
Приглашаем вас на московский летний митап, посвящённый Apache Ignite. Присоединяйтесь к встрече пользователей и разработчиков. В этот раз, как заказывали, покажем примеры кода, много примеров.
Компания GridGain временно не ведёт блог на Хабре



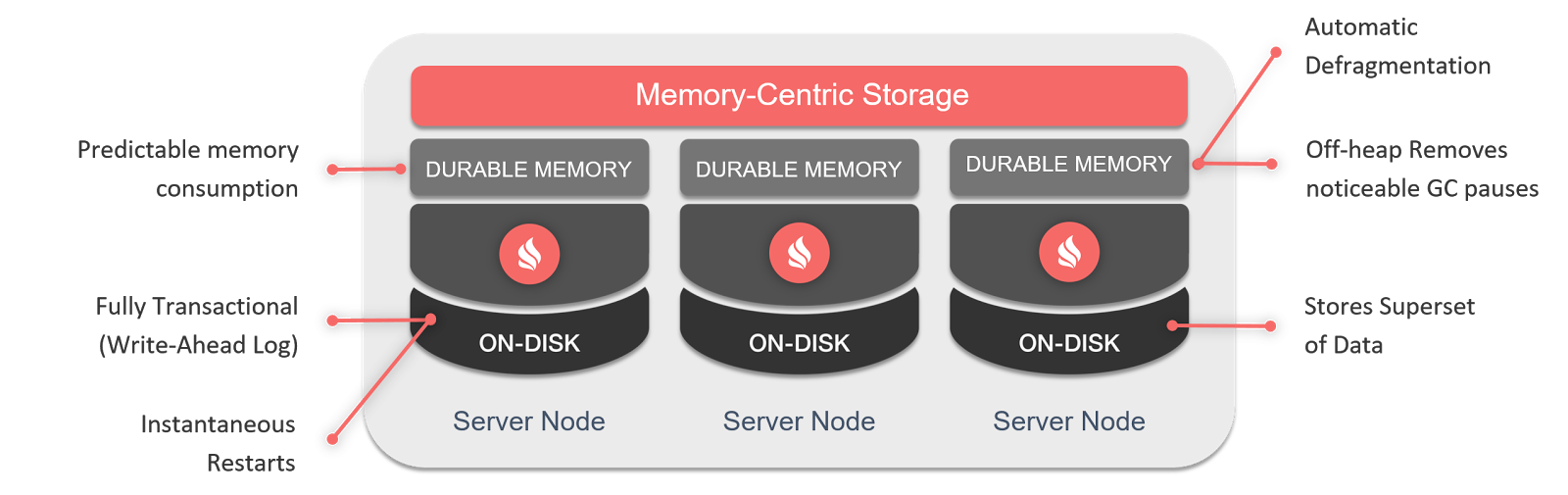
На момент появления в Apache Software Foundation проекта Ignite он позиционировался как чистое in-memory-решение: распределенный кэш, поднимающий в память данные из традиционной СУБД, чтобы выиграть во времени доступа. Но уже в релизе 2.1 появился модуль встроенной персистентности (Native Persistence), который позволяет классифицировать Ignite как полноценную распределенную базу данных. С тех пор Ignite перестал зависеть от внешних систем обеспечения персистентного хранения данных, и вязанка граблей конфигурации и администрирования, на которые не раз наступали пользователи, исчезла.
Однако persistent-режим порождает свои сценарии и новые вопросы. Как предотвратить неразрешимые конфликты данных в ситуации split-brain? Можем ли мы отказаться от перебалансировки партиций, если выход узла теперь не означает, что данные на нем потеряны? Как автоматизировать дополнительные действия вроде активации кластера? BaselineTopology нам в помощь.
Недавно вышла новая версия распределённой SQL базы данных Apache Ignite, предлагаю взглянуть на новые фичи с позиции .NET.
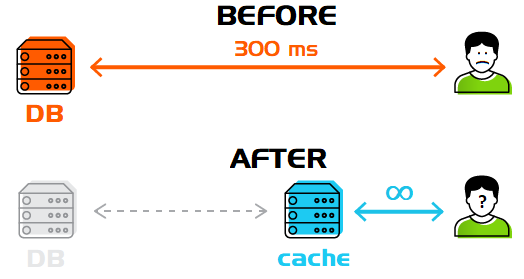
Многие верят что кеш, да еще и распределенный, — это такой простой способ сделать всё быстрее и круче. Но, как показывает практика, неправильное применение кеша часто, если не всегда, делает всё только хуже.
Под катом вас ожидает пара историй о том, как неправильно прикрученный кеш убил перфоманс.



В продолжение темы «доступным языком про Ignite / GridGain», начатой в предыдущем посте (Для чего нужен Apache Ignite), давайте рассмотрим примеры использования продукта «для простых смертных».
Терабайты данных, кластеры на сотни машин, big data, high load, machine learning, микросервисы и прочие страшные слова — всё это доступно Ignite. Но это не значит, что он не годится для менее масштабных целей.
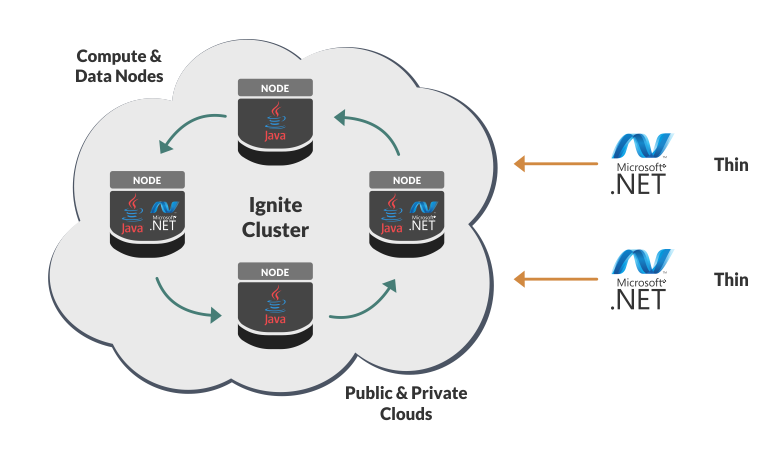
Сегодня мы рассмотрим, как Ignite может легко хранить любые ваши объекты, обмениваться ими по сети и обеспечивать взаимодействие .NET и Java.



В предыдущей статье — часть 1, обзорная — я рассказал о том, зачем нужны распределенные структуры данных (далее — РСД) и разобрал несколько вариантов, предлагаемых распределенным кешем Apache Ignite.
Сегодня же я хочу рассказать о подробностях реализации конкретных РСД, а также провести небольшой ликбез по распределенным кешам.
Итак:
