Комментарии 21
чаще всего при моделировании за шум принимают АБГШ (аддитивный белый гауссовский шум),
Спасибо, что Вы сделали это очень важное замечание! Часто этот момент упускают из вида. Но в данном случае не стоит останавливаться, сказав "А" ;-)
Понятно, что вопрос о характеристиках шума можно разворачивать бесконечно. Но все-таки наверно тут стоило бы добавить, что есть некоторые предметные области, где предположение АБГШ абсолютно неприемлемо. Например, шумы в электронных приборах, практически все геофизические временные ряды, а также многие другие процессы - это фликкер-шум. Для геофизических временных рядов это становится особенно очевидно, если нарисовать график логарифма спектральной мощности в зависимости от логарифма частоты или периода - там будет прямая линия (см. два нижних спектра - это модельные ФШ-ряды). Изрядное число примеров для реальных рядов, и еще больше ссылок можно найти вот тут.
Но если вы действительно столкнулись с фликкер-шумом (вместо АБГШ), то все привычные закономерности и правила применения статистических методов внезапно оказываются под огромным вопросом. Я сам не использую фильтр Калмана, так как у нас во всех временных рядах есть множество пропущенных наблюдений, а он этого очень не любит. Но несмотря на отсутствие практического опыта именно с этим фильтром, у меня есть сильные подозрения, что в случае ФШ-сигналов описанные в статье алгоритмы могут работать очень криво, особенно при больших значениях k.
В качестве критического параметра, показывающего степень отличия реального шума от белого, можно использовать так называемый степенной параметр фликкер-шума, который обычно обозначается буквой <бета> (извините, не знаю, как тут написать что-то по-гречески). Фактически <бета> - это коэффициент линейной регрессии логарифма спектральной мощности на логарифм частоты (периода). Для белого шума он равен нулю (см. первый график), а для множества реальных процессов варьирует в диапазоне от 0.5 до 2.0 (примеры см. там же).
Понятно, что <бета>=2.0 - это процесс с независимыми случайными приращениями. (Прямой поиск термина приводит на вот эту страницу, но, на мой вкус, она менее удачно написана, и лучше лазить по первой ссылке). Для таких временных рядов обычные статистические методы заведомо не работают. Но даже при значениях <бета> порядка 1 все тоже может быть очень плохо.
В общем, практический совет такой: обязательно проверяйте спектр шума, прежде чем выбирать метод фильтрации. И если вдруг степенной параметр <бета> окажется порядка единицы или больше, то семь раз протестируйте алгоритм на моделях, прежде чем один раз его применить ;-)
Кстати, если кому-то для тестов понадобятся фрактальные временные ряды, то вот тут выложен пакет из 200 модельных рядов, сгенерированных по алгоритму Фосса. Мне самому было бы очень интересно взглянуть на результаты фильтрации разных модельных сигналов, на которые вместо белого шума наложен "фрактальный", или фликкерный шум. Если вдруг у Вас будет желание и возможность провести такое тестирование - пишите в личку, постараюсь помочь, чем смогу.
прежде всего для новичков, которые ничего не понимают в фильтрации
в фильтрации чего?
Прочитал Введение, но пока не понял о чем статья.
Прочитал раздел "Фильтр Калмана" и пока всё равно не понял о чем статья. (могу конечно лезть в википедию, но вы же в самом начале написали что статья для новичков)
Фильтрация позволяет нам получить как само значение на данном шаге
Значение чего?
Всё это можно использовать по Вашему усмотрению
Что "это"?
Ну а теперь в википедию:
Фильтр Калмана широко используется в инженерных и эконометрических приложениях: от радаров и систем технического зрения до оценок параметров макроэкономических моделей[1][2]. Калмановская фильтрация является важной частью теории управления, играет большую роль в создании систем управления. Совместно с линейно-квадратичным регулятором фильтр Калмана позволяет решить задачу линейно-квадратичного гауссовского управления. Фильтр Калмана и линейно-квадратичный регулятор — возможное решение большинства фундаментальных задач в теории управления.
Где используется[править | править код]
Рельефометрические (по цифровым картам местности)
в фильтрации чего?
Некоторой измеряемой величины, содержащей погрешности измерения. Задача фильтрации - свести шумы к минимуму.
Что это может быть - да что угодно. Например, координаты с GPS приемника...
в фильтрации чего?
Сигнала. Чего же еще. Не воды же.
Здравствуйте! Согласен с Вами, моя вина -- не указал область применения и обстоятельства, которые обеспечивают необходимость фильтра. Поправил Disclaimer.
Здравствуйте, но что такое "шум" в контексте обозначенной темы и причем тут экономика? (открою секрет, особенно двум товарищам выше - я в теме и всё понимаю, просто я до занудства не люблю материалы, которые не выдерживают академические стандарты. Но раз вы в самом начале написали слово "новичок", то материал должен быть другим. Ну или уберите "новичка", но тогда не ясно для кого материал)
Про шум в контексте обозначенной темы:
Да, Вы правы, нужно было добавить как минимум следующее:
z = x + w, где
z -- измеренная величина
x -- величина истинная
w -- шумовая добавка
Шум, как минимум, обусловлен погрешностью измерительных приборов, случайными ускорениями модели. (например, если мы фильтруем координаты какого-нибудь летательного аппарата, то это может быть поправка на скорость ветра, погодные условия)
Про экономику:
В экономику также есть случайные ускорения. Я работаю в сфере радиолокации, но очень часто когда мне приходилось искать алгоритмы экстраполяции и фильтрации я натыкался на вполне понятные объяснения, представленные в виде лекций ВШЭ(высшей школы экономики). Эти лекции, соответственно, предназначались для экономики. На всякий случай, приведу СУБЪЕКТИВНЫЙ пример в достаточно свободной форме:
Мы мониторим цену на пиццу в ближайшем кафе по типу месяц--средняя цена за кусок. В мае очень много праздников, пиццу заказывают часто, в связи с этим хитрый хозяин кафе решил уменьшить цену в 2 раза по определённым датам, чтобы пицца была ещё привлекательной. Именно это и является шумом, случайным ускорением. Да, цена действительно уменьшилась в 2 раза, что не соответствовало экстраполяции, но цена уменьшается только в определённые дни.
То есть, для получения адекватной оценки средней цены за кусок, нужно как-то сгладить этот майский скачок вниз, а фильтр как раз таки поможет нам это сделать.
В роли "ошибки измерительного прибора" может выступать то, что человеку, который замерял цену на кусок, в какой-то из дней стало лень идти её смотреть и он просто написал в своей выборке данных цену, которая была в прошлый раз.
Степень фильтрации зависит от параметров фильтра и от его "вида", я ни в коем случае не агитирую пихать везде альфа-бета фильтр, но почему бы не попробовать хотя бы промоделировать такую систему и посмотреть на результат.
P.S.: Вечером постараюсь отредактировать статью в соответствии с Вашим замечанием, чтобы внести ясность для читателей. Спасибо за дельный совет. Прошу отнестись с пониманием и снисхождением к примеру выше -- он придумывался прямо во время написания комментария, очень хочется быть хорошим специалистом и свободно общаться на эту тему, а для этого нужно прежде всего пробовать, на мой взгляд.
я же без наезда, я лишь отметил что материал для "новичка" подразумевает несколько более широкий охват как используемых терминов и разъяснений, так и глубины освещения вопроса - не каждый новичок смирится с необходимостью читать параллельно со статьёй гугл/яндекс.
касательно шума - слово у обывателя ассоциируется в 99% случаев со звуком, но имеет несколько более широкое применение в математических методах и алгоритмах. Дополнительное объяснение поможет в этом сориентироваться например тем, кто читает материал на уровне научпопа.
Я бы рекомендовал для терминов или писать короткие сноски или делать ссылкой на вики. Тема-то очень интересная и самое главное для многих кажущаяся ненужной или какой-то узкоспециальной. Я с "шумом" столкнулся при обработке изображений и их фильтрации, думал нахвататься верхушек да забыть, но вот 25 лет прошло, а я даже не слишком-то и погрузился в тему.
На вас подписан, буду ждать еще статьи, буду рад если напишете что-то про фильтры для изображений, если это входит в вашу область применения.
Фильтрация изображений была у меня в ВУЗе, на практике не использовал.
Разбирали достаточно много алгоритмов, всё с примерами, отчёты по лабораторным были 50+ (иногда 100+) страниц, был очень сильный преподаватель, который работает в этой сфере и это основной его вид деятельности. Сейчас пишу диплом, при первой возможности -- продолжу развивать данную тематику, спасибо Вам за обратную связь!
Либо как-то популярно объяснить общий принцип до формул. Раз уж код не объясняете.
А так — и не то и не сё.
Здравствуйте!
Писал код с комментариями, всё делал по вышеописанным мной шагам -- надеялся, что поможет. Согласен, что по-хорошему здесь нужна моделирующая программа, выложенная на гитхаб для демонстрации работы фильтра.
"Либо как-то популярно объяснить общий принцип до формул. Раз уж код не объясняете." -- попробовал это сделать во фрагменте "Идея фильтра".
А что, alpha и beta должны со временем быстро стремиться к 0 ?
чаще всего при моделировании за шум принимают АБГШ (аддитивный белый гауссовский шум),
Спасибо, что Вы сделали это очень важное замечание! Часто этот момент упускают из вида. Но в данном случае не стоит останавливаться, сказав "А" ;-)
Понятно, что вопрос о характеристиках шума можно разворачивать бесконечно. Но все-таки наверно тут стоило бы добавить, что есть некоторые предметные области, где предположение АБГШ абсолютно неприемлемо. Например, шумы в электронных приборах, практически все геофизические временные ряды, а также многие другие процессы - это фликкер-шум. Для геофизических временных рядов это становится особенно очевидно, если нарисовать график логарифма спектральной мощности в зависимости от логарифма частоты или периода - там будет прямая линия (см. два нижних спектра - это модельные ФШ-ряды). Изрядное число примеров для реальных рядов, и еще больше ссылок можно найти вот тут.
Но если вы действительно столкнулись с фликкер-шумом (вместо АБГШ), то все привычные закономерности и правила применения статистических методов внезапно оказываются под огромным вопросом. Я сам не использую фильтр Калмана, так как у нас во всех временных рядах есть множество пропущенных наблюдений, а он этого очень не любит. Но несмотря на отсутствие практического опыта именно с этим фильтром, у меня есть сильные подозрения, что в случае ФШ-сигналов описанные в статье алгоритмы могут работать очень криво, особенно при больших значениях k.
В качестве критического параметра, показывающего степень отличия реального шума от белого, можно использовать так называемый степенной параметр фликкер-шума, который обычно обозначается буквой <бета> (извините, не знаю, как тут написать что-то по-гречески). Фактически <бета> - это коэффициент линейной регрессии логарифма спектральной мощности на логарифм частоты (периода). Для белого шума он равен нулю (см. первый график), а для множества реальных процессов варьирует в диапазоне от 0.5 до 2.0 (примеры см. там же).
Понятно, что <бета>=2.0 - это процесс с независимыми случайными приращениями. (Прямой поиск термина приводит на вот эту страницу, но, на мой вкус, она менее удачно написана, и лучше лазить по первой ссылке). Для таких временных рядов обычные статистические методы заведомо не работают. Но даже при значениях <бета> порядка 1 все тоже может быть очень плохо.
В общем, практический совет такой: обязательно проверяйте спектр шума, прежде чем выбирать метод фильтрации. И если вдруг степенной параметр <бета> окажется порядка единицы или больше, то семь раз протестируйте алгоритм на моделях, прежде чем один раз его применить ;-)
Кстати, если кому-то для тестов понадобятся фрактальные временные ряды, то вот тут выложен пакет из 200 модельных рядов, сгенерированных по алгоритму Фосса. Мне самому было бы очень интересно взглянуть на результаты фильтрации разных модельных сигналов, на которые вместо белого шума наложен "фрактальный", или фликкерный шум. Если вдруг у Вас будет желание и возможность провести такое тестирование - пишите в личку, постараюсь помочь, чем смогу.
Спасибо Вам большое за такой развёрнутый комментарий!
По поводу пропущенных наблюдений: они есть во многих системах, но ведь экстраполяция может спасти? Не претендую на правду, но могу предложить Вам попробовать МНК, а позже и взвешенный МНК(например последнему наблюдения давать больше веса, чем тем что были раннее). На самом деле, экстраполяция, которая представлена в статье, является очень слабой, но она содержится в оригинальном описании фильтра, поэтому я решил ничего не менять.
По поводу шумов: слышал про такое, но что-то серьёзное увидел впервые только сейчас от Вас. Буду разбираться, изучу этот момент. Спасибо Вам.
Да ладно бы альфа и бета стремились к нулю.
У вас фильтрованное и экстраполированное значение и скорость также к нулю стремятся.
Попробовал вместо одной из своих самописок на тему одномерной фильтрации в рабочий проект подставить, поотлаживаться, сравнить точность.
Результат удручил, ну автор, ну зачем ты так?
Доброго времени суток! Приведённый мной алгоритм используется во вполне рабочих проектах ровно в том виде, в котором я его здесь описал. Вы точно перестаёте пересчитывать коэффициенты альфа и бета? На каком шаге Вы это делаете? Как часто обновляются данные? Давайте вместе искать решение. Попробуйте фиксировать значения альфа и бета при k=10, а позже при k=15 и так по-тихоньку увеличивайте значение, если результат будет улучшаться.
P.S.: Посмотрите внимательно на формулы, экстраполированные значения сами по себе ну никак не могут стремиться к нулю, в общем случае дак точно. Можете прислать мне строчки кода, попробую помочь.
Вообще да, фиксация коэффицентов вполне может помочь.
Там ситуация такая, что:
разброс измеряемой величины примерно равен её значению.
Величина изменяется линейно на отрезках, а не на всём протяжении измерений
Слишком большое влияние изменений величины на первых шагах исказило результат.
Вообще да, фиксация коэффицентов вполне может помочь.
Не думаю, что правильно использовать фильтр без фиксации коэффициентов. Я в статье прям пример привёл, почему так делать не стоит. (Возможно, он был дописан уже после Вашего комментария)
Давайте попробуем пройтись по пунктам.
1. разброс измеряемой величины примерно равен её значению.
Получается, что у нас очень большие значения шума.
2. Величина изменяется линейно на отрезках, а не на всём протяжении измерений
Получается, что мы знаем, когда эти отрезки начинаются? А Вы гоните фильтр всё время, или только на этих отрезках начинаете инициализацию? Тут нужно смотреть на то, что вы измеряете и как оно себя ведёт.
3. Слишком большое влияние изменений величины на первых шагах исказило результат.
Понятно -- инициализация фильтра по сильно зашумлённым данным задало нам неправильное значение скорости изменения величины, а далее фильтр пытается его выровнять всё время. Тогда может стоит попробовать инициализировать фильтр на тех участках где шумы минимальны?
P.S.: Вообще это может быть из-за откровенно слабой экстраполяции в этом фильтре. Если Вы умеете использовать МНК, я бы предложил Вам попробовать его. Всё хочу написать статью по этому поводу, где разобрал бы метод наименьших квадратов на конкретных примерах. Хочу показать эффективность альфа-бета фильтра с ним и без него, но пока что руки не доходят, хотя различия там колоссальные -- я такое уже и моделировал, и не только.
Вообще говоря, не Калманом единым. Многие рекурсивные фильтры (и Калман в том числе) уходят корнями в обычный LowPass фильтр
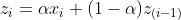
а дальше уже вариации на тему коэффициентов.
В качестве более простой (но во многих случаях работающее не хуже) альтернативы Калману можно рассматривать экспоненциальное сглаживание (обычное, двойное, тройное)
Для выявления линии тренда в ряде случаев неплохо подойдет фильтр Ходрика-Прескотта (хотя он не является рекурсивным как Калман, LowPass, экспоненциальное сглаживание и более сложен вычислительно).
Калман (в его различных модификациях) хорош в тех случаях, когда известна закономерность по которой можно предсказывать следующее значение наблюдаемых данных (модель процесса). Например, если мы знаем скорость и ускорение, то можем предсказывать следующее значение координат и затем сравнивать их с наблюдаемым. И в общем случае фильтр Калмана работает с матрицами - текущего состояния, эволюции, апостериорного состояния, наблюдений, управления.
И в тех случаях, когда модель процесса неизвестна (нет возможности построить матрицу управления), сглаживание может работать ничуть не хуже но быть проще в реализации.
Альфа-бета фильтр Калмана: фильтр «Hello, world!»