть. Называется if. Насчёт инициализации с Optional тоже бывает, что поле может иметь значение, может не иметь, но инициализировать его надо лениво. Как будем выкручиваться? Optional<Optional<X>>?
Неициализированные поля, по-моему, в целом проблема дизайна, потому что всё подобное (поля) стоит делать final, инициализируя при создании объекта. Экзотику с не очень удачным DI, вроде оного в JFX, стоит рассматривать, скорее, как неудачное решение.
Для локальных переменных они, как раз, не нужны, потому что там nullability однозначно выводится.
Тут, увы, да, но в пределах API, скорее, nullа будут избегать (снова же, при удачном дизайне). Классический пример, пустая коллекция лучше nullовой.
Неициализированные поля, по-моему, в целом проблема дизайна, потому что всё подобное (поля) стоит делать final, инициализируя при создании объекта.
Ну почему же? Всё тот же Spring умеет в инициализацию через конструктор, либо, что ещё более приятно, static factory method. Единственное, что, по-моему, может мешать этому — циклические зависимости, но, это как раз чаще признак того, что что-то не так.
Неициализированные поля, по-моему, в целом проблема дизайна
В целом согласен, но иногда бывает нужно ленивую инициализацию. А если отойти от Optional и просто поговорить о final-полях в джава, то с этим до сих пор довольно много проблем. Тот же хибер, который совсем не экзотика, форсит делать изменяемые поля. Надеюсь, новые record'ы, который immutable by design, улучшат положение дел, но врядли это произойдет быстро.
Для локальных переменных они, как раз, не нужны, потому что там nullability однозначно выводится.
А кем выводится? Я вот за то, чтобы выводилось компилятором. Optional для этого и сделан как раз.
Тут, увы, да, но в пределах API, скорее, nullа будут избегать (снова же, при удачном дизайне).
Возьмем например REST API. Насколько я знаю, при маппинге необязательных полей из Java в JSON и обратно, у вас два варианта — либо nullable, либо Optional. Как можно избежать null, если не использовать Optional?
В параметрах передавать как раз таки антипаттерн.
Возвращать как раз хорошо. Принимать неправильно, да.
г) Ну и самое главное. В котлине null safety проверяется на этапе компиляции, а не в рантайме, что, какбы, значительно интереснее
Если рядом нет Java-кода.
На андроиде он обычно есть (старый код проекта или системный код андроида)
Какая то мелкая ошибка и креш с xxx must not be null. (xxx — объявлен в Java-коде)
И никаких вообще предупреждений компилятора.
Недавно пришлось править баг на эту тему. Dto-объект объявлен на java. одно из полей инициализируется вручную а не десериализатором (по историческим причинам, альтернатива — целиком этот модуль переписать, что в планах). вот только все забыли что у приложения есть (и используется иногда на проде) еще один legacy режим работы. в legacy-режими инициализации поля нет ни десериализатором ни вручную и при попытке обратится получатся xxx must not be null.
COBOL вполне себе успешно используется в банковском софте) Но мне тоже кажется, что автор прав и Scala не блещет какими-то успехами в последнее время.
На hh:
COBOL - 0 вакансий
Scala - 260 вакансий
Kotlin - 994 вакансии
Java - 4060 вакансиий
Так что COBOL скорее мертв, чем жив. Scala нашла свою узкую нишу. Kotlin до Java ещё далеко...
Да они и не откликаются на объявления. Google "Cobol cowboys")
Когда работал в Сбере ни разу не слышал, что ищут программиста Cobol (искали C, C++, Scala, JS, Python и больше всего искали Java) - хотя там тонны легаси. Но постепенно легаси заменяются на современные технологии....
Обычно разрабы на таких языках, как Cobol пишут десятилетиями и держатся за своё место или их индивидуально хантят.
Ваш текст навёл меня на мысль, что надо бы все же собраться с духом и изучить Scala. Коль скоро Скала уходит в забвение, скоро разработчиков на ней не останется, и тогда фин. сектор будет предлагать горы золотых пиастров тому, кто возьмётся поддерживать их легаси код, написанный на Скалке.
Тогда уж лучше всё же кобол
К тому времени все уже на Rust перепишут )
Помню изучал Scala, написал веб сервер, для чтения книг. Изучил довольно таки хорошо примерно за месяц. А далее появился go и переписал сайт на него и тоже хорошо изучил. В итоге остался на го и уже забыл синтаксис скала
Не представляю человека с улицы, который какое-нибудь зио и котоэффекты без подготовки освоит за полтора месяца. Особенно учитывая, что у всех работа/учеба, и 1.5 месяца это не фуллтайм изучение япа обычно.
Понятно, что шутка, но все же за раст как раз в плане мощности системы типов душа болит. Специализация, гаты, конст генерики — всё прячется за min_min_min гейтами и практически не едет. Это грустненько.
Тогда как в скале б0льшая часть этого давно есть.
Согласен, наверное это самое большое разочарование для программиста на Rust: язык сначала воодушевляет, а потом оказывается, что то — нельзя, это — нельзя… И возникает уныние.
Я прошел этот этап с пониманием того, что Rust — это не состояние, а процесс. Язык никогда не будет соответствовать своему идеалу, он все время будет как-бы недоработан, и это нормально. В Rust заметно противоречивое балансирование между красотой/стройностью и практичностью. Я принял это и вижу в таком подходе даже преимущества. Идеал виден, он осязаем, и язык развивается в его сторону, хоть и не так быстро. Настоящие проблемы возникнут у него если развитие остановится.
Вообще то пробовал писать на scala но совсем недолго, буквально пару дней и отложил на неопределенное время.
У меня есть идея, возможно нелепая, но тем не менее, мне всерьез кажется, что скала будет хороша на поприще 2д геймдева (которым я по-немногу балуюсь)
И я пробовал скалу именно на этом поприще. Сваял для пробы пера тетрис на связке scala + libgdx. Ну что могу сказать. У меня все время было ощущение, что мне хочется писать на скале именно как на джаве в ООП парадигме, и мне приходилось все время делать насилие над собой, чтобы придерживаться чистого ФП стиля. В итоге получилось обойтись почти без ооп, кроме тех мест, где надо было непосредственно с libgdx взаимодействовать, но вот само ощущение, что все время хотелось забить на ФП, и начать писать как на джаве, оно удивило. Ведь я пробовал писать рогалик в псевдографике в чистом ФП стиле на хаскеле и в принципе мне нравилось. По ООП совсем не скучал, наоборот было ощущение, что вот как клёво, никаких тебе объектов, которые вызывают методы друг друга хаотическим образом, как здорово, что нет этой путаницы, когда все зависит от всего.
Почему же на скале меня потянуло в ООП? Возможно такое случилось потому, что я очень плохо знаю скалу, и мне над каждым действием приходилось подолгу мучаться, чтобы понять как надо сделать. А писать в духе джавы, даже с самыми минимальными знаниями скалы было несложно - плодишь себе объекты с методами, которые вызывают друг друга и не паришься.
Я не думаю что она куда-то уходит: сидит в своей нише и сидит. Изучить её в любом случае доброе дело — система типов там куда лучше чем у мейнстрима.
У меня есть гипотеза, что Котлин создан не чтобы продавать IDEA, а чтобы разрабатывать IDEA. У JetBrains, я думаю, одна из самых развесистых Java-кодбаз в мире. Мало кто решается повторять их подвиг, предпочитают Electron. И когда несколько лет подряд 8 часов в день 5 раз в неделю пишешь Foo<bar> foo = new Foo<bar>, то в какой-то момент мысль о том "вот бы была такая Джава, как Джава, только лучше, и можно было бы в одном проекте их использовать" начинает преследовать.
Сколько бы плагинов в vscode не ставил - он всегда хуже чем web/phpstorm из коробки, да и работать начинает медленней, например go to definition срабатывает через пару секунд.
о том, что между ними нет разницы пишут только фанаты редакторов, которые не освоили нормальную ide
о том, что между ними нет разницы пишут только фанаты редакторов, которые не освоили нормальную ide
Ну у меня есть idea, для джавы ее использую, т.е. вроде бы по вашей класификации IDE освоил. А вот для JS/TS использую vscode и считаю его более удобным чем webstorm.
Вот этого нет?
Ну основное отличие — интегрированность. Обычно один плагин в умном блокноте никак не взаимодействует с другим. В той же идее есть некий протокол взаимодействия, что ли. Например, когда ты можешь в java-коде вставить jpql-строку. И она не просто подстветится в соответствии с синтаксисом, но и будут работать автодополнения. А если настроены datasource, то оно ещё и с реальными таблицами в базе интегрируется.
То есть сотрудники Jetbrains. Все минусуют…
Везде заговор!
совсем не умеют признавать свои ошибки и баги в их продуктах
Я умею. Дофига багов, вообще глюкавище полное иногда релизим :( А кто не умеет? Можно более конкретный пример?
но искренно верят в свою исключительность и что их IDE одни из лучших
Так и есть. Наши IDE одни из лучших. Это показывают многие опросы и исследования, а также сам факт того, что IDE успешно продаются и наблюдается стабильный рост продаж даже в условиях когда гораздо более толстые конкуренты выкидывают на рынок бесплатные решения. Никакой слепой веры, голимые факты.
Самое главное они недостаточно понимают специфику работы конечных пользователей их IDE, и какие задачи они решают, будь-то живут в своей вселенной Jetbrains…
У наших IDE порядка 10 миллионов пользователей, большинство платных. Они все ошибаются? Пали жертвой агрессивного маркетинга? А может такое случиться, что как раз ваши потребности слишком специфичны и не укладываются в сценарии, которые нужны большинству (говоря русским языком, "пользователь хочет странного")?
У наших IDE порядка 10 миллионов пользователей, большинство платных. Они все ошибаются? Пали жертвой агрессивного маркетинга? А может такое случиться, что как раз ваши потребности слишком специфичны и не укладываются в сценарии, которые нужны большинству (говоря русским языком, «пользователь хочет странного»)?
Кто-то выше утверждал, что Идея идеальный инструмент? Была бы она идеальна, мы бы без работы остались :-)
Это случается потому, что для джавы Идея — лучше чем остальное (там совсем все плохо), а не потому, что Идея прямо идеальный инструмент.
Применимо для чего угодно. Ничего идеального не существует, а сама идеальность меняется со временем.
Я так же пользуюсь райдером вместо студии и Clion вместо VSCode для раста. А ещё датагрипом вместо прости господи pgAdmin. Ещё эпизодически есть dotPeek/dotMemory/… и некоторые другеи продукты.
В итоге оказывается, что одна ультимейт подписка покрывает все мои потребности в написании лоу-левел кода, круд-кода, прототип-кода на жс или питоне, и даже sql-кода. Не смог найти только плагин для Idris чтобы заработал, пришлось ставить вскод. Ну и текстовые файлики тяжко открывать, получается что-то в таком духе

Подводя итог: у нас в компании куплены и VS и Rider лицензии. Изначально все сидели на студии, потом райдеры купили. Так вот за пару лет не осталось ни одного разраба на студии, включая меня.
Всех подкупили, Не иначе.
говоря русским языком, "пользователь хочет странного"
Я хочу поддержки, обучающих материалов и документации на русском языке.
Я хочу странного?
Скорее странно (мягко говоря) поведение JetBrains:
1) маскируются под чехов, на вопросы, заданные на русском языке, отвечают на плохом английском
...
N) Плачутся что их не внесли в реестр "отечественного" ПО
А вы много знаете продуктов мирового уровня, где есть поддержка и документация на русском? Мне на ум приходит MS Windows и некоторые сервисы Google. И то, и другое предназначено для широких народных масс.
Кстати, можно ссылку, где JetBrains плачется по поводу реестра? Ну потому что они очевидно не "отечественное" ПО.
А вы много знаете продуктов мирового уровня, где есть поддержка и документация на русском?
Кстати, можно ссылку, где JetBrains плачется по поводу реестра?
можно ссылку, где JetBrains плачется по поводу реестра?
— Он хороший, нам нравится. Зачем с ним что-то специальное делать? Я думаю, что продуктовые российские компании к нам так или иначе все приходят, мы их знаем, вы их знаете. Можно назвать имена, но это ничего не расскажет дополнительного. Есть такой специальный сектор, как государственные компании или просто государственные структуры, вот с ними можно было бы как-то специально работать, но у нас тут случился казус, и теперь им нельзя покупать наш софт!
— Для них мы не российская компания, потому что интеллектуальная собственность принадлежит чешской компании. У нас так устроен бизнес, что чешская компания заказывает разработку российской, российская делает на заказ за денежку, интеллектуальная собственность остаётся на балансе у чешской. Когда вы покупаете что-то, вы покупаете это у чешской компании. А [для продаж госкомпаниям] нужно быть в специальном реестре. И если в этом реестре есть хоть что-нибудь, отдалённо напоминающее конкурента по названию или по рубрике, то вы не можете купить зарубежный продукт, вы должны купить российский.
— Фактически нет, а если почитать реестр — то есть.
— Ты перечисляешь реальные конкурентные альтернативы, а есть бумажные конкурентные альтернативы.
— Ну, нас это не особо печалит, потому что с точки зрения денег, там их и не было. Нас печалит, что пользователи, которые хотели бы что-то купить у нас, не могут этого сделать, пишут нам «давайте вы внесётесь в этот список, Касперский же внёсся каким-то образом». А мы не можем им помочь. Обидно.
Я хочу поддержки, обучающих материалов и документации на русском языке.
Я хочу странного?
Если коротко, то — да. Я обычно хочу обратного — чтобы все на английском было. Доходит до смешного: например, постгря ошибку авторизации всегда отдает в серверной кодировки, не важно в какой вы там просили её ответить. В итоге рождаются такие смешные костылики: https://github.com/zemian/pgjdbc/commit/bd6de1b360c6a72b5513597813bef3773835e84e
А раньше когда я с MSSQL работал плотно и с виндовыми десктоп приложениями я регулярно пользовался вот этим сайтиком и проклинал создателей локализованных ошибок.
Так что да — странного.
Как вы перешли от
1) маскируются под чехов, на вопросы, заданные на русском языке, отвечают на плохом английском
к
Я говорю о том, что когда в JetBrains русские для русских пишут документацию на плохом английском — это #шизофрения
Если на русский вопрос ответ на английском — то да, это странно. Если язык документации, то лучше английский, пусть даже ломаный, т.к. так больше охват. Ну и на качество английского как правило ругаются ненативные пользователи, как бы это парадоксально не звучало.
Как вы перешли от
1) маскируются под чехов, на вопросы, заданные на русском языке, отвечают на плохом английском
к
Я говорю о том, что когда в JetBrains русские для русских пишут документацию на плохом английском — это #шизофрения
у нас тут случился казус...
русские для русских пишут документацию на плохом английском — это #шизофрения
А потом прочитал интервью их CEO(?) в котором он пожаловался, что «не может» торговать своим ПО в РФ.
Сначала я (потенциальный покупатель)
#шизофрения
В любом случае, придется писать документацию на английском, возможно нанимая англоязычного (не знающего русский) специалиста. Писать дополнительно документацию на русском — значит придется её же спровождать и делать все изменения в двух местах.
Это увеличит стоимость создания документации почти в 2 раза даже если её пишет изначально русскоязычный сотрудник.
2) мне человек с русским Ф.И.О. ответил на английском.
Вы не поверите, но человек с русским Ф.И.О. может не иметь русский как родной (коллеги с Украины, Казакстана и те чьи родители давно иммигрировали из СССР передают вам привет),
А ещё, даже если очень хочется написать что-то на русском, но официально, а не на IT-сленге, то порой можно голову себе сломать, пытаясь понять, как это должно звучать на русском. В лучшем случае поможет гуглёж и вдумчивое чтение перевода IT статей. Понятное дело никто по доброте душевной от лица компании не будет эти заниматься.
Но страждующие увидят и в этом русофобию. Это как радикальные SJW, но в отношении своего этноса. Так и ищут чем бы ещё оскорбиться :) Полезный навык наверное.
то порой можно голову себе сломать, пытаясь понять, как это должно звучать на русском
Давно это было?
Если надо ЕЩЕ примеров на тему "не того" языка -:)
то можно придраться к тому что Kotlin in Action / Kotlin в действии изначально написана на английском хотя казалось см хотя бы тот факт что авторы вычитывали текст после переводчика на русский (что не скрывается — https://habr.com/ru/company/JetBrains/blog/339400/ )
Т.е. имели место аж два лишних (стоящих денег, усилий, снижающих качество коммуникации) перевода на ненужный в данном случае язык.
Кстати вот не факт что перевод — лишний, мне (с родным русским) не раз уже встречалось что я не знаю как что-то сказать на русском, ну вот просто не знаю перевода термина, или что хуже — знаю что есть несколько переводов, и часть из них — явно кривые.
Кстати вот не факт что перевод — лишний, мне (с родным русским) не раз уже встречалось что я не знаю как что-то сказать на русском, ну вот просто не знаю перевода термина, или что хуже — знаю что есть несколько переводов, и часть из них — явно кривые.
А никак не надо переводить. Вот как перевести на русский слово атмосфера (греч.), галоши (франц.), зонтик (голланд.), бутерброд (нем.)? Да никак, просто берется слово вместе с понятием.
Можно изобретать колоземицы и мокроступы, но наверное не стоит.
не раз уже встречалось что я не знаю как что-то сказать на русском, ну вот просто не знаю перевода термина, или что хуже — знаю что есть несколько переводов, и часть из них — явно кривые.
при этом с точки зрения репутации лучше не иметь русской документации, чем иметь устаревший и кривой перевод с английского
купил продукт дороже по цене и худшего качества у компании Adobe
шизофрения это Вера, что большой бизнес будет действовать против своих же интересов только потому что так захотелось ВАМ.
Какая связь между наличием русской документации и попаданием в госзакупки?
Причём здесь «текст ошибки», который индус перевёл ПРОМТом?
То есть майкрософт который со штатом лингвистов вполне неплохо перевел текст — это индусы с промптом виноваты? А не то, что современные системы поиска не могут найти англоязычные ответы как решить ошибку "повторяющееся значение ключа нарушает ограничение уникальности" при использовании библиотеки по работе с pdf.
Я говорю о том, что когда в JetBrains русские для русских пишут документацию на плохом английском — это #шизофрения
Они не для русских пишут — а для себя и в паблик в том числе. Да и у себя там не 100% арийцев рускоговорящих. У нас вот например в компании на 50 человек 45 русских. И ничего, общаемся все на английском, чтобы оставшиеся 10% компании не выпадали из процессов. Заодно тренируем язык.
майкрософт который со штатом лингвистов вполне неплохо перевел текст
По-вашему, русскоязычные [потенциальные] пользователи искали бы ответ на свой вопрос (наличие интересующего их русского языка) на английском?
Я ищу исключительно на английском вопросы и документацию, да.
Во-первых потому что поиск более высокое качество имеет и больш выборка. В гугле вопрос на английском находится в первых нескольких строках выдачи, в яндексе на русском можно перелопатить первые 3 страницы и видеть только вопросы на мертвых форумах с битыми ссылками.
Во-вторых потому что тупо проблемы с терминологией, из-за чего ищется не то. Например Generics — у кого-то это генерики, у кого-то дженерики, у кого-то обобщения. У кого-то ещё как-то. Если я напишу запрос "ошибка обобщения Х" то я не найду ответ если кто-то написал "ошибка с генериками Х".
Про перевод вещей а-ля Stream/Thread/Flow я молчу — тупо "поток потока потока" — удачи найти что-нибудь. Использовали "потоки" и "нити" в поисковом запросе чтобы их разделять? Надейтесь, что и другие люди так же написали, а то гугол не найдет
Я ищу исключительно на английском вопросы и документацию, да
Можно, кстати, ткнуть в пример документации на плохом английском? Мы сейчас стараемся следить за качеством документации, все новые материалы точно вычитываются профессиональными редакторами и корректорами, целый отдел этим занимается. Покажите, пожалуйста, ссылки на плохой английский в документации, я донесу куда надо. Спасибо.
Есть одно но, помимо взрослых есть дети (до 10-12 лет скажем) которым читать документацию на неродном языке сложно, увы, в итоге хотел ребёнка, после Scratch, MinecraftEdu, изучать kotlin (в связке с андроид) Но увы... Именно английский везде его оттолкнул (даже с учётом того что я готов был сидеть рядом и просто переводить всё что написано).
Играл в Dune, Warfcraft: Orc & Humans, первую циву… — никаких переводов не было, и ничего — всё понимал :) Было мне лет 5 на тот момент. До 5 лет играл в русифицированные квестики вроде кирандии.
Наоборот, лучше одноклассников шарил в языке класса до 8го
Вам не кажется что изучение программирования "методом тыка" когда нужно программу печатать буквами которых 20+ и играть в игру в которой всё визуально и надо использовать 10к кнопок с весьма информативными иконками это немного разное....
В игры дети и на китайском играть могут, а мультики спокойно смотрят на испанском и на других языках....
Я считаю, что детям не нужно читать документацию — она для них скучная. Какая-нибудь книжка "Питон для самых маленьких" будет переводная, и это не вопрос. А ребенок постарше (5-8 класс) пусть уже английский понемногу подучивает — все равно пригодится.
и играть в игру в которой всё визуально и надо использовать 10к кнопок с весьма информативными иконками это немного разное....
Ну я вот не уверен насколько тут информативные иконки например… Моя первая игра которую я начал играть в 2-3 года:
Как-то в итоге разобрался :)
Думаю записи геймплея нет, а так дети в годик могут играть в любую игру не понимая смысла, старший не умея читать и нормально говорить спокойно "читал" книжки про колобка перелистывая страницы и выражая вполне себе эмоции взрослых, которые ему эту книжку читали до этого, особенность только в том что его (как и вас в 2-3 года интересовали только меняющиеся картинки и вы понимали что тыкая что то на экране вы можете что-то поменять, но вот проблема к изучению программирования это не имеет никакого отношения, а вот когда возникает вопрос "почему тут у меня ошибка и программа не работает) тут уже надо читать (хотя бы сообщения и что написано на вкладках).
А ведь есть спец версия idea education edition к примеру, там для детей много чего бы подошло, если бы не только английский...
Ну выигрывать игру на самой простой сложности как-то получалось. Видимо, все же не совсем "перелистывание картинок". Есть вполне простой критерий — окно победы.
А ведь есть спец версия idea education edition к примеру, там для детей много чего бы подошло, если бы не только английский...
Для детей офк перевод нужен. Но для детей нужны книжки, а не документация. Скучный справочник ребенку совать бесполезно.
Это перебор всех возможных вариантов, с закреплением (хотя насчёт того что ваша память от возраста 2-3г. соответствует реально происходившим событиям есть сомнения (и тут статьи со ссылками на исследования были, про память) ну может вы вундеркинд, я не по себе сужу а по своим детям...
Что такое офк не понял, но про книжки вы наверное мыслите "от себя" увы но ребёнок хочет иметь возможность "творить" и иногда "подсматривать" а на идти по инструкции (этого в школе хватает) книжки этого не дают.
Я всё же про возраст когда на русском мы уже читаем относительно быстро и не встаём от этого(в среднем это где-то от 8 до 10 лет), а вот на английском ещё никак, при этом ограничения сред типа Scratch уже сильно мешают. (Про отдельных детей которые бегло читают на 2х языках в 6 лет речь не идёт)
А где задавали вопросы на русском? Кажется, в ZenDesk отвечают по-русски на русские вопросы.
маскируются под чехов
Странно. Мне вполне отвечают по-русски. Может ты правда на чеха попал? :)
Так вроде как раз онлайн борд и есть. Я по крайней мере issue обычно тут завожу и трекаю: https://youtrack.jetbrains.com/issues
Яндекс, Mail.ru. Во первых это коррумпирует, так как вместо работы по профилю, фирма вовлекается во всякие схемы. Во вторых моральный аспект — платя подписку JeBrains опосредованно поддерживаешь нелигитимный режим
VSCode использует Eclipse Language Srever (через Language Server Proticol). Получается, что и eclipse это тоже умный блокнот?
Развесистая - это пара миллионов строк и больше. Моя ставка - что ближе к миллионам пяти, считая более поздние не-IDE проекты. Поддерживать и развивать такие монолиты - настоящий трудовой подвиг)
3-4 года? Это мелочи. Есть тикеты, которые по 15 лет висят!
хотя технически там исправить некоторые можно довольно быстро.
Бывает так, что технически исправить просто, но не нужно.
Бывает так, что технически исправить просто, но не нужно.
Для непосвящённых звучит, честно говоря, в лучшем случае довольно странно. Можете как-то пояснить на примере?
Такие примеры появляются с завидной регулярностью (говорю про свою подсистему — язык Java). Вот буквально сегодняшнее. Пять лет назад пользователь попросил прокачать анализатор, чтобы он понимал, что метод интерфейса-аннотации никогда не возвращает null. Чтобы при сравнении с MyAnno.value() == null выдавалось Condition is always false. Изменение буквально пять строчек кода плюс тест. Очень просто. Мы сделали. Правда сам пользователь написал:
(technically,annotation.x()can be null, if someone implementsFooBarannotation explicitly, but I guess nobody does it).
И вот на днях другой пользователь жалуется, что ему выдаётся ложное предупреждение, потому что "I guess nobody does it" реализуется в некотором фреймворке. А ложное предупреждение — это гораздо более неприятная ситуация, чем отсутствие правдивого предупреждения. Потому что пользователи верят предупреждениям и могут сломать себе код, удалив проверку, которую IDE пометила как ложная. Простой пример фичи, которую не надо было делать, несмотря на то что она простая.
в clion нельзя указать toolchain файлы cmake, нельзя указать переменные среды с помощью bat или shell скриптов
Clion жрет в память как не в себя, не может проанализировать даже не очень крупные C и C++ проекты, начинает дико тормозить и жрать память
Ошибки qt, которые ломают анализатор, автодополнение, кривая поддержка st embedded — у меня даже проекты не открывает
Это вы перечислили проблемы, которые по вашим словам "технически можно исправить довольно быстро"?
во вторых параметры для CMAKE удобно писать в много строчном режиме, в одну строку писать конечно хорошо, но там вмещается всего 2 параметра
Но 200 баксов же вы берете?
Да, берём. И нам совершенно не стыдно. А что, где-то есть продуктовая компания, которая за 200 баксов вам все желания исполняет? Подскажите такую.
Это тоже тяжко сделать?
Не моя подсистема, не могу знать.
Вот как всегда в спорах в интернете. Я задал один вопрос, а мне отвечают на другой. Звучит примерно как "Тут благотворительная организация бесплатно бомжам вкусные котлетки раздаёт, а вы продаёте за пятьдесят рублей и не можете фарш качественный накрутить".
Для нас продажа IDE — основной бизнес. Наша работа оплачивается из стоимости лицензий. Если другая организация имеет другую бизнес-модель (например, зарабатывая на телеметрии, которую собирает с пользователей, или на облачных сервисах, которые ненавязчиво пропихивает пользователям, или просто у них много лишних денег), это её право. Этот факт ничего не говорит о нашей компании.
Тулчейн файлы можно указать через параметры CMake. В 2021.2 еще завезем поддержку новомодных CMake прессетов. Про параметры среды через скрипты — есть такая беда (мы вместе с платформой думаем пока, как это решить), но кто мешает в самом CMake это все указать?
Память — мы постоянно оптимизируем потребление памяти в CLion, но я замечу, что даже простенький Hello World после препроцессора не такой уж маленький на C++, так что не удивительно, что CLion после сборки информации о резолве кода во всех конфигурациях со всеми инклюдами и ветвями препроцессора отъедает много памяти. Так что оптимизировать там не всегда можно. Но что-то мы уменьшаем постоянно.
Про ошибки Qt — я бы послушала примеры и передала ребятам, они поправят. Честно сказать, уже давно не видела Qt проблем в анализаторе и автодополнении.
В какой-то момент, мне казалось, что языком "как Java, только лучше" мог бы стать Groovy.
По мнению Джеймса Стрэчена[en], создателя языка программирования Groovy, Scala может стать преемником языка Java[5].
Стрэчен покинул проект за год до релиза Groovy 1.0 в 2007 году, а в июле 2009 года Стрэчен написал в своём блоге, что возможно не создал бы Groovy, если бы в 2003 году прочитал книгу Мартина Одерского с соавторами о программировании на языке Scala (вышедшую в 2007 году)[3].
Foo<bar> foo = new Foo<bar>
var foo = new Foo<bar>();
У JetBrains, я думаю, одна из самых развесистых Java-кодбаз в мире.
Видимо, вы мало знакомы с развесистыми кодовыми базами. У нас довольно скромно по сравнению с некоторыми компаниями, которые активно используют Java.
Я действительно не знаком с кодбазами больше 1м LOC. Было бы интересно послушать мнение человека более осведомлённого.
Есть у нас клиенты, у которых кодовые базы на порядок больше нашей. Соответственно у них имеются специфические проблемы с производительностью IDE, которые не возникают больше ни у кого. Мы с ними тесно взаимодействуем и решаем эти проблемы точечно. Это к вопросу о том, что мы не интересуемся реальными проблемами пользователей (где-то в другой ветке кто-то такое утверждал).
Вам не кажется) В каком-то интервью говорили
Apache 2 на компилятор, библиотеки и плагин. Который кстати доступен в Intellij IDEA Comunnity Edition. Как говорится, не изучал, но осуждаю. Тем временем 80% процентов Android уже на Kotlin, куча бекенда на Kotlin https://kotlinlang.org/lp/server-side/case-studies/ (в том числе банки American Express, N26, Tinkoff, etc)
По разным пузомеркам у котлин уже минимум 20% отъедено от джавы. Джава кстати уже не растет последние 3-4 года, а наоборот стагнирует.
А я думал там все компании в мире отметились, оказывается нет. Можете добавить IAC тогда в которой я работаю и пишу критикал приложения и аналитику на Kotlin.
Сомневаюсь, что то так с ходу даже не вспомню какой нибудь крупный и известный проект на kotlin, кроме их IDE
Спросите джависта (который не пишет на питоне) про крупные и известные проекты на питоне, большинство не назовет ничего практически. Спросите питониста который в глаза джаву не видел, он скажет что весь мир крутиться на питоне. Такие аргументы (ну которые отталкиваются от ваших представлений об объективной действительно) смехотворны, да и вообще не аргументы.
И как правильно выше написали, тому причина проприетарность.
А потом
Не изучал лицензию, но думаю, там тоже не все гладко для разработчиков.
Научитесь делать выводы основываясь на фактах что-ли :)
Как вы всех Android разработчиков или приложения посчитали?)
https://android-developers.googleblog.com/2021/05/whats-new-for-android-developers-at.html
Kotlin: the most used language by professional Android devs
Kotlin is now the most used primary language by professional Android developers according to our recent surveys; in fact, over 1.2M apps in the Play Store use Kotlin, including 80% of the top 1000 apps. And here at Google, we love it too: 70+ Google apps like Drive, Home, Maps and Play use Kotlin. And with a brand-new native solution to annotation processing for Kotlin built from the ground up, Kotlin Symbol Processing is available today, a powerful and yet simple API for parsing Kotlin code directly, showing speeds up to 2x faster with libraries like Room.
Ну вот, стоило мне порадоваться уровню дискуссии( Постарайтесь, пожалуйста, не переходить на личности, это не помогает вашей аргументации, а ровно наоборот.
Забавно, что относительно Котлина вы приводите конкретные цифры, названия компаний и ссылки и тут же бросаетесь голословным утверждением о стагнации Java последние 3-4 года без всяких подтверждений. Java сейчас очень бодро развивается.
Java как язык конечно да. Увеличивается ли от этого значительно его популярность или это попытка удержать позиции? Массовый исход огромной индустрии Android разработки на Kotlin будем учитывать? :)
На последнем Kotlin 1.4 Online Event было представлено, что около 5.8млн разработчиков попробовали котлин (редактировали код в IDE), а также около 1.2млн активных пользователей Котлин [https://youtu.be/xJawa3C6pss?t=826]. По статистике самой JB в мире около 6.8млн разработчиков Java [https://blog.jetbrains.com/idea/2020/09/a-picture-of-java-in-2020/]
Это соотношение подтверждается различными рейтингами redmonk/pypl/etc
Или данными на Stackoverflow https://insights.stackoverflow.com/trends?tags=kotlin%2Cjava%2Cgroovy%2Cscala
Есть и другие анекдотические совпадения, так например число людей в сабредите Kotlin [https://www.reddit.com/r/Kotlin/ https://www.reddit.com/r/java/] около тех самых 20%
Откуда пришли эти разработчики? У меня нет четких статистических данных, но на митапах которые мы проводили, опросы показывали что в зале сидят бывшие джависты. Получается джава потеряла большой процент (около 20%) разработчиков за 5 лет, это ли не стагнация?
Вы похоже еще не обновились на Android Studio 4.2
Там уже используется Java 11
А ART во всех версиях андроид что используют клиенты тоже до уровня Java 11 обновился с выходом Android Studio 4.2?
Конечно нет. Но уже можно писать код на Java 11 под Android, а то будет ли он вообще работать на старых устройствах или будет заменен на другой код - это другой вопрос.
Моя ошибка — надо было блогпост про релиз ASO 4.2 прочитать. После чтения гугловского блога более подробно — теперь яснее.
Конструкции языка — да, будут работать. Насколько понимаю — на любом андроиде.
Библиотечные API — вообщем все плохо. Как и раньше — работает (на любом андроиде) только то что указано в https://developer.android.com/studio/write/java8-support-table
Ну уже неплохо.
В Android как бы у Kotlin большое преимущество в том что то что вместо JVM(ART) у Android не обновляется почти в плане поддержки новых версий (а даже если бы и обновлялось — у андроида все далеко не хорошо с обновлением системы а значить — привет совместимость. ART хотя бы потенциально обновляем отдельно от самого Android начиная Android 10).
А Kotlin'у на версию JVM плевать вообщем то. Что в данной ситуации — огромное преимущество. Для Android разработки — Kotlin не с вышедшей полгода назад версией Java сравнивать надо а с Java 8 в лучщем случае.
В Java вплоть до 14-й версии это выглядело так:Не дай Kotlin пинка, Java так и осталась бы без фич. А так хоть с «худшего языка» их взяла. Kotlin прокладывает путь для Java, и, очевидно, это сложно. Поэтому и вылезают проблемы, когда Java догоняет обратно
Скрытый текстif (x instanceof String) { String y = (String) x; System.out.println(y.toLowerCase()); }
В Kotlin сделали примерно так:
Скрытый текстif (x instanceof String) { // теперь x имеет тип String! System.out.println(x.toLowerCase()); }
Но в Java версии 16+ стало так:
Скрытый текстif (x instanceof String y) { System.out.println(y.toLowerCase()); }
Не дай Kotlin пинка, Java так и осталась бы без фич.
Это да. Поговаривают даже, что дженерики в пятую джаву завозил лично Бреслав :)
В жабу внесли плохую фичу. В этом примере — 16+ вариант это синтаксический сахар для варианта 14+, с неявным созданием экземпляра класса, а в Котлине это неявное преобразование типа внутри.
Причём жаба как-то неинтуитивно модифицирует поведение самого оператора instanceof.
Какого экземпляра класса? Вы о чём? Никаких экземпляров не создавалось ни до, ни после.
"y" это что?
Локальная переменная.
String это уже базовый тип?
Удивительно, что люди рассуждают о дизайне языков программирования, не зная этих языков программирования даже в самом минимальном объёме. Я на третьей лекции по Java для начинающих уже рассказываю, что присваивание в Java копирует ссылку, но никогда не копирует сам объект, потому что это никому не нужно и копирование объекта в Java в общем случае неразрешимая задача. Причём JIT-компилятор может и копирование ссылки соптимизировать (и сделает это практически всегда в данном сценарии кода, потому что нет причин так не делать).
Если они таки смогут нормально продвинуть мультиплатформу, то всё будет хорошо
Java и Rust — это вообще два разных языка. Первый для больших (квази-)монолитных прикладных задач, второй — для системного программирования.
Вы ошибаетесь. Rust — универсальный ЯП, хоть и позиционируется прежде всего как системный. Поэтому так медленно и отвоевывает себе рынок. Реально Rust так же интересно использовать в прикладной разработке, как и в системном программировании, если не интереснее.
Я хоть и пишу (с удовольствием) на расте, но справедливости ради сборка мусора упрощает многие моменты в коде. Поэтому не верю, что раст или любой другой системный язык сможет вытеснить managed языки.
У меня есть pet-project на Go, это IoT-сервер с большим REST и WS API, очередями, внутренними кэшами и т.д. Он занимает в памяти 50 мегабайт и работает на Raspberry Pi. Всё, как обычно, зависит от решаемых задач и умении инженера избегать лишних аллокаций.
Вон, тот же Go это просто нативная JavaВы простите, но я не верю, что человек, трогавший оба этих языка хотя бы 15 минут каждый, может такое всерьёз сказать. И это даже не говоря об остальном.
Казалось бы, потребление памяти - далеко не единственный критерий сравнения языков программирования.
А продукты ещё и написать можно по-разному.
Помню когда-то давно читал о (почти) рандомизированном исследовании, где программистов пригласили решить какие-то задачи на Си или Яве.
The conclusions showed that Java was 3 or 4 times slower than C or C++, but that the variance between programmers was larger than the variance between languages, suggesting that one might want to spend more time on training programmers rather than arguing over language choice. (Or, suggesting that you should hire the good programmers and avoid the bad ones.) The variance for Java was lower than for C or C++. (Cynics could say that Java forces you to write uniformly slow programs.)
выделено мной
Я хоть и пишу (с удовольствием) на расте, но справедливости ради сборка мусора упрощает многие моменты в коде.
Где же, блин, язык с RAII и сборщиком мусора? Не хочу руками закрывать файлы.
Справедливости ради, закрываются они не совсем руками, а через всякие "try with resources".
Но вообще согласен. Не понимаю как так жить, особенно если ресурс находится внутри другого объекта. Правда думаю, что это скорее мои заморочки, как человека, который всё жизнь писал на С++ и последние четыре года на расте. В конце-концов как-то люди пишут на джаве, C# и т.д.
Из этой же оперы: не понимаю как люди мирятся с невозможностью "передать по константной ссылке". В том плане, что по сигнатуре функции не видно будет ли она менять переданные объекты. В полностью иммутабельных языках это действительно не важно.
Из этой же оперы: не понимаю как люди мирятся с невозможностью "передать по константной ссылке". В том плане, что по сигнатуре функции не видно будет ли она менять переданные объекты. В полностью иммутабельных языках это действительно не важно.
Я лично решаю это тем что классы иммутабельные и для изменения чего-то нужно делать глубокую копию. Кажется что неэффективно, но засчет fearless sharing как раз можно хорошо жить.
Сразу оговорюсь, что в хаскеле я не особо разбираюсь, так что могу сказать глупость, но вижу, что кроме withFile есть и openFile. То есть, можно воспользоваться второй функцией и забыть вручную закрыть файл. Если апи использует RAII, то для этого потребуются специальные приседания.
И как быть если файл у нас вложен в другой объект? Какой-нибудь SomeManager внутри которого содержится ресурс (а может и не один). В деструкторе такого "менеджера" даже делать ничего не нужно. Правильно я понимаю, что в подходе с withХ придётся это всё протаскивать наружу?
Так и в плюсах можно случайно вместо#include <fstream>сделать#include <чётосишное>и использовать старый-добрый fopen. Даже приседать не надо.
Я всё-таки больше раст в уме держал: там настолько легко сишные функции протащить не получится. Впрочем, у fstream интерфейс тоже достаточно отличается от сишного, чтобы это не прошто незамеченным.
Насчёт линейных типов и монад: изначально всё-таки речь шла про RAII против языков с GC. Формально, конечно, хаскель и прочие попадают во вторую категорию, но я верю, что там всё сделано достаточно хорошо и интересует как в C#/Java.
чего не было доступно во времена Haskell98, да и сейчас не факт что в хаскеле можно
Насколько я понимаю, все пользуются System.IO "без заморочек"?..
Да не особо. Там, конечно, появляется уровень абстракции в виде всяких управляющих ресурсами монад, но with вам тягать везде не нужно.
Если не лень, то я бы хотел взглянуть на пример. Только желательно с комментариями.
Насчёт линейных типов и монад: изначально всё-таки речь шла про RAII против языков с GC. Формально, конечно, хаскель и прочие попадают во вторую категорию, но я верю, что там всё сделано достаточно хорошо и интересует как в C#/Java.
так тот же бракет сделано в сишарп/джаве с using/try-with-resources. В этом плане тут паритет
Ну withFile на openFile вам случайно заменить тоже не получится.
Да, случайная замена звучит нереально, но допустим я впервые с этим апи сталкиваюсь, увидел подходящую функцию и использовал не вчитываясь в документацию (где как раз и советуют withFile).
Ну ладно, я согласен, что такие проблемы звучат очень натянуто. С другой стороны, сишники вон тоже говорят, что как можно забыть проверить указатель на null?! RAII всё-таки делает апи чуть проще в использовании.
тем что оно лучше композируется и не требует лапши из коллбеков. Тот же bracket насколько я знаю хоть и решает проблему, но не идеально.
Впрочем, если обмазать API типами достаточно плотно (чего не было доступно во времена Haskell98, да и сейчас не факт что в хаскеле можно), то можно гарантировать статически, что любой openFile будет завершён с closeFile. Опять же, что-то там про линейные типы, про rank-2 polymoprhism, и так далее.
Раии по сути это и есть линейные типы и статическая гарантия что закрытие будет вызвано. По крайней мере если мы про раст.
Я затрудняюсь вспомнить, когда мне последний раз нужно было что-то умнее, чем «открыть несколько ресурсов со строго вложенными скоупами».
Часто ресурс приходит параметром или нужно возвращать из функции — раии позволяет не думать про то, кто ответственен за корректное закрытие. Особенно когда речь не про свой код, а про фреймворк. В общем, там есть нюансы. Хотя верю, что в хачкеле параметричность уважают, но вот в мейнстриме — не очень.
Ну там вообще больше про экзепшоны, а с ними в хаскеле вообще отдельный разговор.
Ну раии решает в т.ч. проблему с ошибками во время инициализации/деинициализации.
Да я ж не спорю. Просто вон выше противопоставляется RAII и GC, а при должном обмазывании типчиками одно другому вообще не противоречит.
ну раии не противоречит, а вот линейные типы вполне позволяют обойтись, собственно раст тому пример. Т.к. у нас все линейное, то после последнего использования вставляем компилятором деаллокацию и профит — гц не нужон.
Ну что принципиально она упрощает? Я писал долгое время web-приложения на Java, теперь пишу на Rust. И разницы не замечаю (в вопросах удобства управления памятью). А вот то, что теперь не надо тюнить JVM, чтобы сделать выделение памяти и сборку мусора предсказуемой — очень даже чувствую.
Я Java-приложения на Rust не переписывал. Просто говорю по своему опыту, что возни с GC в крупных приложениях на Java больше, чем проблем с BC (наличие которого через полгода практики перестаешь замечать).
Писал только неприличные приложения видимо.
Последний объем кодовой базы составляет порядкм 1mloc, не сверх много, но кмк релевантно. На расте многие вещи менее удобно делать чем на языках с гц, но не на порядок и думаю даже не в разы.
-XX:+UseLargePages
-XX:+UseTransparentHugePages
Прям столько всего сразу что даже не знаю с чего начать:)
Да ладно? вы в принце не понимаете даже зачем в java gc.
Ну да, я пишу на жабе/шарпе 10 лет, но не понимаю зачем там гц. Не знаю что пространство ручек гц состоит из по крайней мере 15 тредофов. Не знаю про существование G1,Shenandoah,ZGC и какие у них характеристики… Ничего не знаю, просто фанбойствую по расту :)
Java это в первую очередь не десктоп, и не веб и микросервисы, это в первую очередь обработка больших данных для целей бизнеса!
Скажите, HFT биржи обрабатывают большие данные или нет? Просто любопытно.
На данный момент судьба rust в в ядре Linux под вопросом, и вполне может быть, что поддержку rust для создания модулей ядра Linux даже не примут.
может и не примут, но я бы поставил что примут. Надо подпилить некоторые вещи. Но при чем тут это не сильно понятно — у линуса проблема в том, что ядру паниковать плохо. А вот в юзерспейсе (где 100% жаба аппов выполняются) это наоборот хорошо — приложение просто падает, а не совершает УБ или молча портит чужую память.
Есть ли в Rust MapReduce?
Нет
Знаете, что означает, что стрелчока вниз здесь не красная, а такая же серая, как и стрелочка вверх? Что я вам вообще никакие оценки не ставил.
Я программист — это фотошоп!
Вопрос не в том медленный гц или нет — вопрос в том, что у него трейдофы, которые не всем подходят. Уж вы-то должны знать, что идеальный гц без пауз и с хорошим throughput не сделали пока. Худо-бедно жабка к этому приблизилась с гц новых поколений, но и все.
Во-вторых даже если гц работает в среднем норм если у вас будет пауза когда не нужно то будет печально.
За последние пару лет мне штук 10 разных контор предлагало писать хфт на расте. Дурачки, наверное, не осилили жабу :)
При правильном написании нет таких проблем и не было впринципе, мне лично удавалось значительно ускорить алгоритмы, только засчет уменьшения хранимых данных и переписать алгорим так, чтобы сборка мусора тригерилась меньше и не было долгих пауз.
Можно, не спорю, я лично с Акиньшиным например общался на эти темы. Вопрос в том, что во-первых не всё можно выжать, а во-вторых иногда приходится делать совсем дикие вещи чтобы сравняться с нативной производительностью более низкоуровневых языков.
А потом оказывается, что и этого недостаточно.
Я более чем представляю, что из ГЦ языков можно выжать крутой перф. Вопрос в том, что не только лишь все это умеют, и что из джавы выжать приличный перф может быть сложнее, чем из раста слепить удобное приложение. Никто не говорит что невозможно — просто дороже, по тем или иным критериям.
Впринципе можно писать на чем угодно, сборка мусора не помеха, у меня это было C++и С#.
Ну да, норм ситуация когда решение нужно принимать за микросекунды, а люди стараются чуть ли не на крыше биржи развернуть компы чтобы снизить задержку, а вы можете себе позволить миллисекундные запуски ГЦ. Понимаю.
при работе с бинарными данными количество сборок мусора в сотни, а то и тысячи раз меньше.
Простите, что?
HFT не подходит крупным игрокам
Простите, чтооо?
Вы уверены? Вы знаете кого-то из этих гениальных людей? Мне лично знакомо несколько людей из средних компаний, но там нет HFT и они даже не собираются заниматься HFT
огда говорят про HFT и Роботов это имхо разводняк полнейший, чтобы кинуть потом инвесторов и домохозяйк
Впринципе объем для HFT необходимый есть во фьючерсе на индекс S&P 500, но там тоже объем где-то на несколько миллионов, а у крупных игроков на миллиарды могут быть позиции. У них большии позиции и к примеру даже 15% годовых для большого количества миллиардов будет лучше, чем 40% годовых от 50 миллионов…
Неважно на 64-битных системах.
А почему для 64-битных систем это не важно?
Это троллинг такой? Данные из памяти в кэш процессора загружаются страницами, время доступа к любой странице памяти - одинаковое.
sysbench 1.0.20 (using system LuaJIT 2.0.5)
Running the test with following options:
Number of threads: 24
Initializing random number generator from current time
Running memory speed test with the following options:
block size: 1KiB
total size: 102400MiB
operation: write
scope: global
Initializing worker threads...
Threads started!
Total operations: 86360561 (8635349.12 per second)
84336.49 MiB transferred (8432.96 MiB/sec)
General statistics:
total time: 10.0001s
total number of events: 86360561
Latency (ms):
min: 0.00
avg: 0.00
max: 4.69
95th percentile: 0.00
sum: 224001.99
Threads fairness:
events (avg/stddev): 3598356.7083/38465.60
execution time (avg/stddev): 9.3334/0.02
sysbench 1.0.20 (using system LuaJIT 2.0.5)
Running the test with following options:
Number of threads: 24
Initializing random number generator from current time
Running memory speed test with the following options:
block size: 1KiB
total size: 102400MiB
operation: write
scope: global
Initializing worker threads...
Threads started!
Total operations: 7756804 (775616.10 per second)
7575.00 MiB transferred (757.44 MiB/sec)
General statistics:
total time: 10.0001s
total number of events: 7756804
Latency (ms):
min: 0.00
avg: 0.03
max: 5.03
95th percentile: 0.04
sum: 238535.76
Threads fairness:
events (avg/stddev): 323200.1667/2891.61
execution time (avg/stddev): 9.9390/0.00
sysbench 1.0.20 (using system LuaJIT 2.0.5)
Running the test with following options:
Number of threads: 24
Initializing random number generator from current time
Running memory speed test with the following options:
block size: 1KiB
total size: 102400MiB
operation: write
scope: global
Initializing worker threads...
Threads started!
Total operations: 86603946 (8659684.88 per second)
84574.17 MiB transferred (8456.72 MiB/sec)
General statistics:
total time: 10.0001s
total number of events: 86603946
Latency (ms):
min: 0.00
avg: 0.00
max: 4.02
95th percentile: 0.00
sum: 224407.46
Threads fairness:
events (avg/stddev): 3608497.7500/41590.58
execution time (avg/stddev): 9.3503/0.02
sysbench 1.0.20 (using system LuaJIT 2.0.5)
Running the test with following options:
Number of threads: 24
Initializing random number generator from current time
Running memory speed test with the following options:
block size: 1KiB
total size: 102400MiB
operation: write
scope: global
Initializing worker threads...
Threads started!
Total operations: 7765473 (776484.10 per second)
7583.47 MiB transferred (758.29 MiB/sec)
General statistics:
total time: 10.0001s
total number of events: 7765473
Latency (ms):
min: 0.00
avg: 0.03
max: 6.02
95th percentile: 0.04
sum: 238534.54
Threads fairness:
events (avg/stddev): 323561.3750/2858.37
execution time (avg/stddev): 9.9389/0.00
Данные из памяти в кэш процессора загружаются страницами, время доступа к любой странице памяти — одинаковое.
Это троллинг такой? Данные из памяти в кэш процессора загружаются страницами, время доступа к любой странице памяти — одинаковое.
Если мы о о огромных данных в десятки гигабайт, то оверхэд, присущий языкам с GC, приводит к тому что приложение требует в 2-3 или разы больше памяти, чем на языках без GC, что может приводить к тому, что с GC приходится использовать своп (а без GC оно могло бы и влезть бы), что гораздо больше замедляет, чем фрагментация.
В ряде имплементаций с/с++ 16-битный инт и строки по байту ))) Кстати строки в С++ мутабельные.
Похоже, вы ошибочно полагаете, что цена на GC — это только количество мусора, которое в данный момент в куче лежит и ждет сборщика. Нет, не только и даже скорее не это. Проблема еще и в том, что вы некотрые вещи делать не можете. Если в Си вам нужно вызвать функцию, которая изменяет элемент в массиве, вы можете передать это голым указателем. В Яве вам нужно передать ссылку на сам массив и индекс. Нельзя делать XOR linked lists. Нет value-types. Из-за этого массив каких-нибудь java.awt.Point будет занимать в разы больше места, чем в Си++, при этом НИКАКОЙ игры с битами тут не происходит. Ну, конечно, если заранее известно что в программе много таких данных будет можно хранить их в массиве примитивов и запаковывать-распаковывать по мере необходимости. Можно один массив байтов выделить на все, тогда оверхэда не будет. Но это будет не идиоматическая Ява.
Я вообще не понимаю, почему просто было не ограничиться заявлением, что GC ускоряет разработку програм (что верно) и приписывать достоинства, которых у него нет.
В ряде имплементаций с/с++ 16-битный инт и строки по байту )))
Если в Си вам нужно вызвать функцию, которая изменяет элемент в массиве, вы можете передать это голым указателем. В Яве вам нужно передать ссылку на сам массив и индекс.
Нет value-types
Но это будет не идиоматическая Ява.
Я вообще не понимаю, почему просто было не ограничиться заявлением, что GC ускоряет разработку програм (что верно) и приписывать достоинства, которых у него нет.
В сишарпе все это можно сделать. При этом такой же гц язык что и джава — просто с чутка другими возможностями.
При чем тут гц-то?
Ну допустим не все из списка, а что-то. Полиморфизм для value types там что-то порезанный по сравнению с с++.
Ну а гц тут при том что его наличие толкает в такую сторону развития языка. Так-то можно и с++/cli вспомнить в котором есть мусосборные указатели и традиционные и (вероятно) наличие 1-го не влияет на
В scala value types есть, но вроде как аггрегрировать в такой объект можно только один value-объект другого типа, остальные будут по ссылке.
А в сишарпе есть value-type arrays?
В шарпе есть и value-type массивы, и VLA на стеке, и много всякой всячины для байтокрутства.
Появилось таки о.о
Как и для байтокрутства там были голые unsafe pointers всегда.
Но эти новые фичи сколько-нибудь широко используются разве? Если там массив на стеке объявить, то будут ограничения, куда его можно передать и существующие библиотеки недружественны к этому?
Можно передавать куда угодно (только не возвращать из функции конечно :) ). stackalloc был в языке по-моему с самой первой версии. Но начиная с 7.2 с ним работать стало куда удобнее: в языке появилась нативная возможность безопасно создавать спаны (это так в шарпе слайсы называются) из них.
Большниство методов стдлибы были переписаны чтобы вместо массивов принимать слайсы (парсинг к примеру). Многие популярные библиотеки сделали так же.
В общем — жить можно.
Про "стринги"
https://m.habr.com/ru/post/134102/
Я конечно не проверял 40 там байт или нет на строку с одним символом, но при загрузке данных из бд складывается впечатление что это правда...
List<Integer>Ну что принципиально она упрощает?
Весь код, где в расте будут торчать лайфтамы?.. Сюда же заморочки с DST (просто боксим всё), impl Trait (до этой фичи возвращать итераторы иногда было весьма неприятно). Попадалась ещё хорошая статья почему в расте нельзя сделать do нотацию, но сейчас что-то найти не могу.
Заранее соглашусь, что в некотором "среднем в вакууме" коде это не особо чувствоваться будет.
Попадалась ещё хорошая статья почему в расте нельзя сделать do нотацию, но сейчас что-то найти не могу.
Потому что сигнатура функций не монадическая. Нарпимер у итераторов:
должно быть map : (a -> b) -> f a -> f b
что есть по факту: map : (a -> b) -> f a -> Map f b
Конечно есть "псевдомонады", типа линейные монадки и т.п., то есть можно было рассахаривать как скала — без проверок типов, просто адхоком, но чет не захотели. Наверное потому что у разных типов по-разному называется: где-то flat_map, где-то and_then, ...
Потому что сигнатура функций не монадическая.
А почему?
Потому что в языках где монады обычно используют есть ГЦ и все типы бокшенные. Раст же претендует на низкоуровневость, боксы там явные, из-за этого хотя и аргумент мапа и результат реализуют один и тот же интерфейс итератора, но реализации там очевидно разные. С точки зрения забокшенных "нечто что реализует итератор" разницы нет, с точки зрения конкретных типов — ещё как.
В подовляющем большинстве случаев используется просто lifetime elision.
Помнится я писал в свое время статью что "Так ли страшен раст", где рассказывал, какой он прекрасный язык общего назначения.
Спустя 3 года могу сказать: да, на нем можно вполне удобно программировать многие вещи, но можно ещё удобнее. Раст удобен более мощной системой типов чем в мейнстриме, но система типов у той же скалы ещё мощнее, да ещё и нет мешающегося борровчекера.
Переметнулся? )
Не знаю, но я использую Rust уже 4 года, и количество проектов, где я его с успехом для себя применяю — растет. И все это прикладная разработка. Rust тем и хорош, что это императивный язык по-сути, он сильно проще, чем Scala.
А боров… он страшен только пока не наберешь опыта и не переключится мозг. Через полгода ежедневного программирования уже его не замечаешь совсем.
это императивный язык по-сути, он сильно проще, чем Scala
Ну вопрос в том, применял ли ты языки типа скалы/хачкеля в проде или нет. Если нет — то раст язык богов, тайпклассы, адт, борровчекер...
А если применял — то начинает нехватать rank2, gadt, линз и прочих вкусностей сильных систем типов.
Все познается в сравнении. Ту статью я писал на впечатлениях после сравнения с шарпом. По сравнению с хаскелем все куда грустнее (но офк адопшн получше будет, хотя и не сильно. Но тренд лучше это точно)
А боров… он страшен только пока не наберешь опыта и не переключится мозг. Через полгода ежедневного программирования уже его не замечаешь совсем.
Совсем он не пропадает это точно. Достаточно написать достаточно сложню рекурсивную асинк функцию чтобы пины и лайфтаймы повылазили во все стороны :)
Достаточно написать достаточно сложню рекурсивную асинк функцию чтобы пины и лайфтаймы повылазили во все стороны :)
Возможно, но с необходимостью такое писать в асинк-коде пока еще не сталкивался на практике. Подозреваю, что это скорее исключительный случай.
На Scala я ничего серьезного не разрабатывал, но много лет назад брался ее изучать. Сначала все сильно нравилось, а потом стал пробовать писать код посложнее и смешение ООП и функционального подхода мне нравиться перестали. Rust в этом смысле более практичный язык, как мне кажется. Хотя конечно, многих ФП-плюшек в нем не хватает.
Возможно, но с необходимостью такое писать в асинк-коде пока еще не сталкивался на практике. Подозреваю, что это скорее исключительный случай.
Да элементарно — нужно обойти дерево и для каждого узла сделать асинк вызов. Ну типа хабра — у нас есть дерево айдишек комментариев, хочется получить их контент.
Можно конечно передавать дерево айдишек и сбоку хэшмапу типа "по айдишке контент сам найдешь", но как-то это коряво что ли. Собственно, в расте часто приходится вот так вот немного костыльно делать: арены из-за невозможности кросс-ссылок пилить ну и вот это все. Жить можно, но удобство ниже, чем когда этим заниматься не приходится.
На Scala я ничего серьезного не разрабатывал, но много лет назад брался ее изучать. Сначала все сильно нравилось, а потом стал пробовать писать код посложнее и смешение ООП и функционального подхода мне нравиться перестали.
В скале ООП не больше чем в расте имхо. Если речь не про интероп с джавой, но про интером раста с си тоже можно много чего интересного сказать :)
Такое поведение имеется ввиду?
struct Comment {
id: u64,
children: Vec<Comment>,
}
impl Comment {
#[async_recursion(?Send)]
async fn walk(&self) {
let content = get_content(self.id).await;
println!("{}", content);
for child in &self.children {
child.walk().await;
}
}
}
async fn get_content(comment_id: u64) -> String {
format!("Content of {}", comment_id)
}Нет, функция должна возвращать результат. У меня вышло вот так:
fn get_comments(node: Tree<i32>)
-> Pin<Box<dyn Future<Output = Tree<Comment>>>> {
Box::pin(async move {
match node {
Leaf(x) => Leaf(get_comment(x).await.unwrap()),
Branch(x, left, right) => {
let result = get_comment(x).await.unwrap();
let left = get_comments(*left).await;
let right = get_comments(*right).await;
Branch(result, Box::new(left), Box::new(right))
}
}
})
}Мб это можно переписать лучше, но я не в курсе.
Но мой поинт данный код тоже показывает) Я пишу раст с 2017 года, последние пару лет даже в прод. Сижу постоянно в мейне расточатика в телеге, ну и в целом интересуюсь статьями/гайдами… И при этом я вот этот #[async_recursion(?Send)] в первый раз вижу :)
Из чего делаю вывод что даже если все так как ты говоришь, то до уровня "не замечаю лайфтаймы" смогут дойти не только лишь все.
Открою маленький секрет: если попытаться скомпилировать мой код без async_recursion, то компилятор скажет
error[E0733]: recursion in an `async fn` requires boxing
--> src/main.rs:10:26
|
10 | async fn walk(&self) {
| ^ recursive `async fn`
|
= note: a recursive `async fn` must be rewritten to return a boxed `dyn Future`
= note: consider using the `async_recursion` crate: https://crates.io/crates/async_recursionТак что в данном случае, наверное, такой код смогут написать почти все, кто вообще дошел до async/.await в Rust ))
Так нам надо не обойти дерево — а сделать второе дерево с той же структурой.
Чтобы просто обойти не надо никакой walk вызывать — достаточно сделать IntoIter и дальше форыч, джоин или ещё что угодно.
Так что в данном случае, наверное, такой код смогут написать почти все, кто вообще дошел до async/.await в Rust ))
Так фишка в том, что я асинк-авейт как раз направо-налево использую. Интересно, в какой версии этот note добавили.
(квази-)монолитных
Это мимо. Монолитность можно начем угнодо создать и ява тут непричем
Что-то среднее между Java и Rust в смысле рантайма — это Go.
Rust по-умолчанию использует системный аллокатор, но может использовать и любой другой, пользовательский (например, jemalloc). Также сборщик мусора можно сделать в виде внешней библиотеки.
Вообще, есть мнение (неподтвержденное), что следование концепции владения и заимствования в Rust, которая относится к любым ресурсам в программе, приводит к лучшей архитектуре, чем без него.
может даже быть так, что на JAVA приложение будет работать в продакшене даже быстрее написаного на RustПриведите пример, пожалуйста ;)
Плюс скорость разработки сложных приложений значительно выше на JAVA
Очень спорно. Хорошая система типов в Rust увеличивает скорость разработки и поддержки именно сложных приложений.
Сравнивать экосистемы Java и Rust сейчас совершенно бессмысленно — у Java она просто гигантская.
Но вот о технологических фичах стоит поговорить: почему какой-нибудь Яндекс пишет добрую половину своих сервисов на C++? Почему не все на Java? Потому что когда начинают считать, во сколько серверов обойдутся фичи Java, все ее преимущества сходят на нет. Но C++ дороже в разработке и поддержке — вот и получается 50 на 50 (грубо). А Rust — он как раз в этой средней точке.
Думаю, основная причина — экспертиза существующей команды и имеющиеся многолетние наработки на С++. Дорого не производительность, а миграция и переобучение сотрудников. У Одноклассников практически весь бэкэнд на Java. У Twitter Скала. Нагрузки и там, и там тоже о-го-го.
Встречный вопрос: сколько GC вы знаете? Вы в курсе, что их в Java как минимум 4:
serial
parallel
cms
g1
У каждого GC есть свои плюсы и минусы. А вызов подходящего GC можно запланировать, сведя "тормоза" практически к нулю - было бы желание и соответствующие компетенции.
Это вы всё про Java говорите. А в Go сборщик мусора всего один и толком не настраивается.
GC занимаются очисткой памяти уже имея информацию для идентификации мусора.
А информация для идентификации обычно создается за пределами GC во время непосредственной работы с объектами. Есть 2 самых популярных алгоритма для этого: подсчет ссылок и выставление флагов.
В Java используется как раз алгоритм выставления флагов. Алгоритм подсчета ссылок используется в некоторых других языках.
Чтобы немного разобраться в этой теме можно почитать википедию: https://ru.m.wikipedia.org/wiki/%D0%A1%D0%B1%D0%BE%D1%80%D0%BA%D0%B0_%D0%BC%D1%83%D1%81%D0%BE%D1%80%D0%B0
Тоже читал что в старых версиях JVM был доступен счетчик ссылок. Думал, что в современных версиях от него отказались полностью, перейдя на алгоритм выставления флагов. Хотя сейчас задумался, а вдруг алгоритм подсчета ссылок не выпилили и его можно как-то включить? Но зачем его включать? Это повысит производительность или решит еще какие-то проблемы?
Расскажете какой трассирующий ГЦ у файрфокса который на 10 табах сожрал мне почти 3 гигабайта памяти?
У джаваскриптового движка в файрфоксе разве не трассирующий gc?
У жс движка да, только отключение жс не то чтобы сильно помогало (на тех сайтах где без ЖС хоть что-то работает офк). А остальное там — всё плюсы.
Ну и о чем речь — недавно на расте пробовал писать — хелловорлд гуй с одной кнопкой и канвасом сожрал 300 метров памяти. Никакого гц офк там нет даже близко.
А если бы этот фаерфокс переписать на Яве, сколько бы он памяти требовал бы для работы?
Если вы отключили JS на странице, это не значит, что он не используется в браузере для каких-то внутренних целей. И настройки браузера во вкладке about:preferences с ЖС, а не нативное окошко системы, как раньше...
Забавно видеть, что каждый комментатор живёт в своём пузыре. У вас вот вселенная, где весь бэкэнд на Го.
Прошелся по нашему стеку. Новые бэкэнды пишутся на: PHP, Kotlin, GO и Phyton. Язык выбирается в зависимости от задачи
kotlin/js активно развивается. Над ним и над kotlin/wasm работает отдельная команда (пусть и небольшая). Подробности можно узнать в публичном роудмапе https://kotlinlang.org/docs/roadmap.html
Большим зло считаю как раз то, что типа справа
В новых языках такой подход преобладает. Я бы даже взялся спорить, что лет через десять этот вариант будет доминировать.
Тут у меня сразу вспоминается дико не удобный objective c, с которым Apple хотела поменять отношение к программированию, все закончилось тем что программистов не прибавлялось, и выпустили swift…
А типы слева это как раз одна из главных ошибок С подобных языков, которые ломают им всю логику парсера.Не могли бы привести аргументы, как происходит эта ломка? Какие трудности возникают у парсера?
Лексер становится контекстно-зависимым, что ведёт к штукам вида lexer hack
Не могли бы Вы показать какой-нибудь известный Вам пример? Я не настолько погружён в контекст, чтобы найти его самостоятельно, но увидеть это самое "не сложно и без извращений" было бы интересно.
Лучше синтаксиса С и JAVA нет, они хорошо читаются и хорошо соотносятся с математической логикой
Хм, а пруфы будут? Уж по мне, они как раз таки далеки от математики. Вот как мы записываем или читаем выражения в математике? Например, переменная: x ∈ ℕ — сперва имя, потом тип. Или функция: f: ℕ -> ℕ — имя, потом "тип аргумента", потом "возвращаемый тип".
И языки с постфиксными типами выглядят более консистентно. А с префиксными типами всегда выходят костыли. Вот на java:
public class ApiService { // публичный класс "апи сервис"
private String prefix = '/api'; // У которого есть приватная строка "префикс"
public List<Item> getItem(int Id) {} // У которого есть публичный список элементов "получить элемент"? А не, тут мы читаем сперва первое слово, потом середину, потом 2-е слово. Выглядит логично?
public void someMethod() {
String a = 'b'; // Строка "а", тут нормально.
var b = 1; // А тут var уже не тип, а специальное слово
}
}А на typescript всё уже получше, как минимум всё выглядит логичнее и единообразнее:
export class ApiService { // публичный класс "апи сервис"
private prefix: string = '/api'; // с приватным полем "префикс" типа строка
public getItems(id: int): Array<Item> {} // с публичным методом "получить элементы", который на вход принимает id с типом "число" и возвращает массив объектов "Item". Очень похоже на математическую запись. Да и определения читаются всегда слева направо, а не скачут
someMethod(): void {
const a: string = 'b'; // константа "а" с типом "строка"
let b = 1; // переменная b. И выражение с типом, и без него выглядит одинаково
}
}В котлине (да даже в том же питоне) же этот пример ещё более консистентен: там явно всегда указывается, что нечто перед нами — функция или же переменная (хотя в питоне для обозначения переменных нет отдельных слов). Но общая тенденция постфиксных типов хороша, а все языки с префиксными типами выглядят костыльно, когда пытаются внедрить type inference, или описать функцию (особенно когда функция возвращает функцию).
С другой стороны, минусы у синтаксиса котлина тоже есть — сложная муть с конструкторами разных видов и другие раздражающие мелочи.
Еще проблема kotlin, что они не создали свою виртуальную машину, а просто сделали транслятор в байткод JVM.
И в javascript. И в нативный код для разных платформ. В чём минусы-то?
функция: f: ℕ -> ℕ — имя, потом «тип аргумента», потом «возвращаемый тип»
y = f(x) // вызов функции fтип f(тип) // объявление
y = f(x) // вызовf(тип) -> тип // объявление
f(x) => y // вызовГде тут находится возвращаемое? Возвращаемое находится слева!
Да нет, оно справа, в самой функции. Не верете? Где тогда возвращаемое тут g(f(x))? Тоже слева? А ведь мы можем рассматривать = как функцию: set(y, f(x)), ведь у нас тут есть и "вызов функции f", и "оператор присваивания", то есть несколько действий.
Тогда слева в записи y = f(x) просто имя переменной, которой мы присваиваем значение справа от операнда (который есть функция от 2-х переменных, просто они в другом порядке записаны). И читаем слева направо. А сигнатуры типов (которых тут нет) читаются также: имя функции, потом типы. Тоже слева направо.
g(f(x)) // до вызова f
g(первое возвращаемое) // поле вызова f, но до вызова g
второе возвращаемое // после вызова gy = f(x) // до вызова fy = возвращаемое // возвращаемое кладётся на место f(x)y <- f(x)y <- f(x)f(тип 1) -> тип 2b + c -> a; // слева — вычисляемое выражение,
// справа — имя перезаписываемой переменнойВсе уже придумано до нас https://www.informit.com/articles/article.aspx?p=2425867 (сожаление №5)
Одно из больших преимуществ типа справа — синтаксическое разделение аннотаций на переменной и аннотаций на типе. Смотрите:
@Anno
var x : Int // аннотация на переменной
var y : @Anno Int // аннотация на типеА теперь Java:
@Anno
int x; // аннотация фиг знает на чёмЯ занимался поддержкой type-аннотаций в Java. Это лютейший ад. Осталось ещё много багов. А главное как ни сделаешь, всё равно недовольные найдутся, потому что это сломано изначально.
Парсеру скорее всего не сложно. Человеку лучше видно. Сплошной поток цифробуквенных токенов тяжелее читать, нет визуальной отбивки.
У меня за плечами большое количество языков
У меня тоже немало. Для меня var: Type легче читать, чем Type var, несмотря на то, что я пишу в основном на C++.
Допустим, при копировании/мёрже/другим причинам, в нашем коде на stylus похерились отступы. Вы сможете, глядя на код, сказать, что будет на выходе?
body
font: 14px/1.5 Helvetica, arial, sans-serif;
#logo
border-radius: 5px;
.foo
color: redВот и онлайн-компилятор не смог. Причём, меняя отступ, код то появляется, то снова ломается парсер. Например, вот такой код
body
font: 14px/1.5 Helvetica, arial, sans-serif;
#logo
border-radius: 5px;
.foo
color: redКомпилируется в такой css
body {
font: 14px/1.5 Helvetica, arial, sans-serif;
}
#logo {
border-radius: 5px;
}
.foo {
color: #f00;
}Поэтому крупные компании его выбирают? Сложно диагностировать проблемы -> больше времени можно списать на решение проблем, которые в других языках в принципе не возникли бы? Ведь были бы скобки обязательными, код бы мог быть воспринят только однозначно.
Есть некая грань, начиная с которой уменьшение "мусорных" символов ухудшает ситуацию, а не улучшает. Stylus как по мне — отличный пример этого.
Как эти инструменты относятся к неоднозначности синтаксиса языка? Ну вот выровнял я код автоматом по отступам (при коммите, например). Но, получил вместо того, что я хотел:
body
font: 14px/1.5 Helvetica, arial, sans-serif;
#logo
border-radius: 5px;
.foo
color: redВот это:
body
font: 14px / 1.5 Helvetica, arial, sans-serif;
#logo
border-radius: 5px;
.foo
color: redА потом трачу время на выяснение причин, почему поехала вёрстка. В чём же плюс такого языка? Символы пишутся быстро, а вот такие глупые ошибки стоят порой дорого.
Вы уходите от ответа, (вопрос был: в чём плюс языка с раздолбайским синтаксисом, если из-за этого синтаксиса могут внезапно вылезти ошибки) и начинаете переходить на личности. Да, у нас запрещёны под страхом увольнения с позорной записью в трудовую и линтеры, и код ревью. Это хотите услышать?
Ещё раз, простая ситуация: я написал стили, проверил, что всё работает как задумано. У меня по какой-то причине (случайно нажал пробел) перед коммитом добавились лишние пробелы в stylus-код. Код при коммите отформатировался автоматом ([sarcasm]хоть у меня на проекте это и запрещено, но я смелый[/sarcasm]), но не так как я задумывал, так что в плане стиля кода всё ок. Так что
- У вас не примут коммит, если вы не придерживаетесь правил форматирования и оформления кода
Мимо. Ревью кода проверяет не правильность выполнения задачи (ждя этого есть тестировщики), а именно правильность написания кода. Зачем вы упомянули методологии и бем, вообще не понял.
Далее, код попал в систему сборки. Она тоже ничего не нашла, ведь код пришёл отформатированный, соответствующий всем настройкам линтера. Так что пункт 2 тоже пройдёт мимо.
Проект собрался, тестировщики заняты. В проект накидали уже много других коммитов, в сборках уже будет трудно найти косяк (да и как это поможет), но кривые стили всё ещё лежат, готовые выстрелить.
И вся эта проблема только из-за вседозволенности синтаксиса stylus, ведь лишний пробел перед селектором в сочетании с форматтером кода неявно и создал такой баг, которого в других языках с ужасными скобочками вообще бы не было.
Если честно не сильно понимаю чем "нажал пробел случайно перед коммитом" отличается от "случайно нажал точку с запяток после цикла перед коммитом". И то и то просто не происходит в реальности.
Скопировать же текст из непонятного источника с непонятным форматированием — неужели у вас правда такие проблеым возникают? Код на том же SO всегда отформатирован, даже если вы просто копипастите его то вам достаточно выделить кусок кода и нажать там (шифт таб) нужное количество раз чтобы поставить его на место.
Наконец, некоторые проблемы могут быть действительно из-за динамической природы языка (ваши стили вряд ли компилируются). Но если например такой подход применяется в компилирующемся языке то почти всегда у вас будет ошибка компиляции. Haskell/Scala3 и некоторые другие делают именно так.
Как раз переход Scala3 на бесскобочную запись вызван тем, что там проще читать код. в сколько-нибудь приличной компании в 100% случаевкод отформатирован и так, тогда зачем писать скобочки? Вот и оказывается, что незачем. Так же и точки с запятой по большому счету не нужны, в 2021 году слава богу люди соблюдают правило "1 действие на строку" (кроме мб сишников). И смысла точки с запятой чтобы можно было писать i++; j++; в одной строке нет — так никто не пишет.
И вся эта проблема только из-за вседозволенности синтаксиса stylus, ведь лишний пробел перед селектором в сочетании с форматтером кода неявно и создал такой баг, которого в других языках с ужасными скобочками вообще бы не было.
А в языке со скобочками можно случайно не там скобки поставить и тоже не будет работать. Это ведь ошибки одного порядка.
Скобочки "не там" нужно 2 поставить.
Хотя честно говоря я месяц назад при мердже вместо того, чтобы грохнуть лишнее начало цикла вставил лишний конец. Потом удивлялся.
Ну и я не представляю как вы ребята копипастой занимаетесь между разными уровнями. IDE разбирается?
Скобочки "не там" нужно 2 поставить.
Уже давно IDE закрывающую скобку сама автоматически ставит например. Так что не надо.
Ну и я не представляю как вы ребята копипастой занимаетесь между разными уровнями. IDE разбирается?
tab/shift + tab для выравнивания на нужный уровень. А внутри сниппета код отформатирован в 100% случаев. А достаточно умная IDE да, сама разбирается, когда у неё есть текст которй вставляетяся по позиции N то она все строки сниппета сдвигает на эти же N.
Я случайно нажал таб в начале строки — она сдвинулась и теперь выполняется иначе
Я случайно нажал открывающую скобку в начала строки — она появилась вместе с закрывающей, это пустой блок, пусть выполняется сколько хочет, программе от него ни тепло ни холодно.
для изменения логики программы из-за "лишнего таба" есть тесты
а автоматически закрывающие скобки можно отключить в нормальных IDE
Но скобку же просто видно глазами, а лишний таб/пробел — обычно не очень.
скобка менее заметна чем лишний отступ
Сомнительно. Скобку видно сразу, а 12 там пробелов или 13 на глаз врядли сразу сходу можно заметить.
Откуда у вас 13 пробелов возьмутся? По-вашему отступы пробелами в каком-нибудь виме руками набивают?
Извините, я не понял ваш вопрос.
12 пробелов — это третий уровень при 4 пробелах на уровень. Случайно нажать пробел не в том месте — и его врядли сразу заметят.
Ну вот поставил я пробел не в том месте: https://rextester.com/XALAV6976
Получаю ошибку:
1632113399/source.hs:5:4: error:
parse error on input ‘let’Каким образом я её случайно не замечу?
Я случайно нажал открывающую скобку в начала строки — она появилась вместе с закрывающей, это пустой блок, пусть выполняется сколько хочет, программе от него ни тепло ни холодно.
то есть вот это
while (cond)
foo();совсем не сломается если записать так
while (cond) {}
foo();?
Ну если человек не помещает блок в блочные скобки, то он стреляет себе в ногу заранее.
И от чего ему будет больно раньше — от пустого блока скобок или от второй строчки после Foo(); и забытых скобках — почти без разницы.
В вашем примере кстати ему разве не подчеркнет лишние две скобки с предложением вставить пропущенную точку с запятой?
почему в крупных компаниях очень любят stylus
Разве он не вымер? Мне кажется его доля на рынке в районе нуля. Хотя судя по Google Trends он ещё чуть-чуть барахтается.
Чем больше я занимаюсь компиляторами, тем меньше у меня уверенность, что можно что-то просто и безопасно выкинуть из грамматики.
И языки с постфиксными типами выглядят более консистентно. А с префиксными типами всегда выходят костыли.
А меня наоборот ломает когда тип в конце. Когда я читаю код (а читать его приходится чаще чем писать даже если это твой код) мне важнее тип переменной чем её имя. Это настраивает на понимание того что там дальше.
Как я читаю Java:
переменной целого типа по имени N присвоить результат выражения;Как приходится читать Kotlin:
переменная N ...ХРЕНАКС!!!ТИП!!!... блин, чо там было-то?...С функциями ещё хуже. Задалбывает искать возвращаемый тип когда много аргументов. Самое главное - то что функция вернёт, а уж потом список аргументов. Мы же идёт от цели к способу её достижения. Значит возвращаемое значение - самое главное и оно должно быть в начале! Тут модификаторы немного портят малину, но это "стандартные слова", в них мозг не "вчитывается", а берёт целиком.
С написанием то же самое: "так, мне нужен метод, который вернёт Стринг, а из чего он его сделает - а вот из этого".
Хороший пример - перечень элементов. Надо писать сначала существительное, определяющее элемент, а потом всё остальное:
Конденсатор электролитический, ...
Так, имея длинную простыню текста, очень быстро выхватываешь взглядом то что нужно, а потом вчитываешься в детали.
Ну, можно возвращать Object или интерфейс, или дженерик. Возможно, в других языках можно ещё как-то извернуться. Но в любом случае, конструируя функцию, я сначала думаю что она делает. Делает => Возвращает => Что возвращает? Какой тип?
И этот ход мысли ломает объявление типа где-то там, в подвале.
Ну даже с переменными. Сначала объявляем, потом присваиваем. Т.е.:
"Мне нужна переменная, ага... А посчитаем мы её так..."
Можно и так записать: 1 + 2 = int n; (наверно где-то можно). Но это будет ломать принцип "сначала цель <== (потом средства)"
У вас, простите, какая-то каша в голове. Для начала попробуйте разбить эту стену текста на отдельные утверждения, хотя бы для себя.
Проблема многих языков это лишний символы, которые надо печатать, например begin end вместо {}, и присвоение переменной через <= или +=, $ перед переменной(в шаблонах это нормально), даже с автодополнением на это тратиться много времени.
Java: extends/implements вместо простого ":", ага.
Тут у меня сразу вспоминается дико не удобный objective c, с которым Apple хотела поменять отношение к программированию
Т.е. это одна из первых попыток скрестить С и ООП. Apple его взяли как готовое решение.
Скорее всего котлин был выплюнут на рынок в связи с судебной баталией Оракла и Гугла по поводу JAVA, и нужна была альтернатива для Android.
Google LLC v. Oracle America, Inc.: Prior Oracle Am., Inc. v. Google Inc., 872 F. Supp. 2d 974 (N.D. Cal. 2012);
Kotlin (programming language): First appeared July 22, 2011
человека учат математике и тип всегда слева, и переменной значение присваивают через знак =
В школьной математике типы вообще не пишутся. Это так, к слову. Порядок присваивания тоже никто не менял. А тип слева — наследие семейства С/С++, которое ещё и усложняет парсер и грамматику. Если вы пройдётесь по современным языкам, у большинства аннотации типов именно справа.
мог переплюнуть своей выразительностью C, C++, JAVA, Python
Выразительность языка — грубо, отношение "количества смысла" в вашем коде к количеству этого самого кода.
Python
Дискутировать не буду т.к. питон использовал крайне мало и давно. Но в целом могу согласиться, питон достаточно лаконичен.
Java
Выразительная? У меня сложилось несколько иное впечатление — для выражения простых концепций требуется очень много писать руками, и спасает от этого только автокомплит в IDE.
C
Насчёт С — это вы серьёзно? Он простой, но я бы не назвал выразительным язык без обобщённого программирования и многих других вещей.
C++
О да. Его пожалуй можно назвать выразительным. Но до появления С++20 обратной стороной этой "выразительности" были километры write-only шаблонного кода, порождавшие такие же километры ошибок.
Вообще же, довольно неплохо видно, что именно наличие сильного конкурента подстёгивает развитие. Активное развитие Java пошло именно в последние годы, когда у неё появился сильный конкурент Kotlin. Активное развитие С++ (выпуск нового стандарта каждые три года) началось, когда его начали активно заменять на другие языки во многих нишах, где С++ исконно доминировал.
Такое чувство, что вам не нравится язык только из-за типа справа. Но ведь это малая издержки крутой фичи с неизменяемыми переменными Val var.
почти каждая новая фича, которая появилась в Java недавно или вот-вот появится (в смысле, имеет активный JPE и обсуждается в рассылках) выглядит более продуманной, чем любая фича Kotlin.
Очень спорный аргумент. Новые фичи Kotlin также тщательно обсуждаются в рамках KEEP. А на счет "продуманности", скорее наоборот =). В существующий синтаксис Java сложно что-то добавлять, не ломая что уже есть. Посмотрите доклады Тагира (https://www.youtube.com/watch?v=qurG_J81_Cs) про то как встраивался pattern matching.
К тому же все, что появляется в Java никак не мешает Kotlin. Data class можно использовать с record. Как выйдет Valhalla то value классы тоже можно будет использовать.
Java будет и дальше развиваться, но языковые фичи (которых на самом деле не так и много) с трудом в нее попадают, а от улучшения jvm получают выгоду все jvm-языки.
Думаю, что в будущем Kotlin будет больше позиционироваться как Java 2.0, поддерживая все новые фичи, что появляются в Java и добавляя новый функционал поверх. Возможно в какой-то момент и настанет критическая точка что Java разойдется сильно с Kotlin, но ничего не мешает тогда появится Kotlin 2.0 c поддержкой миграции всего и вся из Kotlin 1.0. Kotlin ведь не Java, он может себе позволить куда более критичные изменения.
Использовать data class с аннотацией @JvmRecord имеет смысл только для interop, ИМХО, иначе это какое-то знатное извращение получается)
Kotlin ведь не Java, он может себе позволить куда более критичные изменения.
Ой, не уверен. Есть плохой пример Python 2 => 3, было больно и грязно. Golang упорно держится за версию 1.x, потому что понимает, что версии 2.x придётся отчаянно сражаться за аудиторию, и при этом останавливать работу над 1.x тоже нельзя.
Сейчас появился еще один пример, Scala 2 => 3. Можно посмотреть что у них получится и сделать правильные выводы =)
Есть плохой пример Python 2 => 3, было больно и грязно.
У меня сложилось впечатление, что проблема была скорее в интерпретируемой природе питона. Т.е. для плавного перехода требовалось, чтобы один интерпретатор понимал оба диалекта, умел различать файлы на разных диалектах в одной программе и умел их комбинировать. В случае с компилируемыми языками (в машинный или байткод) это тоже может быть болезненно, но не в такой степени. Если сильно припрёт, можно работать в сторону совместимости на уровне межмодульных бинарных интерфейсов. Тогда скомпилированные модули версий языка 1.х и 2.х вполне могут жить вместе. Пример этого — взаимодействие модулей одной программы, написанных на разных языках, через C ABI. Сложно, да. Но не неразрешимо. А в случае с питоном вы в принципе не могли бы скрестить в одном месте условную Django для 2.х и условный Numpy для 3.х.
Например, изрядное количество подробностей внутренней работы kotlinc скрыто внутри сгенерированных файлов классов, представляющих из себя аннотации @Metadata с бинарными данными (байтовыми массивами, разрешёнными в аннотациях) внутри. Насколько мне известно, эти данные не описаны ни в каких публичных спецификациях.
Кстати, их не то, чтобы совсем сложно распарсить. Это на самом деле protobuf, proto-файлы находятся в репозитории Kotlin. Их можно аккуратненько скопировать себе и сгенерировать код, который парсит данные. Там остаются кое-какие нюансы, которые можно узнать, почитав код компилятора Kotlin, но в целом задачу "прочитать метаданные Kotlin" я в своё время осилил.
мы увидим ну очень нескоро
Не знаю как вы, а я уже 2 года работаю на Android с Java 1.8, а в последнем обновлении Android Studio 4.2 подвезли Java 11
Но под капотом у вас все-равно используется API Java 6 (если только не используете minApi 26). Языковые фичи новой версии языка заменяются на этапе работы D8. Расширение "стандартной библиотеки" до восьмерки только через отдельные "костыли" от Гугла (ссылка)
Возможно. В работу D8 я не погружался. Я про то, что исхолный код пишу с использованием стандартов Java 8 (лямбдами, функциональным программированием и т.д.), а скоро начну использовать новшества Java 11. А то, какие костыли используются при компиляции мне не важно. У меня компиляция идет меньше 1 минуты.
Вставлю свои 5 копеек, почему Kotlin может быть хуже Java
Короче, мне, как разработчику, не слишком интересно, запишу я код метода в 3, 5 или 10 строк. Мне важно, как удобно со всем этим будет работать в связке с другими инструментами из экосистемы Java. И у Kotlin с этим, пусть всё и хорошо, но не на 100% безоблачно.
Первое упоминание об IR появилось году так в 2017-м, когда его запилили для нужд Kotlin Native. С тех пор команда плавно переписывает все бэкэнды на IR, параллельно этот самый IR допиливая. К тому времени, как Kotlin 1.5 будет с нами и как все бэкэнды окончательно переделают в IR, и когда этот IR стабилизируется и появится стабильное же API для работы с ним из плагинов, и всё это ещё аккуратно поддержат в IDEA, вот тогда и поговорим (сколько ещё ждать, год, два три?). Тогда я признаю, что одной проблемой в Kotlin меньше. А пока мы имеем дело с тем, с чем имеем, и пункты 1 и 2 заставляют меня не переходить на Kotlin в тех проектах, где эти пункты являются критичными.
Вообще в IDE все настраивается и с kapt.
Можно ссылку? Просто я с ходу не нашёл. А для IDEA вообще ничего не надо настраивать — она сама при импорте проекта из maven/gradle обнаруживает annotation processors и подключает их.
Есть inline, tailrec
Никогда не понимал смысла в оптимизации хвостовой рекурсии. Есть же нормальные циклы. Это, конечно, очень увлекательное упражнение для ума — переписать всякие map/filter/fold на чисто функциональном языке, где циклов нет и нет ленивых вычислений, так, чтобы они были tailrec. Ещё было в студенческие годы не менее увлекательно написать библиотеку функций на SK комбинаторах. Однако на практике я вообще не встречал ни единой ситуации, когда написать функцию с хвостовой рекурсией было бы более просто и наглядно, чем написать банальный цикл.
В IDEA нужно только включить "Enable annotation processing" и все должно работать точно также как в Java (так как механизм используется точно такой же). По крайней мере у себя я не помню, чтобы что-то дополнительно настраивал. Проект с gradle. Единственное что все gradle, kotlin и IDEA самые свежие. При запуске build запускается и annotation processing.
Для того, чтобы утвержать такое, надо вначале определиться, что мы называем ФП, потому что какого-то единого чёткого критерия нет. Если мы договоримся, что среди наших критериев есть ленивость, то да, с данным тезисом я соглашусь. Однако можно долго спорить, включать ли критерий ленивости в определение ФП. Всё-таки Ф — это про функции, а не про ленивость (иначе бы у нас был ЛП). А так получится, что только Haskell можно назвать полноценным ФП, а какие-нибудь OCaml или SML идут лесом.
либо к злоупотреблению lateinit, который может давать странные эффекты.
Да условному синьёру не сложно выучить Kotlin. Может, он его уже отлично знает. Просто оказывается так, что из-за ряда факторов Kotlin вместо того, чтобы увеличивать эффективность сеньёра, снижает её. Лично для себя я просто выделил кейсы, когда Kotlin помогает, а когда мешает, и использую или не использую его в конкретной ситуации, исходя из этого понимания. Речь о том, что Kotlin на данный момент не может покрыть 100% (или даже 90%) ситуаций, когда он был бы однозначно лУчшим выбором, чем Java.
Отвлекусь временно от комментирования, но хочу сказать, что приятно удивлён уровнем дискуссии. Спасибо всем, кто вносит свой вклад в создание многомерной картинки Kotlin-экосистемы!

Ах этот призрачный null-safe. В проекте java и kotlin, вместо NullPointerException начинаем получать в рантайме Fatal Exception : что-то must not be null.
А чем Fatal Exception: что-то must not be null в рантайме хуже NullPointerException (без подробностей) в рантайме?
У меня в синтетическим примере передача null в метод который не ожидал null в Kotlin даёт ошибку java.lang.NullPointerException: Parameter specified as non-null is null: method package.Class.method, parameter output и в ней видно и полное имя класса+метода и имя параметра.
В Java-же обращение к методам переменной, содержащей null, возвращают java.lang.NullPointerException без текста и только по трейсу можно узнать имя класса, метода и строку в исходниках — а переменную нужно угадывать самому. И только с JEP-358 включённого в Java 14 будет писаться имя null-переменной.
включённого в Java 14 будет писаться
Не будет писаться, а уже пишется! Java 14 больше года назад вышла =)
Да, "уже".
Только в проде обычно используются LTS-версии и хорошо если там вообще Java 11, а не Java 1.8.
И в андройде есть только 1.8.
И исходный вопрос был про то что "так ли один райнтайм эксепшн хуже другого рантайм эксепшна?".
Удивительно, почему людям трудно затащить новую версию языка, но легко затащить новый язык. Ну про Андроид не говорим.
Кстати, у JetBrains есть инструментатор для NotNull-аннотаций, который тоже делает более понятные сообщения типа "java.lang.IllegalArgumentException: Argument 1 for NotNull parameter of Scratch.test must not be null".
Удивительно, почему людям трудно затащить новую версию языка, но легко затащить новый язык.
Потому что иногда тяжело прогнуть бизнес на изменение версии JVM на проде, тогда как код на Kotlin компилируется под 1.8 со рассматриваемыми фичами.
Ну про Андроид не говорим.
Потому что там именно такой вариант?
По поводу Google vs. Oracle, насколько я понимаю выиграл Google.
Если теперь Android получит полную поддержку текущего Java API (11 или новее), то будет ли смысл писать Android приложения на Kotlin в будущем? Выбор Kotlin для Google возможно был отходным путем, если бы они проиграли суд.
Распространение Kotlin за пределами Android (и самой JetBrains) под большим вопросом, не очень понятно, например, зачем backend разрабы станут тянуть еще одну технологию в проект, когда преимущества не очевидны.
Ради эксперимента, два года назад я попробовал ktor.io и SQL Exposed для небольшого проекта на бекенде и не увидел ощутимых плюсов. Наоборот, из-за того, что фреймворк тогда еще активно развивался каждая попытка обновиться до новой версии ломала проект, Exposed тоже был очень сырой. Плюс как разработчик я бы писал код быстрее и качественнее на более знакомой Java. Хоть проект и закончил, но желания использовать ktor где-то еще больше не возникало.
Кросс-платформенный Kotlin тоже не ясно для кого пока. Как-будто слишком много конкурентов.
Возможно кто-нибудь помнит, как Google позиционировал Dart когда они только запустились? Насколько я помню звучало это как похороны JavaScript. Но как в последствии мы увидели, JavaScript даже не заметил Dart и за пределами Google (возможно и внутри) язык не получил распространения до того момента пока не запустился Flutter. Возможно тоже как путь отхода от Google vs. Oracle. И будущее Flutter тоже не очевидно.
Поэтому ощущение будто Kotlin останется языком для разработки JetBrains и возможно Android, до тех пор пока Android не решит поддержать последние версии Java.
На мой взгляд, сейчас единственным драйвером распространения Kotlin является Android и если Google вдруг решит, что теперь Android first язык и Java тоже, то прирост новых разрабов будет сокращаться.
Я согласен с выводами в статье и еще бы добавил, что один из вариантов развития это искать партнерство с какими-нибудь крупными компаниями (возможно даже университетами) кроме Google.
Update: помните как Scala была на волне популярности, а потом ее вообще перестало быть слышно? Правильно ли будет сказать, что с добавлением в Java 8 возможности писать функциональный код, Scala как-будто начала отмирать.
Ставку на Dart в 2012-2013 году делали большую. Даже добавили в Chromium mode в котором можно было писать на Dart нативно, без компиляции в JavaScript. Я даже не очень помню, была она с самого начала или ее добавили потом. И еще обещали включить поддержку в релизную версию Chrome (разве не звучит как заявка на похороны JavaScript? =D). Но этого не произошло и они даже сделали официальное заявление, что поддеркжи Dart в браузере не будет.
По наивности тогда мне казалось, кто если не Google, но по факту они воскресили Dart только с вместе Flutter.
У вас на картинке Джава и Котлин подписаны наоборот: Джава же более древняя, а Котлин — молодёжь.
Так это, все манипуляции с null сделаны с одной целью: проверки на null в compile time при условии, что идёт работа котлина с котлином. Ни о каком null safe вообще везде речи и не идёт. Поэтому да, если у вас проект на джаве, то у вас будут проблемы с null в тот момент, когда вы начнёте добавлять котлин. Со временем же, когда нового кода на котлине станет больше, проверки уже будут выполняться в compile time, в этом и основной смысл. Насчёт JNI/JNA чутка не понял. Если код для того же JNI уже написан на джаве, то получаем взаимодействие котлина с джавой, если на котлине, то получаем взаимодействие котлина с котлином, тем самым сводя ситуацию к ситуации с исходным интеропом
В моем понимании проверки во время компиляции заканчиваются тогда, когда возможность возврата нулл зависит от внешних данных в рантайме. То есть, эта задача в общем виде при компиляции не решается. О чем я в общем и написал.
Да, всё так. Я лишь привёл пример, когда "эта фича котлина даёт что-то полезное" - при работе котлина с котлином (ещё есть работа котлина с аннотированный джава, но тут уже польза чуть более субъективна)
Ну скала из той же жвм корзинки, но при этом система типов у нее +- уровень хаскеля (причем в каких-то вещах даже мощнее)
И никаким способом мы при компиляции это не проверим вообще
Неправда. Джаву можно помечать всяческими @Nonnull/Nullable, и это прорастает в котлин.
Вы правда не видите разницы между проверить автоматически и попросить программиста поставить аннотацию?
@NonNull
private String foo() {
return null;
}
@NonNull private String foo() { return null; }
а) не аннотированы, и никогда не будут б) тоже умееют возвращает нуллы.Прекрасно, в котлине они видны как platform type («String!», например), вы можете проверять их на null, и дальше компилятор будет понимать, что тип нуллабельный. Никакой проблемы в этом нет.
Идейка поддерживает внешние аннотации в xml-файлах. Котлин их тоже поддерживает. В принципе можно аннотировать сторонние библиотеки из интерфейса IDE и шарить аннотации вместе с проектом. Мы в исходниках IntelliJ IDEA этим пользуемся. Внешние аннотации для JDK поставляются с самой IntelliJ IDEA.
Кстати, перестановка местами типа и имени переменной… не кажутся хорошими идеями.
Это скорее не то, чтобы прекрасная идея, это back to roots. Потому что в своё время странная идея "а давайте писать тип переменной перед её именем" под влиянием языка, который (по другим причинам, а не из-за этой идеи) стал популярным, пошла в массы. Кажется, до народа дошло, и новые языки как раз возвращаются к нотации, появившейся чуть ли не раньше компьютеров (например Kotlin, TypeScript, Rust, Swift).
Как так, мы столько сил вложили в изучение джавы, стали синьорами, а нам тут говорят, что какой-то котлин лучше, чем наша дорогая джава?
Синьоры стали синьорами не потому, что все свои 10-15 лет в индустрии потратили на изучение синтаксиса и идиом конкретно взятого языка. Они изучали такие вещи как:
Что приходится из этого проапдейтить при переходе с Java на Kotlin? Синтаксис. Ну может пару библиотек специально для Kotlin написанных посмотреть (ktor, exposed). Ну может научиться подключать модули к Spring, которые нужны для облегчения жизни Kotlin-истам. Ну просмотреть быстренько стандартную библиотеку Kotlin, увидеть, что она почти один-в-один является подмножеством стандартной библиотеки Java, плюс несколько расхождений (Sequence вместо Stream), плюс горстка удобств. Ну какие-то идиомы, которых нет в Java. Профайлеры те же. Отладчик тот же. Maven и Gradle те же. Поверьте, человеку с опытом в 10-15 лет в отрасли, всё указанное не так долго изучить. Вот перейти с Java на C++ или с Java на Python сложно. С Java на Haskell ещё сложнее.
Data-объекты могут быть заменены более богатым функционалом record
Пожалуйста, чуть-чуть полегче. Тут такая джентльменская дискуссия, не испортите её.
Невозможность наследования и добавления instance-переменных я считаю плюсом records, благодаря этому они больше отвечают семантике "я строка в базе данных/элемент в очереди". Употребить слово "богатый" наверное было неправильно, скорее "строгий".
благодаря этому они больше отвечают семантике "я строка в базе данных/элемент в очереди".
ИМХО, data классы и record-ы совсем не для этого были созданы. Как раз для строк в БД очень редко нужна специфическая семантика equals. Лично я считаю, что data class нужны ровно в двух ситуациях:
Собственно, поэтому мне на практике приходилось использовать data class-ы ОЧЕНЬ редко. Не понимаю, почему все бездумно лепят модификатор data на всякие DTO и entity (особенно на DTO)? Потому что есть ассоциация "данные == data"?
Дебажить print'ом удобно :)
Собственно, поэтому мне на практике приходилось использовать data class-ы ОЧЕНЬ редко.
Объявить иммутабельные штуки
Мутабельные данные — отличный способ отстрелить себе задницу, ящитаю.
Ахаха, вы это скажите сотрудникам Kotlin team, которые ловеринги пишут не путём "я пересоздам все IR элементы от рута до текущего элемента", а путём старого доброго изменения мутабельного свойства. Думаете, они там дураки сидят, которые не знают всех преимуществ иммутабельных данных и не могут в ФП? Боюсь, если бы они делали IR иммутабельным, kotlinc работал ещё раз в 100 дольше, чем он работает сейчас.
Ну а раз в любом случае это будет POJO с final-полями, то отчего бы не обмазать его префиксом data и не получить сахарок в виде copy-метода?
Так если это иммутабельный класс, то бога ради. Я просто вижу, как на вполне мутабельных расставляют. Впрочем, в Kotlin не всё так хорошо с иммутабельностью. Вот вам маленькая задачка от меня. Что выведет следующий код?
fun main() {
val trollList = mutableListOf(1)
val a = A(foo = trollList)
val s = mutableSetOf(a)
trollList += 2
s -= a
println(s)
}
data class A(val foo: List<Int>)Думаете, они там дураки сидят,
Что выведет следующий код?
Не знаю насчет правильного аргумента. Видел много раз, когда челове которого прям "штырит" от плюсов начинает на нем писать типичный круд, и потом ты сидишь разгребаешь: что POST не работает (потому что тащящийся от плюсов разраб смог реализовать только GET), зато все данные можно передавать мегабайтными урлами. От чего сносит крышу уже nginx и некоторым либам, которые читали стандарты и знают, что урл не должен быть длиннее 16кб. Ну и так далее.
Если человеку нравятся микроскопы, забивать ими гвозди все же не стоит наверное
Я для себя выбор сделал. После 18 лет разработки на Java перешел на Kotlin — и очень этим доволен. Джаву хорошо знаю, люблю и уважаю, но вряд ли к ней когда нибудь вернусь. Для меня это пройденный этап.
Категорично, меньше не скажешь. То есть, лагерь разработчиков разделяется, одни не перейдут на Kotlin потому, что тонна legacy и никто не хочет, другие не перейдут на Java, потому что им не нравится. Ну я понимаю, когда люди переписывают с С++ на Java и наоборот… Но чисто по человечески это даже не .NET и JVM, это по сути одна кодовая база и, вряд ли, Kotlin ее когда-то всерьез изменит, зато 2 воинствующих лагеря "отцы-и-дети" ...
.Companion., или getInstance() для object'а, или ИмяФайлаKt для top-level деклараций. К слову, зачем в принципе нужен companion object вместо static'ов мне абсолютно неясно. Он не решает никаких проблем (разве что жёстко отделяет статическую часть от нестатической? Это можно и в Джаве добровольно сделать если хочется). Так как котлин дублирует довольно большую часть стандартной библиотеки Джавы, иногда приходится типы вроде Sequence превращать во что-то, что ожидают Java-библиотеки, и наоборот.if (var !== null), когда переменная внутри if'а не меняется, но зато меняется после. Приходится расставлять везде !!, что делает код намного менее лаконичным.a?b:c, в котлине мне приходится писать if(a) b else c в самой короткой записи. Мелочь, а очень бесило, особенно для языка который хочет быть лаконичным и коротким.я один из (наверное) немногих кто перешёл обратно на Джаву и потихоньку переписывает уже написанное на неё.
Интересно, вы это вручную делаете или какие-то инструменты есть, которые преобразуют Котлин в Джаву?
Постоянно что-то ломается с каждым новым релизом Java или IDEA.
С этим должно стать лучше буквально со следующего релиза. Котлин-плагин затащили в репозиторий IntelliJ IDEA, соответственно он обновляться будет синхронно с основным кодом, интегрироваться только с конкретной версией Идеи, с которой поставляется, что упрощает разработку и тестирование. Ну и синхронные изменения в платформе и плагине делать проще будет. Плюс разработчики из Идеи будут чаще что-то исправлять в Котлин-плагине, если есть необходимость (например, чтобы избавиться от небезопасных устаревших вызовов). В общем, светлое будущее впереди :-)
Последние пять лет Котлин-плагин не затаскивали в репозиторий IDEA. Поэтому вы не могли слышать подобных заявлений.
if (var !== null), когда переменная внутри if'а не меняется, но зато меняется после. Приходится расставлять везде !!, что делает код намного менее лаконичным
Подобные проблемы бывают из-за того, что человек не поменял свой взгляд на написание кода. Более идиоматично писать такие конструкции как
var?.let { ... }Ну и на помощь приходят всякие takeIf, also, apply. Но иногда они привносят больше сложности в понимании, тут важно не перестараться.
Тут не всё так просто. Представим ситуацию, что у нам многонитевое приложение на джаве
class Main {
private static volatile String password = "1234";
public static void main(String[] args) throws Exception {
new Thread() {
public void run() {
password = null;
}
}.start();
if (password != null) {
Thread.sleep(100);
System.out.println("Password: " + password);
} else {
System.out.println("Password is not defined");
}
}
}Получается, что нельзя полностью определить, будет ли в этот момент переменная с нуль-значением или нет, так как между проверкой и использованием в другом потоке может случится изменение переменной. Поэтому либо в локальную переменную копировать по ссылке, либо использовать ?.let
!! приводит к ошибке компиляции, хотя не должно:class Test {
val v = if (ThreadLocalRandom.current().nextBoolean()) ClassWithInvoke() else null
fun test() {
var x: String? = null
if (v !== null) {
x = v!!()
}
println(x)
}
}
class ClassWithInvoke() {
operator fun invoke(): String = "..."
}
!!?)Забавный пример с instanceof. Мне джавовский вариант кажется крайне странным, не соответствующим ожидаемому поведению. Хочется как минимум видеть при таком синтаксисе другое имя оператора.
Есть о чем задуматься конечно. Вместе с тем, «стратегия как Java, только лучше» будет ещё долго в силе, как минимум потому что большинство проектов и людей ещё работают на Java 8. Если представить сколько времени уйдёт на переход на версии Java 16+, то у Котлина еще много времени на манёвр.
Кажется, дотнет становится всё более привлекательным синтаксически
А вот то, что .Net Core теперь опен сорс и перформанс уже намного лучше стандартного джава стэка это факт.
Прикольно! А как меряли?
Даже aspcore-mvc-ef-pg раз в 5 быстрее спринга.
Поделитесь линком на замеры?
Отличный пример, спасибо!
Для тех, кому любопытно, что тестируется и как замеряли.
Сделано веб приложение, которое вытаскивает все записи из таблицы (записей 12, но коду запрещено об этом заранее знать) и кладёт в лист. Потом в лист кладут ещё один объект и дальше лист сортируется по одному из полей. Сортировки в запросе заранее нет.
Далее этот лист скармливается шаблонизатору, который делает из объектов html таблицу из 13 строк.
Вот на этом сценации spring обрабатывает 23 тысячи запросов в секунду, а aspcore 105 тысяч. Спринг никто не тюнил, единственное, что расширили пул коннекшнов к БД до 2 * количество ядер. aspcore наверное тоже никто не тюнил, но специально это не оговорено.
Что интересно, если не ограничивать тесты спрингом, то джава работает быстрее, чем любой вариант C#, поэтому можно предположить, что дело действительно в каком-то из компонентов спринга.
Также, если измерять сценарий в котором каждый http запрос приводит к появлению нескольких запросов к БД, spring быстрее чем aspcore раза в 2, а если измерять только сериализацию в json, то aspcore быстрее spring раз в 10.
Также, если измерять сценарий в котором каждый http запрос приводит к появлению нескольких запросов к БД, spring быстрее чем aspcore раза в 2, а если измерять только сериализацию в json, то aspcore быстрее spring раз в 10.
спринг никогда не был эталоном производительности
if (value instanceof String stringValue) {
// код со stringValue
processString(stringValue);
}
if (value is String) {
// работаем с value как со строкой
processString(value);
}
В джаве первоначальной переменной может не быть, либо это может быть изменяемое поле. В целом без разницы каков источник выражения слева от instanceof. В Котлине это работает только в ограниченном наборе случаев когда исходная переменная локальная или неизменяемое проперти. Люди постоянно на это напарываются и раздражаются, сам видел таких. Подход в джаве более последовательный.
getValue().let { value ->
if (value is String) {
processString(value)
}
}
Эти всякие let — это ужасно. Код превращается в лапшу.
не нравится let, есть простое как дверь решение: разнести объявление переменной и проверку типа
val value = calcValue()
if (values is String) {
processString(value)
}Или на Java:
if (calcValue() instanceof String value) {
processString(value);
}90% случаев проверки существующей переменной у вас только если у вас нет синтаксиса как в джаве :)
Я тоже так думал (я шарпист, правда, но там 1 в 1 джава, только кейворд is покороче чем instanceof), а потом начал пользоваться и как раз удобно что мусорное значение не засоряет скоуп. Ну вот например:

Обратите внимание на 55 строчку. Там логика "вызвали метод, если вернулся нулл то ретурн нулл сразу, иначе вот у нас есть переменная с каким-то значением". Вопрос — зачем мне мусорное значение которое вернула TryGetInitWithValue(type) в скоупе?
Модифицировать оригинальное значение (типа навесить знание что "оно не нулл") не всегда можно, см. например 61 строчку, где происходит сразу деконструкция, а держать переменную под тапл не особо удобно.
Хороший пример просто, что вот никаких 90% с проверкой существующей переменной (когда у вас есть выбор) нет. Когда выбора нет — тогда другое дело, конечно, тогда я думаю процент даже не 90 а 100 :)
Там логика «вызвали метод, если вернулся нулл то ретурн нулл сразу, иначе вот у нас есть переменная с каким-то значением». Вопрос — зачем мне мусорное значение которое вернула TryGetInitWithValue(type) в скоупе?
(calcValue() as? RequiredType)?.also { value ->
//в этом скопе (и только в нем) есть value типа RequiredType
}
Хороший пример просто, что вот никаких 90% с проверкой существующей переменной (когда у вас есть выбор) нет. Когда выбора нет — тогда другое дело, конечно, тогда я думаю процент даже не 90 а 100 :)
fun addValue(value: Any) {
if (value is ListenableValue) {
value.onAdd(this) // onAdd есть у типа ListenableValue
}
set.add(value)
}
if (calcValue() instanceof String value) {
processString(value);
}when(val v = calcValue()) {
is String -> processString(v)
}when(val v = calcValue()) {
is String -> processString(v)
42 -> prosess42()
is Int -> processInt(v)
else -> processElse(v)
}В Java 17 обещают завезти:
switch(calcValue()) {
case String str -> processString(str);
case 42 -> process42();
case Integer i -> processInt(i);
case Object other -> processElse(other);
}Очень круто, что можно будет дать говорящее имя переменной в каждой ветке, а не использовать везде абстрактное v.
Так они не плодятся — у них скоуп свой маленький. Не говоря про то, что у вас это естественным образом расширяется до рекурсивных паттернов, скажем, с таплами:
var v = (calcValue(), calcValue2()) switch {
(String s1, String s2) => processString(s1, s2),
(SmthN smth1, SmthN smth2) => processSmthN (smth1, smth2),
(se1, se2) => processElse(se1, se2)
}Мы сейчас говорим про "Java vs Kotlin", оба — жвм языки. Я C# беру просто как пример, на котором можно показать что синтаксис джавы может дальше развиваться в сторону рекурсивных паттернов и они все будут естественным образом встраиваться в существующий (x instanceof Foo y). А дальше рассуждения на тему, что синтаксис котлина подобным образом расширить не выйдет и придется выдумывать что-то совсем иное.
Я в первую очередь смотрю на ортогональность фичей, и то что зная фичу Х и Y я могу легко их скомбинировать в XY. В данном случае у джавы потенциал в этом плане выше имхо.
Ну в шарпе это точно так же щас делатся:
var v = calcValue() switch {
String s => processString(s),
SomethingN smth => processSomethingN(smth),
somethingElse => processElse(somethingElse)
}И кмк то что в каждой ветке своя переменная со своим типом воспринимается проще. Думаю в джаве так же сделают.
Придумывать еще одни имена для уже имеющихся переменных такое себе =)
В идеале бы, сделать чтобы был возможен и тот и другой вариант.
Например, можно было бы в Kotlin поддеражать такое:
if (value is v: String) {
processString(v);
}Или можно сделать чтобы переменная неявно создавалась бы, если нужно (ну или явно, но опять же автоматом):
if (value is String) {
// smart casting value to String, and if value is mutable, it saving to new variable
processString(value);
}when(val x = someValue) {
is String -> //use x as String
is Int -> //use x as Int
else -> //do something else
Прикольно, конечно, пример искусственый. Если где-то появляется портяночка if на instanceof, значит, кто-то где-то не освоил ООП — 99% случаев.
sealed class Result {
data class Ok(val data: SomeData): Result()
data class VerificationFailed(reason: SomeReason): Result()
data class UnknownError(exception: Exception): Result()
}
...
when(val result = getResult()) {
is Result.Ok -> printData(result.data)
is Result.VerificationFailed -> printReason(result.reason)
is Result.UnknownError -> printStackTrace(result.exception)
}
Нет, нормальный пример.
В Java 17 завезут это (в порядке preview-feature)
https://openjdk.java.net/jeps/406
We expect that, in the future, general classes will be able to declare deconstruction patterns to specify how they can be matched against. Such deconstruction patterns can be used with a pattern switch to yield very succinct code.
То есть рекурсивные паттерны как раз затащат (Как в примере с шарпом ниже). Прикольно, спасибо
Возьмем сишарп:
if (GetUser() is User user) { ... }или даже:
if (GetUser() is User {Name: "Alex"} user) { ... }Вроде просто и понятно. А на котлине как?
GetUser().also { user ->
if (user is User) {
//....
}
}
(GetUser() as? User)?.also { user ->
//....
}
Спасибо за статью. На самом деле не понимаю хайпа вокруг Kotlin. Если IDE от JetBrains ещё в определённых рамках обоснованно, то с Kotlin... JetBrains прекрасно показали на сколько они качественно могут поддерживать язык и его развитие на примере Nemerle.
Май 2021 года. Любой, кто никогда не имел дела с моб. программированием и ищет на чем бы написать новый проект с нуля, пройдет примерно такую цепочку: 1. Ну Java конечно для андройда, что ж еще. 2. Ой, вот какой-то Kotlin появился, и Google его в студии включил по умолчанию, серьезное что-то наверно. Но эти русские ребята отпугивают. Тем более, они еше и Idea делали, уж знамо что это, уже 10 лет пользуем... 3. Apple же еще! Ну там свифт наверно придется осилить с нуля.. 4. Xamarin, phonegap.. не, это будет тормозно и в никуда, как в 2010-х. 5. Flutter! Dart! Че за...? И через месяц у вас реальный проект уже в сторах продается обоих. (реальная история) Это если вы гугл поисковиком пользуетесь, он вам в таком порядке будет питчить. Поэтому перспектива у котлина плачевная.
Как всегда, все приведенные аргументы мелкие и несерьезные: у нас есть фича A, а у вас ее нет, либо она хуже и вообще плохая. Я тоже писал проекты на Kotlin, но до сих пор предпочитаю Java, и вот почему:
Реально же проекты, где необходима мультиплатформенность с единой кодовой базой, в природе не встречаются.
Ну почему же. Вот, например. Правда, кросплатформенность и без Kotlin бывает, на обычной Java. Для iOS был MOE, а сейчас GraalVM. На Android и на сервере нативно работает. На web — TeaVM. Правда, на сервере не надо запускать весь код клиента, достаточно только части, отвечающей за OT.
Очень интрузивное и тяжелое изменение, которое заставляет код выполняться совсем не так, как написано, разрезая сверху до самого основания ваш код на suspendable и не-suspendable. Loom гораздо более элегантен и прозрачен.
Думаю, некорректно сравнивать корутины и Loom. Корутины — это языковой механизм, который позволяет в том числе на уровне языка легко запилить аналог Loom. Но не обязательно их для этого использовать. Например, с их помощью можно делать генераторы последовательностей.
Ну почему же. Вот, например.
Игрался я с вашей TeaVM — вы маньяк каких мало (в хорошем смысле слова). Я в свое время активно юзал GWT, сейчас для энтерпрайз тулзов использую Vaadin. Однако сейчас в большинстве случаев типичный проект — это разные команды и разные кодовые базы для каждой платформы, плюс сервер. Во всей компании все, кто знают котлин, лабают исключительно под андроид, и абсолютно не секут в веб-фронтэнде ни в бэкэнде. Бэкендеры сидян на джаве и пайтоне. И ни один веб-фронтэндер, тоже не знает котлина (и не собирается). Вот такое разделение труда.
Не холивара ради, а интереса для. В этом топике не вы первый высказываете мнение, что nullability в Kotlin это зло. Я на Kotlin не пишу, но много пишу на TS. И решительно не понимаю как можно рассматривать nullability как зло?! Это какой-то холиварный вопрос или оно просто в Kotlin-е сделано из рук вон плохо?
TS (strict=true) заставляет вас убедиться в том, что значение !== null, перед использованием. И если вы "мамой клянусь, тут не null" (у нас всё хитрее и есть ещё и undefined на самом деле, ну да не суть), то вы можете:
variable! (символ !). Но это часто запрещают линтером, дабы не повадно было срезать так углыif)?. или ?? (аналогичные вещи есть, скажем, в C#)Ну и предполагается что хорошо организовав типы в проекте, да и саму кодовую базу, вам не придётся регулярно упорно доказывать компилятору, что "да зуб даю, тут не null". Наш опыт показывает, что в ~10-15% случаев, когда программист думает "тут никогда не бывает null", он ошибается :) Поэтому мы предпочитаем assert guard, чтобы выловить ошибку в runtime на самой ранней стадии.
В Kotlin нет аналогов вышеописанному?
Интересно. В TS тоже можно записать null в not-nullable переменную (ибо под капотом JS):
let a: boolean = false;
a = null as unknown as true; // double type casting
// @ts-ignore
a = null; a = undefined; a = whatever;Но такое случайно не напишешь. Это прямо диверсия :)
Попробую объяснить. Лирическое отступление. Забудем сначала про null и зададимся вопросом что отличает языки со слабой типизацией от языков с сильной типизацией. В первых вывод типа происходит исключительно в рантайме. Во вторых же позволяют декларировать какой-то статичный контракт, подчиняющийся определенным правилам вывода, который может быть вычислим на этапе компиляции. Однако это не совсем не отменяет того, что в программе большинство типов остается вычислимо лишь в рантайме. Попытки внедрить и использовать более сильную систему типов (напр. ScalaZ), позволяющую иметь бОльший контроль на этапе компиляции, сталкиваются с проблемой, что описание типов для предметной области становится в разы сложнее, чем сама программа, и тем не менее все-равно будут появляться места, где тип вычислим лишь в рантайме. Поэтому важно сохранять некий баланс между контролем типов и простотой описания.
Теперь вернемся к нашим баранам. Java по дефолту не имеет способа объявить контракт по nullability, однако его все же можно по желанию дополнить аннотациями Nullable/@Nonnull, либо использованием Optional. Котлин же наоборот обязует для любого типа всегда использовать строгий контракт по поводу nullability без возможности послабления. Почему это плохо? Приведу пару демонстративных кейсов.
Функция, которая конвертирует объект в строку, причем для null-ов она должна возвращать null.
fun toString(a : Any?) : String? {
return a?.toString();
}Проблема в том, что она всегда обязана возвращать nullable String и обязует каждый раз делать проверку, даже когда поставляемый объект заведомо не null и описан в ситеме типов как не-null. Котлин не позволяет описать контракт "верни мне String? для Any? и String для Any", перегрузить функцию не получится — возникнет конфликт сигнатур.
fun toString(a : Any) : String /* Platform declaration clash */Очень ленивая инициализация. Для nonnull полей Kotlin требовал сразу указать дефолтное значение. Логично. Но практически сразу же разработчики столкнулись с диким баттхертом при интеграции с различными библиотеками (DI, JUnit, сериализация, etc...), где значение поля вычислялось и заполнялось отложенно. Пришлось включить попятную и добавить хак ввиде lateinit, дабы как-то это сделать юзабельным. Пример: есть JPA Entity с полем id, которое заполняется автоматически при персистенции объекта. Nullable я его не хочу делать, т.к. null там только на этапе конструирования.
@Entity
class MyEntity {
@Id @GeneratedValue
lateinit var id : Long
fun isPersisted() : Boolean {
return this::test.isInitialized
}
}И вот облом! Это не сработает, потому как при сохранении объекта JPA провайдер попытается прочитать из поля и получит kotlin.UninitializedPropertyAccessException.
Это все примеры того, что nullability, как и множество других свойств зачастую контекстно-зависимые и не могут быть объявлены статичным контрактом.
Ну и предполагается что хорошо организовав типы в проекте, да и саму кодовую базу, вам не придётся регулярно упорно доказывать компилятору, что "да зуб даю, тут не null". Наш опыт показывает, что в ~10-15% случаев, когда программист думает "тут никогда не бывает null", он ошибается :)
Да ладно? Вы никогда со структурами не работали? Не байндили формочки к UI?
NPE самая частовстречаемая, но легко детектируемая и отлаживаемая ошибка. А статичными контрактами далеко не всегда удается вывести nullability. Вместо, чтобы вставлять nullability в контракт, просто поставьте Objects.requireNonNull() или лишний assert там, где это нужно и дело в шляпе.
fun toString(a: Any?): String? {
return a?.toString()
}
@JvmName("toStringNotNull")
fun toString(a: Any): String {
return a.toString()
}
Понятно. Спасибо за экскурс в мир Java/Kotlin
В TS пункт первый вполне решаем. Этот метод можно написать так, чтобы результат зависел от исходных данных. Можно вернуть для nullable значений nullable string, а для остальных просто string. Правда сигнатура метода будет несколько замороченной. Без явной выгоды лучше написать два разных метода, чем морочить людям голову.
С late init тоже интересно. Понял что я даже не знаю как оно работает в TS, т.к. почти не использую классы и мутабельные структуры (а иммутабельным не нужна поздняя инициализация). Надо будет поиграться с этим.
Да ладно? Вы никогда со структурами не работали? Не байндили формочки к UI?
Какими именно структурами? И не очень понял какое отношение имеет binding к UI формам к обсуждаемому вопросу. Но при прочих равных я предпочту ошибку в compile time, а не в runtime. И предпочту работать с not-null значениями, чем с nullable. Обычно с этим проблем нет, в том числе и в web-формах. Ведь у поля формы ещё до bind-а есть значение (то что по-умолчанию). Поэтому и null не нужен. Возможно я не очень понял контекст.
Преимущество TS в том, что вам дают выбрать между строгой типизацией, нестрогой и динамической (всегда есть фоллбэк в голый JS). В Котлине (да и в Java тоже) такой опции нет — везде требуют строгие декларации, причем в котлине они более жесткие (тип dynamic не берем в рассмотрение — он был внедрен как пятое колесо специально для совместимости с JS). Сделано это с благими намерениями, чтобы обязовать пользователя писать "правильный" (по чьему-то мнению) код, однако как всегда там, где модель немного выходит за рамки, жесткие ограничения начинают жутко мешать.
И не очень понял какое отношение имеет binding к UI формам к обсуждаемому вопросу.
Как раз связано с nullable. Есть Entity, поля которой завязаны на UI-форму, и которая заполняется прогрессивно, например с веба. Вконце делается валидация полей (напр. при помощи JSR305), и все сохраняется в storage. Естественно, в Котлине все поля приходится описывать как nullable, и даже required-поля, которые никогда потом не будут null.
class User {
@NotNull
var username : String?
}А затем уже на этапе использования везде расставлять "!!", либо пустые не-null проверки, что только увеличивает возможность ошибки. Многие скажут, что "правильный" kotlin-way здесь — это на каждую Entity создать еще один объект EntityDTO, в который делать меппинг формы, а затем уже замепить его в сам Entity. Но это сразу тупо в 4 раза увеличивает код практически без увеличения функциональной ценности.
Не очень понятно зачем описывать required поля как нулл — просто потому что фреймворк не умеет нормально инициализировать структуру? Ну, с натяжкой можно посчитать это проблемой котлина, но я предполагаю что для таких случаев есть бекдор (как null forgiving в C# к примеру)
Мне кажется, что ваш пример с полями формы имеет слабое отношение к Kotlin, а вместо этого завязан на какой-то конкретный подход или framework. Вы с точно такой же проблемой столкнётесь и на других языках, если будете писать в том же стиле.
В случае TS у вас, вероятно, будет что-то типа IO-TS, и вы сразу получите готовый DTO правильной формы с автовыводом типов по структуре валидатора. Без дублирования кода. Но тут уже нас выручает не null-safety, а algebraic types.
Собственно, ИМХО, сила типизации — это спектр, который как раз и определяется, присутствие насколько сложных желательных (или отсутствие нежелательных) поведений можно гарантировать системой типов языка.
Я бы обобщил — которые могут быть вычислены на этапе компиляции. А система типов — это один из способов для декларации этих поведений, однако не единственный. Теоретически суперумный компилятор может вычислить всю вашу программу и расставить типы автоматически. И многие компиляторы (и IDE) кое-где умеют так делать (вывод типов). А система типов лишь на порядки упрощает эту работу.
Более сильная система типов даёт вам возможность гарантировать больше вещей статически, но не требует этого.
Проблема в том, что как правило именно требует, благодаря чему делая простые вещи сложными в реализации. В Java вы не можете описать класс с динамическим набором полей, как в JavaScript — для этого приходится использовать Map. Еще более сложно иметь клас одновременно со статическими и динамическими полями. Котлине нет типа "contextual nullable" как в Java. Точнее он есть (Any!!), но это внутренний тип компилятора, введенный для совместимости с Java. TypeScript — да, позволяет использовать типы опционально там, где это нужно, имея fallback в JS.
Я бы обобщил — которые могут быть вычислены на этапе компиляции. А система типов — это один из способов для декларации этих поведений, однако не единственный. Теоретически суперумный компилятор может вычислить всю вашу программу и расставить типы автоматически. И многие компиляторы (и IDE) кое-где умеют так делать (вывод типов). А система типов лишь на порядки упрощает эту работу.
Судя по последним тенденциям все наоборот — вы пишете типы, а компилятор вам генерирует реализацию функций, соответствующую вашим типам :) Ибо по реализации генерировать — никогда не ясно, что являетяс деталью реализации, а что — нет. Тут не супер умные компилятор нужен, а ещё и хрустальный шар чтобы мысли угадывать.
Проблема в том, что как правило именно требует, благодаря чему делая простые вещи сложными в реализации. В Java вы не можете описать класс с динамическим набором полей, как в JavaScript — для этого приходится использовать Map.
А чем Map не является "динамическим набором полей"? Как по мне это одно и то же, разве что на объект можно ещё функций навесить — но вот объект с хз какими полями и ещё и функциями я бы вот видеть лишний раз не хотел.
Еще более сложно иметь клас одновременно со статическими и динамическими полями.
Не очень ясно что с этим сложного
Котлине нет типа "contextual nullable" как в Java. Точнее он есть (Any!!), но это внутренний тип компилятора, введенный для совместимости с Java. TypeScript — да, позволяет использовать типы опционально там, где это нужно, имея fallback в JS.
Обычно в языках делают бекдор, который позволяет сказать "я знаю что делаю". Это и прагмы, и прочие подобные вещи. Если в котлине такой возможности не дали — то косяк, что сказать. Во всех популярных япах это обычно сделать можно.
Я реально уже не помню в деталях, раз как-то заставил работать. Общее впечатление — создаешь модель, она валится на сериализации из-за чисто котлиновских фич (конструкторы, nullability, immutable collections, delegates, vals, etc.), и приходится все перелопачивать. Для простых data objects проблем не возникает. Если интересно в деталях, загляните сюда https://github.com/FasterXML/jackson-module-kotlin/issues
Действительно надо понимать где код suspendable а где нет.
Вообще-то нет — это совершенно лишнее знание (да простит меня Роман Елизаров), требуемое конкретной реализацией асинхронности. Асинхронность появилась для того, чтобы обойти ограничение posix thread на масштабируемость путем избегания блокировок. Корутины — это лишь хак компилятора, где suspendable подменяет собой asyncrhonous callback. А любой хак, всегда несет с собой кучу побочки и проблемы интеграцией с уже существующей базой. Навскидку, вам под suspendable придется переписать весь стек до самого низкого уровная I/O и JDBC, многие фреймворки используют текущий контекст ThreadLocal в аспектах (напр. @Transactional), кторый не будет работать с suspendable (но и не выдаст ошибки), сложность дебага и стектрейса, etc. С другой стороны упомянутый мной Loom совершенно прозрачно реализует масштабируесомть для блокируемого кода, не требуя абсолютно никаких модификаций. Поэтому для JVM тут спорный выигрыш.
Тем не менее корутины как механизм хорош на других платформах, где нет suspendable threads, либо нет блокировок (native, JS, Android).
код который может вызвать запрос на гигабайт через пол-планеты — выглядят одинаково (как в каком-нить олдовом RPC).
А он и должен выглядеть одинаково, поскольку для логики кода здесь нет абсолютно никакой разницы — от suspendable быстрее он не выполнится, и точно также будет ждать, пока завершится асинхронный вызов прежде, чем перейти к другому шагу.
А со временем все больше и больше API будут становиться полностью асинхронными (потому как тренд это нынче, не пишут сейчас чисто блокирующих API)
Мне бы ваш оптимизм, но увы. Еще даже нормального асинхронного JDBC стандарта на этот счет нет (и по ходу не будет). Весь низкоуровневый I/O-слой — это блокирующие API.
Майкрософт когда делала WinRT 10 лет назад уже выкинула на помойку синк — все ИО функции нового апи были асинронными.
10 лет прошло — воз и ныне там. Думаю ещё за 10 мало что изменится.
В разы проще в поддержке, говорите? Знаю историю, когда весьма опытный и прошаренный программист написал серьёзный пласт логики на корутинах, затем настолько замучался их отлаживать, что выкосил их полностью, перейдя на более традиционные штуки типа CompletableFuture. Вы, конечно, можете сказать, что просто программист недостаточно умный, а умный бы всё быстро отладил. Но во-первых, это не так, а во-вторых, даже если вы гениальны и легко ловите находите любые баги в корутиновом коде просто посмотрев на него, то не факт, что тот, кто придёт после вас поддерживать этот код, будет настолько же прозорлив.
Начал в связи с работой изучать котлин. По сравнению с java 11+lombok он преимуществ не дает. При этом
1. Коротко написано
a+b.prop=19
в вашем коде может делать абсолютно что угодно и вам придется изучить код+все исходники что бы понять, что именно это делает. Самодокументация в джава что то вроде
a.addSaylary(b.getSaylaryIndex()).setDept(19) на деле требует намного меньших усилий для понимания. В котлин просто неверную метрику выбрали для оценки и правильно ибо хомяки ведуться массово. При этом так как есть автодополнение, что бы написать обе эти конструкции нужно нажать сопоставимое число кнопок, так что "быстрее набрать" тоже не катит.
2. Далее нал сейф конструкции. В java их можно спокойно заменить на Optional.ofNullable(X).map(x->x+1).orElse(y); и подобные однострочники, если хочется. При этом это медленнее работает, но в некритических местах видеть что то вроде (X?:1)+1 это прям глаза режет, так как ты начинаешь читать символы вместо простого английсого текста.
3. У них есть "крутая фича" extension functions на которой большая часть всего выстроена. Так вот как только в расширяемом так классе случайно сделают метод с такой же сигнатурой как функция расширения, ваш код молча, без ошибок и предупреждений начнет делать не то, что вы думаете :) Это вообще ржака. Никто, никогда, ничего отвественного на таком инструменте делать не будет...ну если он изучает нечто, а не бежит за хайпом
3. Так как котлин догоняет и обитает в jvm, то в java просто включат все самое вкусное, что уже и произошло, так как внига про котлин постоянно напоминает, что сравнение идет с java до версии 8 и котлин лучше чем она. Это уже просто факт, что котлин перегонял уже давно не поддерживаемую даже версию java.
4. В связи с всем вышеперечисленным, смотрю я на проект один на котлине и...все время надо лазить и проверять, что тут реально происходит, что бы понять из самого кода на котлине это нихера не следует. Потому, весь этот диабет сахарный не стоит того что бы на него тратить время. На андроиде он появился только в связи с судом между гуглом и ораклом и скоро его заменить Dart+Flutter, разрабатываемый самим гуглом. А больше котлин нигде и не вперся.
Итоги прочтения пока 300 из 400 страниц книжки по котлину "Котлин в действии". Дочитаю скоро.
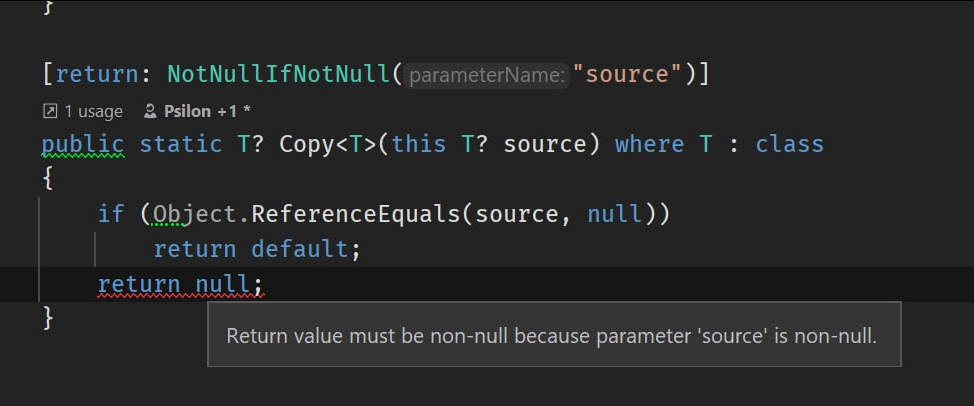


«Почему Kotlin хуже, чем Java?»