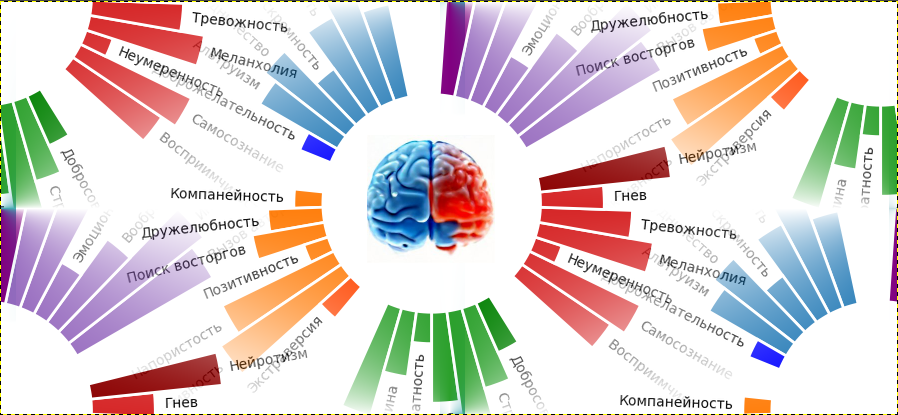
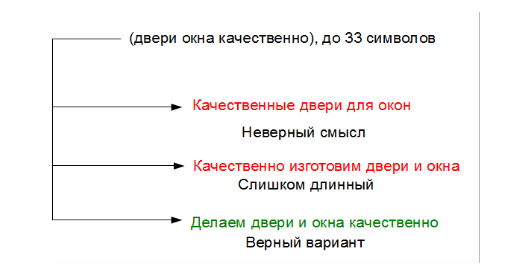
Масштабирование больших языковых моделей (LLM) является захватывающей темой, поскольку рассматривается как один из лучших кандидатов на пути к ИИ человеческого уровня. Уже сейчас LLM могут отвечать на вопросы, генерировать реалистичные статьи и поддерживать, казалось бы, осмысленный разговор на широкий круг тем. Некоторые исследователи ИИ даже утверждают, что LLM возможно уже могут «слегка обладать сознанием», а журналисты выпускают статьи вроде «роботы захватят весь мир» с картинками терминаторов. Однако, скептики возражают, что большинство таких моделей — это просто большая ассоциативная память, без истинного понимания реальности и неспособная к определенным типам задач. Одна из таких задач, которая привлекла мое внимание — игра в шахматы. В то время как специализированные шахматные движки давно обыгрывают чемпионов мира, даже очень большие языковые модели, такие как GPT-3 с сотнями миллиардов параметров едва справляются с такой простой задачей как мат в один ход. А с такими способностями к стратегии, эти модели едва ли справятся с завоеванием мира. Поэтому как шахматист со стажем и по совместительству разработчик нейросетей я решила попробовать устранить этот недостаток.