Наш клиент, крупный маркетплейс товаров из Китая, определил “цвет”, как один из самых важных атрибутов на сайте, именно этот параметр встречается в 23 категориях из 30.
Однако в нашем случае, фильтрация товаров по цвету является сложной задачей, потому что, карточки товаров заполняют не представители маркетплейса, а продавцы конкретных товаров, которые не всегда понимают, что заполнять данные о продукции стоит максимально подробно и понятно для каждой позиции. В свою очередь, маркетплейс также не регламентирует каких-то четких правил описания товаров. Это привело к тому, что характеристики товара заполнены неверно или неточно. Особенно наглядно это проявляется в описании цвета, где некоторые селлеры могут написать что-то непонятное, например, “цвет утреннего рассвета”.
Отметим, что данных для обучения ML-моделей, к сожалению, нет. То есть мы не можем выделить группу товаров для тренировки, в которой мы были бы заведомо уверены, что атрибуты проставлены верно. Предварительная оценка показала, что только в 31% товаров цвет был заполнен одним из значений, которые мы впоследствии хотим видеть в фильтрах, но даже это не значит, что он заполнен верно без ручной проверки.
Кроме того, товаров очень много – более 100 млн. Заполнять атрибуты вручную для каждого товара займет слишком много времени и ресурсов, которые тратить никто не готов.
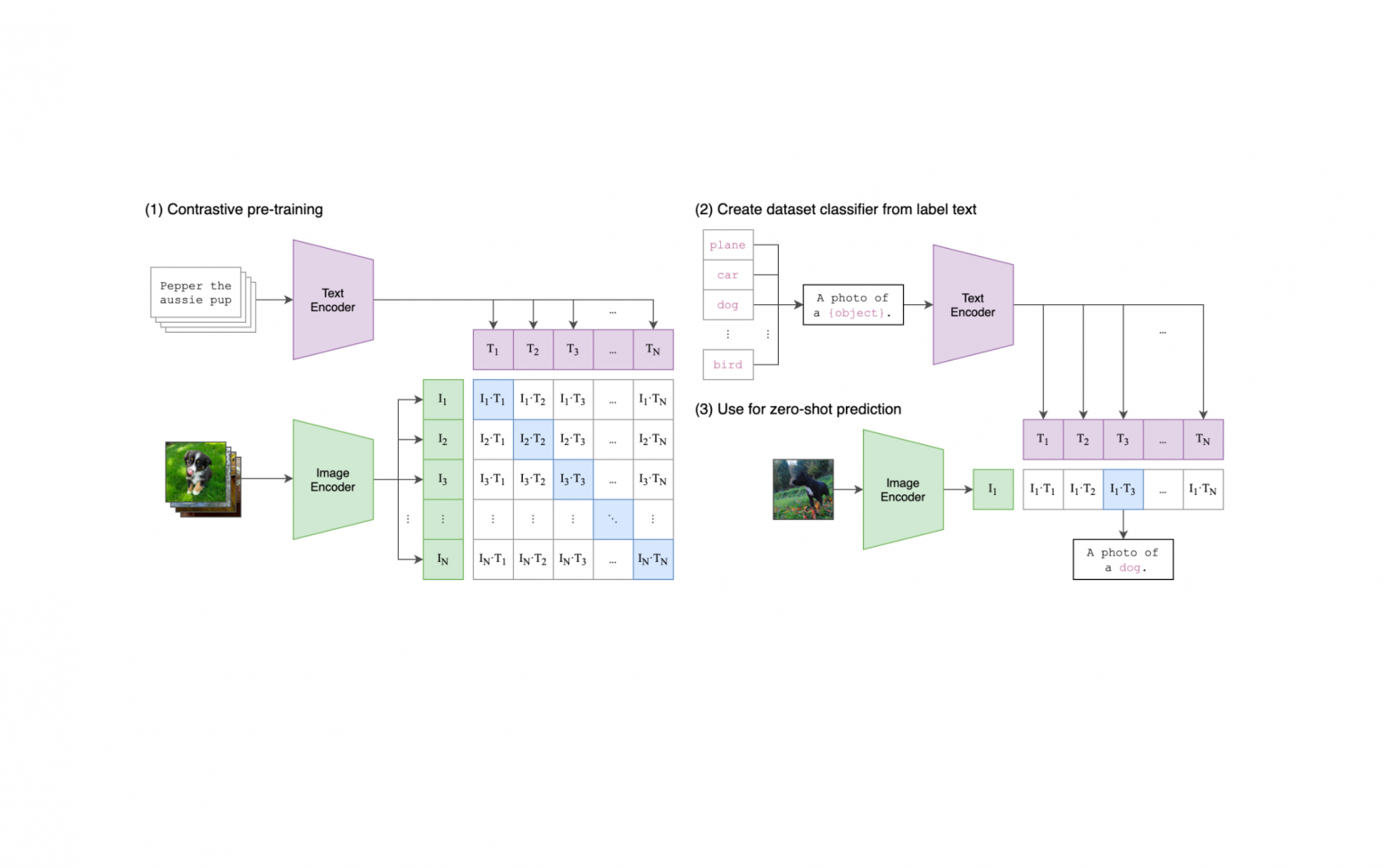
Фишкой данного решения является минимальное использование обучающих данных для достижения высокой точности в классификации изображений. Это достигнуто благодаря использованию модели CLIP (Contrastive Language-Image Pretraining), которая предназначена для zero-shot и one-shot обучения, изначально созданная для сопоставления изображения и его текстового описания.