Комментарии 153
небольшая вместимость SSD, их ограниченный ресурс и высокая стоимость.
Уже давно на рынке есть 32Тб SSD, да и про ресурс и ненадёжность это так себе на самом деле… так что у дисков пока только один аргумент — стоимость. т.к. производители SSD предпочитаю увеличить их объём, продавая его за цену старых моделей, чем сильно снижать цены.
у дисков пока только один аргумент — стоимостьЧто с деградацией данных при длительном хранении?
Жесткие диски я могу держать в ящике стола время, уже вполне сравнимое с продолжительностью собственной жизни, различия явно меньше, чем на порядок. Исправные HDD, снятые с компов в 90-х, до сих пор спокойно читаются, главное живой IDE-разъем найти.
Что с SSD?
А что будет с современными с высокой плотностью, с перекрывающимися дорожками и прочим, это ещё вопрос.
KorP
Уже давно на рынке есть 32Тб SSD, да и про ресурс и ненадёжность это так себе на самом деле… так что у дисков пока только один аргумент — стоимость.
MTyrz
Что с деградацией данных при длительном хранении? [...] Что с SSD?
KorP
А зачем хранить SSD с данными в ящике стола?
И после этого я и написал, что рассматривать SSD с точки зрения хранения в столе придется, если HDD перестанут быть массово доступны
Впрочем, если мне расскажут варианты лучше, я буду совершенно не против.
Впрочем, если мне расскажут варианты лучше, я буду совершенно не против.
Смотря что вы там храните и в каком объёме, а то может и облако.
Вот щас обидно было, да. Пруфы то какие?
Облачное хранилище Yunpan 360 будет закрыто в 2017 году
Кто знает, что случилось с hubiC? Не могу забрать половину своих файлов. Адрес техподдержки не нахожу. Где-то проскочило, что они закрыли проект, но как забрать свои файлы?
Зашифрованное облачное хранилище Wuala полностью закрылось 15 ноября 2015 годаНе обижайтесь.
Хранилища закрываются, как и любые фирмы. Иногда непредсказуемо.
Это можно побороть, обычно они предупреждают загодя: но это уже требует слежения и прочего администрирования. Лишняя нагрузка.
А еще они требуют доступа в Сеть, а еще они на больших объемах платные, что даже за первые несколько лет уже дороже HDD, а еще разбираться с условиями предоставления услуги: что хранить, что не хранить, кто имеет доступ…
Ящик как-то проще и надежнее.
Хранилища закрываются, как и любые фирмы. Иногда непредсказуемо.
И не только закрываются
И да, оно основано или на HDD или на лентах, время доступа к данным — несколько часов. В смысле время, через которое в принципе можно будет приступить к чтению.

Когда у меня была почта у одного крупного провайдера, я тоже думал что её не закроют, но достаточно было пару лет не заходить...
если когда-нибудь приспичит использовать SSD для архивации, то их вполне могут сделать с аккумулятором — для рефреша раз-в-полгода ;)
Главное будет — не забыть вовремя заменить/зарядить аккумулятор.
(оглядываясь на полку, где в коробке лежат SATA винты 2004 года)
на моей памяти уже два HDD после годичного лежания на полке так и не включились.
Не, время от времени я их включаю (там файлопомойка, начиная с 1997 г.) — пока все нормально.
А вот с CD-R 2004 года таки проблемы — читаются только те, что были записаны на болванках Вербатум (болванки типа Sky перестали читаться еще лет десять назад).
А что касается чтения CD-R, несколько раз получалось прочитать на CD-RW то, что не читалось на DVD.
Это те которые «зелёненькие» по технологии SuperAZO?
Они были выкинуты тогда же, когда перестали читаться.
Поэтому про цвет уже не помню.
несколько раз получалось прочитать на CD-RW то, что не читалось на DVD.
У меня прямо противоположный опыт — CD-RW я перестал пользоваться еще тогда, когда они были актуальны.
Потому как были случаи, когда CD-RW, совершившие путешествие в другой город в багаже, уже по прибытии оказывались нечитаемыми (один-два дня).
Обычные диски CD-R у меня пару раз читались на приводах CD-RW те, которые не читались на приводах DVD. Что играло свою роль — скорость чтения, длина волны лазера или размер пятна лазера, я не знаю. Просто на всякий случай напомнил такое наблюдение — вдруг что-то будет нужно прочитать.
Так-то и в облака можно, просто следить за изменениями EULA.
Так что минимум RAID-6. А чтобы тратить 32 Тб и $1300 на избыточность — общий объём данных должен быть весьма и весьма приличным.
Примерный расчет для 10TB выдает следующий диапазон (начиная от самого оптимистичного):
14 часов — неделя. Пусть для 16TB будет 2 недели, за это время врядли диск выйдет из строя.
Плюс, насколько я понял, RAID5/6 для таких объемов стараются избегать.
RAID-5/6 на таких объёмах ровно поэтому избегать и стараются. Помимо рисков, получаем ещё просадку производительности на длительный период. Но тут речь шла про домашнее применение, где альтернатив обеспечить сохранность данных не так много. Никаких распределённых файловых систем нет. Бекапа на ленты нет. Резервная копия в облаке если и есть — то вытягивать терабайты обратно долго, а возможно и дорого (если из Amazon Glacier какого-нибудь тянуть, например).
Один рабочий, второй на полке с бекапом холодным.
Не теряются данные, изменившиеся с момента последнего доставания резервного диска с полки. Не теряется время на это самое доставание и копирование. Серьёзно уменьшается риск того, что вообще придётся восстанавливать данные. Но при необходимости данные восстанавливаются даже в сценарии «дом сгорел вместе с бекапным диском на полке». При вылете одного диска придётся покупать всего лишь дешёвый диск на 4 Тб, а не дорогой на 16. Ну и т.п.
Это если вам нужно получить 16Тб (тащемта уже неплохо, да).
Проблемы у вас начнутся, когда вас начнет лимитировать число свободных слотов в СХД или (с чем я однажды столкнулся) площадь серверного зала. Свободных юнитов в стойках почти ноль, свободных слотов в СХД ноль, квадратных метров под еще одну стойку не было изначально, и так пришлось в тетрис играть, граждане из бизнес-подразделения сообщают, что через месяц к нам приедет порядка 50Тб данных.
Было очень весело. Пришлось полностью менять все харды в MSAшке, чтобы влезло и то, что есть, и то, что ожидалось.
Применять к этим данным одинаковые методы защиты от сбоя дисков, я считаю бессмысленным. Я выбрал дублирование (на уровне папок) критичных данных на 2-х дисках встроенными средствами NAS-а, и хранение не критичных данных в единственном экземпляре. Это позволяет оптимально использовать место на дисках NAS-а.
При этом можно резервную папку не публиковать пользователям, и настроить на ней версионирование файлов (если позволяет NAS) и получить еще и защиту от программных сбоев в ПО работающем с файлами и шифровальщиков, если они заведутся на компьютерах имеющих доступ к опубликованным папкам.
Вопросы дополнительного копирования на off-line диск, в облако и т.д. в данном случае не рассматриваю.
У меня в целом такой же подход, как у Вас. Некритичные данные дублируются в 2 местах, критичные — в 3-4. Тех самых критичных терабайт 5, правда. Но это различие на уровне «на скольки серверах/облаках их дублировать». Без RAID (ну точнее с RAID-0, который надёжности только убавляет) живёт только хранилище записей на сервере видеонаблюдения.
Ваш вариант — это не замена RAID, а способ бекапа. Способ удобный тем, что в одном NAS с диска на диск восстановить данные очень быстро. Но ненадёжный тем, что сценариев, когда умрут оба диска, вставленные в один NAS, возможно с ним вместе, довольно много.
за это время врядли диск выйдет из строя.
второй диск уже мог выйти из строя (начать сыпаться), просто в рейде этого никто не замечал кроме рейд-контроллера. Который просто исправно помечал новые бэд-блоки и брал копию данных с других дисков (рейд жи ну).
А тут таки придётся его прочитать. Весь, целиком. И копий уже нет. И вот тут начинается «запил», от которого диск может сдохнуть уже прям совсем насмерть.
Как вы считаете, что получили «примерно вечность»?
Примерный расчет для 10TB выдает следующий диапазон (начиная от самого оптимистичного):
14 часов — неделя. Пусть для 16TB будет 2 недели, за это время врядли диск выйдет из строя.
В пору моей админской практики дважды наблюдал подобное «невозможное» событие:
Когда после выхода первого диска из массива — вскоре (через пару дней) выходит второй.
Есть мнение, что просто нагрузка на оставшиеся диски сильно возрастает после выхода первого из строя — поэтому.
Очевидно что такие устройства уже нужно пускать в кластерные ФС с репликацией, а не erasure code.
Очевидно что такие устройства уже нужно пускать в кластерные ФС с репликацией, а не erasure code.
Получаются слишком уж большие накладные расходы, RF2 не надежен, так как любое плановое обслуживание одной из нод кластера приводит к тому, что часть данных остается в единственном экземпляре. Это не говоря уж про внеплановые простои. RF3 имеет слишком большой оверхед, так как из условно 3 дисков на 16TB (48TB) у вас остается всего 16TB полезной емкости. Вряд ли это кому то сильно нравится, что под защиту даже не очень важных данных тратиться в 2-раза больше емкости, чем занимают сами данные. И это еще не считая того, что нужно выполнять их резервное копирование. А еще на многих подобных решениях не рекомендуется заполнять пулы более чем на 70-85% и вот уже реально доступно не 16TB, а еще пропорционально меньше.
> RF2 не надежен
«Не надежен» по сравнению с чем? Нет абсолютной надежности, есть достаточная надежность для этого типа данных или датасета.
К тому же «плановое обслуживание» можно, раз уж оно плановое, провести так, что данные заранее перереплицируются до его начала. Не бином Ньютона так сделать. Простая репликация в clustered filesystem тем и хороша, что она «знает свои данные», и может реплицировать их быстро, интеллектуально (например только нужные блоки) и проактивно. А не тупо пересчитывать все сто терабайт RAID массива.
> RF3 имеет слишком большой оверхед, так как из условно 3 дисков на 16TB (48TB) у вас остается всего 16TB полезной емкости.
Это и так и не так, потому что с RF3 хорошей практикой является использовать разнообразные методы data efficiency, и тогда эти «всего 16TB» превращаются в полновесные «32», просто за счет эффективного хранения. На практике, на реальных данных, RF3 c compression/dedupe, при более высокой степени защиты данных, имеет практически то же соотношение usable на raw, как у RF2 без этих опций.
> А еще на многих подобных решениях не рекомендуется заполнять пулы более чем на 70-85%
Это вопрос формулировки. Хотите другую?
«Если вы ограничите заполнение тома уровнем 85%, вы получите бесплатно для вас прирост общей дисковой производительности вашей дисковой подсистемы на 25%», или же «за стоимость двух-трех HDD вы получите прирост производительности на четверть».
Так звучит гораздо лучше, правда? А ведь это ровно та же ситуация, что у вас выше.
Вы это точно все в контексте медленных 16TB NL-SAS написали?
Берем средние по больнице 12 дисковые ноды ставим диски на 16TB. Получаем грубо 192TB на ноду. Плановая миграция 100-150TB (например для остановки ноды и замены DIMM модуля) на реально работающем кластере превращается в длительный и нудный процесс, при том что на кластере еще место свободное должно под эти 100-150 TB должно быть. Но это еще черт бы с ним.
Про дедуп/компрессию для первичных данных на медленных дисках такого объема — это больше похоже на шутку. Работать будет медленно и уныло и не дай бог что- то из строя выйдет и придется дедуплицированные чанки восстанавливать и активно с метаданными работать.
«Если вы ограничите заполнение тома уровнем 85%, вы получите бесплатно для вас прирост общей дисковой производительности вашей дисковой подсистемы на 25%», или же «за стоимость двух-трех HDD вы получите прирост производительности на четверть».
Не более чем удобная вендору игра слов. Условный кластер не будет иметь прироста прозводительности пока заполняется до критического объема, а вот как только заполнится, ловите просадку производительности и опять же не дай бог при этом еще и одна из нод из строя выйдет. А в таких вещах всегда лучше перебздеть, чем недобздеть.
Извините, просто для определенности: вы сейчас как теоретик в вопросе говорите, или как практик? Потому что я — как практик, у которого перед глазами петабайты данных, использущих компрессию и дедупликацию.
> Не более чем удобная вендору игра слов. Условный кластер не будет иметь прироста прозводительности пока заполняется до критического объема,
Нет, просто все зависит от того, что вы считаете за 100% производительности. Если за 100% принимаем производительность заполненного тома (что логично), то тогда не полностю заполненный том дает значительный рост производительности.
Это спор про наполовину пустой и наполовину полный стакан.
Но я рад, что мне удалось показать вам, что ситуация далеко не так однозначна, как видится вам, и что она зависит от точки зрения на проблему.
Извините, просто для определенности: вы сейчас как теоретик в вопросе говорите, или как практик?
Как практик, который за последние как минимум 6-7 лет видел и работал с кучей epic fail stories с использованием заказчиками дедупликации на первичных данных. Хотя и пары таких приключений с заказчиками в год вполне достаточно, что бы эйфория по поводу дедупа на первичных данных сильно спала. А потому имею мнение, что дедупу место в резервном копировании, а не на первичных данных.
Ну и на первичных данных дедуп может хоть как-то приемлемо работать только если есть SSD носители как минимум под хранение мета данных, а лучше под все. Но и это не избавляет от серьезных проблем с восстановлением работоспособности оборудования, не говоря уже про данные, в случае ряда специфических аварий.
Петабайтами "перед глазами" можно померятся, только практического смысла в этом нет.
Нет, просто все зависит от того, что вы считаете за 100% производительности. Если за 100% принимаем производительность заполненного тома (что логично), то тогда не полностю заполненный том дает значительный рост производительности.
Казуистика это все. И стаканы тут не причем.
А расскажите, на каких массивах?
Ну, хорошо, то есть по поводу использования онлайн-компрессии и erasure coding таких возражений нет. Отлично, мы продвигаемся. :) Не нравится вам по личным причинам дедупликация — можно без нее. Ну уж по поводу компрессии у вас не будет таких детских страхов? Технологии уже лет 30. Будем использовать ее для тог же самого. коэффициент 1.5 — 2.0 для данных достижим, по моим данным, процентах в 80 для несжатых предварительно данных. То есть, фактически, потерю емкости для двукратной копии при репликации с компрессией мы получаем назад.
> Казуистика это все.
Ну вот я тоже считаю, что ваш пример — казуистика. ;)
erasure coding и онлайн компрессия имеют свои плюсы и недостатки на медленных и больших дисках. Все сильно от реализации зависит.
Отлично, мы продвигаемся. :)
Не знаю куда вы там продвигаетесь и главное зачем? ;)
Но у нас с вами в очередной раз получается беседа человека, задействованного в продажах оборудования и человека, который занимается техподдержкой проданного, сталкиваясь со всем тем о чем заказчику при продаже умолчали или не дорассказали. Слишком разные points of view и похоже без шанса сойтись во мнениях.
За сим не вижу смысла в продолжении дискуссии, тем более что к теме статьи она уже имеет довольно опосредованное отношение.
Ну как-то у вас сейчас вообще пальцем в небо получилось. ;)
Да, возможно вы «техподдержка» и просто от этого взгляд ваш сильно ограничен узкими задачами техподдержки. Но в любом случае я рад, что удалось вас познакомить с реальным положением дел за пределами вашего небольшого круга компетенции. Вылезайте уже из техподдержки, мир изменился. :)
К сожалению, ваш мир единорогов срущих радугой, не имеет ни чего общего с объективной реальностью. Но поверьте, мне вас искренне жаль.
Так что в реальной жизни я рассчитывал бы на что-то ближе к неделе. А это много. Особенно если бекапа нет (а в домашних условиях бекапа всех 16 Тб нет с большой вероятностью, как бы неправильно это ни было).
там процессор и память на уровне смартфона, сколько у них это займёт?
Аппаратные бу рейды с R6 стоят гроши. У меня два h700 от делла, бонусом кеш cachecade на SSD — нашлось куда ткнуть 256gb ssd. Помимо собственного кеша на гиг. Вместе очень неплохо.
Собственный кэш на гиг батарейкой-то хоть защищен? Или на авось, как это часто бывает, используется?
У меня дома Adaptec 5805, даже с батарейкой. После замены аппаратного RAID-6 на ZFS RAID-Z2 на тех же самых дисках (подключенных к тому же Adaptec, но как simple volume), к слову, получил прирост скорости на чтение раза в 2, на запись в 1,5. Так что всё лучше домашнего NAS, но вот целесообразность покупки аппаратной карты вызывает сомнения. При прочих преимуществах ZFS к тому же.
Не очень понятно, как такое возможно, чтоб софтверные вычисления основной системой были быстрей риск-проца, который и по шине данные не гоняет лишний раз. Скорей всего у адаптека значимая логика в драйверах а в кремнии родовспоможение.
И тем более выйгрыш на чтении (!) за счет чего?
Подозреваю некое кеширование основной системой в оперативке — и завышенные данные тестов.
Дык тогда у вас нет питания или софтина крякнула — нет данных из этих самых 96 гиг. Тем более ресурс жрется в полный рост, и ядра проца греют вселенную и качают трафик по шине. В чем смысл? Если можно просто сменить контроллер на 6Gb (SAS 2.0) вместо 3gb(SAS 1.1) и получить честный прирост производительности. За условные 30-50 баксов.
Если уж что-то докупать и менять — то там у меня другой системный недостаток: один и тот же физический сервер работает и гипервизором, и СХД. Надо разделять, но это как-нибудь потом :)
Вообще-то SAS уже 12G.
Аппаратные бу рейды с R6 стоят гроши. У меня два h700 от делла, бонусом кеш cachecade на SSD — нашлось куда ткнуть 256gb ssd. Помимо собственного кеша на гиг. Вместе очень неплохо.
А они умеют работать с дисками объемом 16Тб? 256гб SSD можно воткнуть и разницы HDD/SSD им до лампочки. Но о существовании дисков 10Тб+ они явно не знают, и их производители 100% не закладывали в мануал информацию о совместимости с дисками такого объема. Так что с каждой железкой нужно будет опытным путём определять — сможет или не сможет.
Вероятно H700 с 16T не умеют. Дык было в качестве примера. Можно поискать посвежей.
Так что с каждой железкой нужно будет опытным путём определять — сможет или не сможет.
В смысле купить пачку новейших дисков по 500-600 долларов штука, тыщ на несколько и затем втыкать их в 40-долларовый контроллер 8 летней давности?
Вопрос в другом. Хочу зеленый поменять, на например на 12 тб диск. Будет ли работать с материнской платой на intel510MO? Вроде поддержка больших дисков идёт из операционной системы, а тут линукс и ему всё равно, но nm10 всё же не внугает доверия.
если хранилка нагружена, то вы такую скорость и получите.
Так что вечность, либо снижать нагрузку во время ребилда.
Там нет произвольного доступа, тупо линейно читаем все блоки от первого до последнего.
Про то что толстые диски используются только в архивах — это не так. Промышленные решения с ssd кешами перед дисками вполне себе существуют и продаются (всякие там netapp, vmware vsan и т.п.). Хотя я сейчас для хранилки корпоративного уровня вижу только флеш. Работал и с дисковыми хранилищами и с ssd+диски и с all-flash.
Может все же чтобы уменьшить время восстановления?
Дома? Увы, нет… Не та ценовая категория. Тут весь разговор начался с приведённых в статье рекомендаций по домашнему применению.
Я тоже так понял, и попытался намекнуть (вероятно, слишком тонко :( ), что рекомендовать домой для хранения <16 Тб данных один такой диск вместо RAID из более мелких — так себе рекомендация...
А там где диски лопатит 24/7 используют DDP/DRAID или вообще объектное хранилище, где такой проблемы не возникает.
Жёсткие диски сегодня почти полностью ушли с рынка бытовых компьютеров
Влажные мечты сигейта? С такой надежностью и стоимостью они не заместят старые-добрые HDD еще лет дцать. Платить 25к за то, чтобы утром проснуться и обнаружить, что потерял все данные при отличном смарт — нет уж, увольте… лучше я заплачу пять тыщ и буду юзать отличный жесткий диск от Hitachi пять же лет.
P.S. Ну и диски от сигейта брать можно только если данных не жаль… у сигейта и сверхнадеждые, по сути, HDD сыпались. Конторка хуже даже, чем WD, которые сами по себе таксебешные.
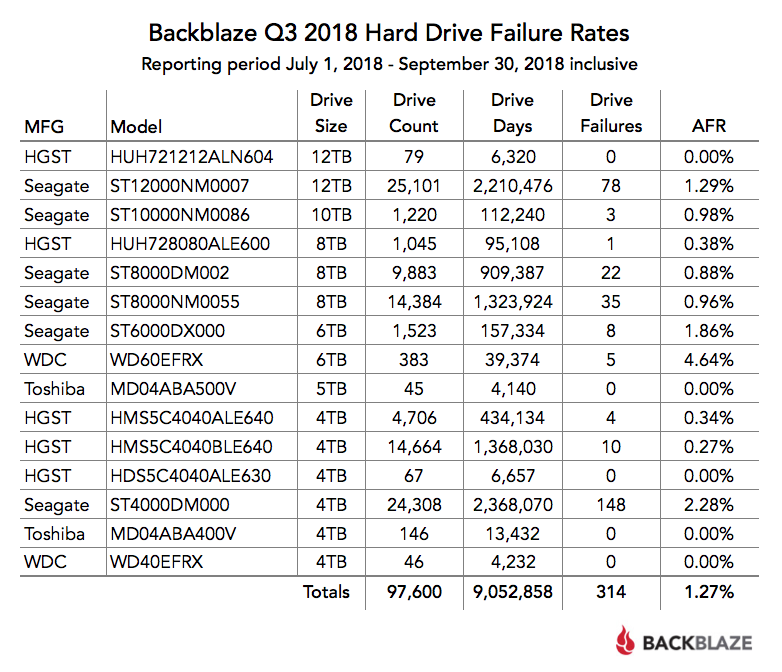
Неприятен большой разброс показателей надёжности у разных, хоть и родственных, моделей Seagate. А 2,28% — это весьма плохо. Хотя, бесспорно, 4,64 у WD ещё хуже.
Жёсткие диски сегодня почти полностью ушли с рынка бытовых компьютеров
Влажные мечты сигейта?
Чего это?
Они как раз в обратном заинтересованы — как можно дольше работать на том рынке.
HDD диски у меня успели умереть за этот срок.
Так что мой выбор — SSD под систему и все с чем работаешь, 2 HDD диска в зеркальном рейде под фильмы и т.п.
И на этот же рейд делается бэкап (через veeam agent) основной ssd (полные и инкрементальные бэкапы).
Новые диски SSD похоже хуже в плане выносливости. У меня при наличии SSD и диска под файлопомойку за год на SSD записано больше 17тб. Без жесткого диска скорее всего было бы больше раза в два как минимум.
Конторка хуже...Когда-то был стандарт индустрии де-факто. Подхватив выпавшее из рук IBM знамя, ага.
Нет, правда хорошие диски были. Муха це-це им стала первой ласточкой, извиняюсь за высокий штиль.
Когда-то был стандарт индустрии де-факто. Подхватив выпавшее из рук IBM знамя, ага.
Немного не так:
IBM — бизнес по производству жёстких дисков выкуплен Hitachi в 2002 г.
Hitachi Global Storage Technologies — куплена Western Digital в 2011 г. является дочерним предприятием Мощности по производству 3,5-дюймовых носителей были переданы Toshiba в 2012 году.
Диски IBM были впереди планеты всей по скорости и надежности. DJNA, DTTA, DPTA, DTLA… Ба-бах! Дятлы полетели, репутация полетела вдогонку — а тут заодно случилась тенденция избавляться от непрофильных активов. Поэтому производство и продали. Знамя выпало. От дисков Hitachi тоже долго шарахались по старой памяти.
Там еще рядышком по времени стоит такой же впечатляющий фейл от Fujitsu, которые MPG. Тоже избавились от производства в итоге.
а через 5 лет встанете перед выбором — WD, сигейт или тошибк. или SSD. потому что нет никакого хитачи, уже даже как wd-шного бренда.
Для бытовых ССД неумираемые, мой 256 диск живет 3 года и даже 10% не потратил.
Потом сильно не удивляйтесь, когда на 11% неубиваемого ресурса окажется что там внутри еще и контроллер есть и куча всего, что может внезапно сдохнуть даже во время перезагрузки.
Я еще не слышал о контроллере как об обычном способе смерти ССД,
См., например https://habr.com/ru/post/434702/
Причем, многие по словам возвращались к жизни — значит не отказ железа, а баги связаные сложно сказать с чем
«Что беспокоит меня больше всего по поводу этих резких отказов SSD – так это насколько они непонятны, и что я не могу сам себе объяснить, что именно пошло не так. Когда жёсткий диск крутится, он тоже может внезапно помереть, но, по крайней мере, можно составить объяснение того, что случилось перед этим – заклинило мотор, или случился другой физический отказ, приведший к резкому останову. SSD – твердотельные и таинственные, и у меня нет никаких объяснений тому, что пошло не так, особенно когда диск ещё молод и не должен был подходить к исчерпанию лимита жизни флэш-ячеек»
Жёсткие диски сегодня почти полностью ушли с рынка бытовых компьютеров
Эмм, что?
иное расположение монтажных отверстий снизу корпуса, что ограничивает его надёжный монтаж в некоторых видах корзин и NAS.
Это достаточно важный момент, что бы рассказать о нем подробнее (например, я использую систему с быстросъемными карманами, в которых диск крепится винтами снизу).
Как минимум нужно фото со стороны отверстий, нормально же — дать чертеж с габаритами и положением крепежных отверстий на корпусе.
Спасибо!
https://www.google.com/search?q=exos+x16+sata+product+manual
Первая ссылка, стр. 26 (27)
Ну что же вы, в самом деле. Пора уже учиться гуглить )

{kind=link}
для набирающих популярность SDS-решений на базе дешёвых white-label серверных платформ
О каких именно решениях речь?
- Произвольное чтение/запись 4K QD16 WCD (количество операций ввода-вывода в секунду): 170 IOPS / 440 IOPS
- Средняя задержка: 4,16 мс
Вопрос такой, потому как для семитысячника (7200 об/мин) они ни в какие ворота не лезут. Вот в тесте, результаты которого приведены в тексте статьи, характеристики получились вполне адекватные тому, что обычно предполагается для семитысячников: для произвольного доступа с блоком по размеру сектора (4КБ, как я понимаю) получилось 74 IOPS и ~13ms для времени доступа.
Поэтому хотелось бы узнать методику, по которой получены цифры из спецификации, чтобы понимать, что именно я не понимаю.
Через этот нипель гелий радостно улетучится, поэтому его и не делают. Но таки да, нужен замер давления гелия внутри диска, чтобы определить, когда диску хандец по причине потери среды.
это гарантия надёжного удержания гелия
Вот эта фраза, — целиком оксюморон. Интересно как долго гелий будет держаться в этом корпусе? Гарантия 5 лет? Если да, то вполне нормально.
Визуально он напоминает старые HDD (2Gb):

Что толку от объёма, если по статистике, Сигейты самые ненадёжные?
Ну HGST пробивает дно в плане надежности. Если Seagate набирает беды, то HGST с большей долей идет в отказ по механике.
В условиях борьбы за цену каждого гигабайта массив таких дисков будет хорошим подспорьем, ведь его рекомендуемая нами розничная цена — $629.
Топовые модели никогда не были про экономию — тут цена за терабайт на четверь выше, чем у дисков на 12 ТБ.
Крайне быстро сыпятся Сигейты, а также Хитачи и стали теперь и Тошибы, Самсунг и ВД пока самые живучие в плане долгожительству. Это чистая правда.
До окончания гарантии вылетело примерно 50% закупленных дисков. Поставщик менял их исключительно на refurbished, которые вылетали уже через пару месяцев. После окончания гарантии в течении около года ушло около 90% закупленных дисков. Причём диски были из нескольких разных партий. Диски самой первой партии продержались больше всего. А более поздние дохли очень быстро. Пару дней назад заменил самых долгожителей из тех партий.
Поэтому c грустью констатирую — «морским воротам» я больше не доверяю. Пруфы свалены в коробках. Хочется этими дисками сложить нехорошее слово и снять с квадрокоптера.
С другой стороны, в некоторых серверах у меня до сих пор крутятся сигейты в которых счётчик отработанных часов скоро переполнится второй раз. Умели же делать.
Но очень жаль что его не поймут сетевые хранилища, по крайней мере не все.
Диск на 16 тб точно домой покупать не нужно. Имхо такое увеличение объема идет только для сокрашение затрат площади, электричества и кондиционирования. Естественно это компромис. Между объемом и надежностью. Нормальным вариантом для дома считаю небольшой nas на 4-6 4 tb дисков с софтверным рейдом на соляре или ее форках. Надежная как танк. Действительно включил и забыл года на два. К тому скорость отдачи с такого рейда будет в разы больше чем с одного шпинделя. Плюс прелести zfs. Аппаратный рейд может тоже ничего, однако скорее для тех, кто может и имеет время их менять за недорого
В подобных случаях пользуйтесь недорогими накопителями с малой плотностьюА такие есть сейчас?
У меня были фантазии на тему: если б можно было на старые диски прицепить новую электронику (типа универсальной платы) и уменьшить плотность раз в 10, получился бы «вечный диск». Не всем нужны объёмы, я знаю пользователей, у которых за много лет диск заполнен на 10...20%.
Планка взята — новинка от Seagate для СХД