
Пожалуй, каждый разработчик программ для микроконтроллеров наверняка хотя бы раз слышал про специальные стандарты кодирования, призванные помочь повысить безопасность и переносимость вашего кода. Одним из таких стандартов является MISRA. В этой статье мы рассмотрим подробнее, что же представляет собой этот стандарт, какова его философия и как использовать его в ваших проектах.
Многие наши читатели слышали о том, что PVS-Studio поддерживает классификацию своих предупреждений согласно стандарту MISRA. На данный момент PVS-Studio покрывает более 100 правил MISRA C: 2012 и MISRA С++: 2008.
Данная статья имеет цель убить сразу трёх зайцев:
- Рассказать, что такое MISRA для тех, кто ещё не знаком с данным стандартом;
- Напомнить миру embedded-разработки о том, на что мы способны;
- Помочь глубже войти в курс дела новым сотрудникам, которые тоже будут в дальнейшем разрабатывать наш MISRA-анализатор;
Надеюсь, у меня получится сделать это интересно. Итак, приступим!
История появления MISRA
История MISRA началась достаточно давно. Тогда, в начале 90-x, правительственная программа Великобритании под показательным названием «Safe IT» выделяла финансирование для различных проектов, так или иначе связанных с безопасностью электронных систем. Сам проект MISRA (Motor Industry Software Reliability Association) был основан ради создания руководства по разработке ПО для микроконтроллеров в наземных транспортных средствах – в машинах, в общем.
Получив финансирование от государства, коллектив MISRA взялся за работу, и уже к ноябрю 1994 года выпустил своё первое руководство: "Development guidelines for vehicle based software". Это руководство еще не было привязано к конкретному языку, но должен признать: работа была проделана внушительная и касалась она, наверное, всех мыслимых аспектов разработки встраиваемого ПО. Кстати, недавно разработчики этого руководства отпраздновали 25-летие столь важной для них даты.
Когда финансирование от государства закончилось, члены MISRA решили продолжить работать вместе на неформальной основе – так продолжается и по сей день. По сути, MISRA (как организация) – это содружество заинтересованных сторон из различных авто- и авиастроительных индустрий. Сейчас этими сторонами являются:
- Bentley Motor Cars
- Ford Motor Company
- Jaguar Land Rover
- Delphi Diesel Systems
- HORIBA MIRA
- Protean Electric
- Visteon Engineering Services
- The University of Leeds
- Ricardo UK
- ZF TRW
Весьма сильные игроки рынка, не правда ли? Не удивительно, что их первый связанный с языком стандарт – MISRA C – стал общепринятым среди разработчиков критически важных встраиваемых систем. Чуть позже появился и MISRA C++. Постепенно версии стандартов обновлялись и дорабатывались, чтобы охватывать новые возможности языков. На момент написания этой статьи актуальными версиями являются MISRA C: 2012 и MISRA C++: 2008.
Философия и примеры правил
Самые отличительные черты MISRA – это невероятное внимание к деталям и крайняя дотошность в обеспечении безопасности. Авторы не просто собрали в одном месте все пришедшие в голову «дыры» C и C++ (как, например, авторы CERT) – они тщательно проработали международные стандарты этих языков и выписали все мыслимые и немыслимые способы ошибиться. А потом взяли и сверху дописали правил про читаемость кода – это чтобы в уже чистый код было сложнее внести новую ошибку.
Чтобы понять масштаб серьезности, рассмотрим несколько правил, взятых из стандарта.
С одной стороны, есть много хороших, годных правил, которым стоит следовать вообще всегда, независимо от того, для чего предназначен ваш проект. По большей части они призваны устранить неопределенное/неуточненное/зависимое_от_реализации поведение. Например:
- Не используйте значение неинициализированной переменной
- Не используйте указатель на FILE после закрытия потока
- Все non-void функции должны возвращать значение
- Счетчик цикла не должен иметь floating-point тип
- … и т.д.
С другой стороны, есть правила, польза которых лежит на поверхности, но которые (с точки зрения обыкновенных проектов) нарушить уже не так грешно:
- Не используйте goto и longjmp
- Каждый switch должен заканчиваться default
- Не пишите недостижимый код
- Не используйте вариативные функции
- Не используйте адресную арифметику (кроме [] и ++)
- ...
Такие правила тоже неплохи, и в сочетании с предыдущими уже дают ощутимый прирост к безопасности, но достаточно ли этого для высокоответственных встраиваемых систем? Они используются не только в автомобильной промышленности, но и в авиастроительной, аэрокосмической, военной, в медицинской.
Мы не хотим, чтобы из-за программной ошибки какой-нибудь рентгеновский аппарат облучал пациентов дозой в 20 000 рад, поэтому обычных «повседневных» правил уже недостаточно. На кону стоят человеческие жизни и огромные деньги, и необходимо включать дотошность. Здесь и выходят на сцену остальные правила MISRA:
- Суффикс 'L' в литерале всегда должен быть заглавным (маленькую 'l' можно перепутать с единичкой)
- Не используйте оператор «запятая» (она увеличивает шанс допустить ошибку)
- Не используйте рекурсию (небольшой по размеру стек микроконтроллера может легко переполниться)
- Тела операторов if, else, for, while, do, switch должны быть завернуты в фигурные скобки (потенциально можно допустить ошибку при неправильном выравнивании кода)
- Не используйте динамическую память (потому что есть шанс неудачного выделения её из кучи, особенно в микроконтроллерах)
- … и много, много таких правил.
Зачастую у людей, которые сталкиваются с MISRA, складывается мнение, что философия стандарта заключается в «запретить вон то и запретить вот это». На самом деле, это так, но лишь отчасти.
Да, стандарт действительно имеет много подобных правил, но его цель – не запретить всё возможное, а перечислить все-все-все способы как-то нарушить безопасность кода. Для большинства правил вы сами выбираете, стоит им следовать или нет. Объясню это дело поподробнее.
В MISRA C правила делятся на три основных категории: Mandatory, Required и Advisory. Mandatory – это правила, которые нельзя нарушать ни под каким предлогом. Например, в этот раздел входит правило «не используйте значение неинициализированной переменной». Required-правила менее строги: они допускают возможность отклонения, но только если эти отклонения тщательно документируются и письменно обосновываются. Остальные правила входят в категорию Advisory – это правила, которым следовать не обязательно.
В MISRA C++ немного по-другому: там отсутствует категория Mandatory, и большинство правил принадлежит к категории Required. Поэтому, по сути, вы имеете право нарушить любое правило – только не забывайте документировать отклонения. Также там есть категория Document – это обязательные к выполнению правила (отклонения не допускаются), которые связаны с общими практиками вроде «Каждое использование ассемблера должно быть задокументировано» или «подключаемая библиотека должна соответствовать MISRA C++».
Что еще есть
На самом деле, MISRA состоит не только из набора правил. По сути, это методичка по написанию безопасного кода для микроконтроллеров, и поэтому там полно всяких полезностей. Давайте же рассмотрим их детально.
Во-первых, стандарт содержит достаточно тщательное описание подоплёки: ради чего создавался стандарт, почему был выбран именно C или C++, достоинства и недостатки этих языков.
Про достоинства этих языков мы прекрасно знаем. Да и про недостатки, в общем-то, тоже :) Чего только стоят высокая сложность, неполная спецификация стандартом и синтаксис, позволяющий ну очень легко ошибиться, а потом долго искать ошибку. Например, можно случайно написать так:
for (int i = 0; i < n; ++i);
{
do_something();
}Всё-таки есть шанс, что человек не заметит лишней точки с запятой, верно? Еще можно написать вот так:
void SpendTime(bool doWantToKillPeople)
{
if (doWantToKillPeople = true)
{
StartNuclearWar();
}
else
{
PlayComputerGames();
}
}Хорошо, что и первый, и второй случай легко отлавливаются правилами MISRA (первое — MISRA C: 13.4/MISRA C++: 6.2.1, второе — MISRA C: 13.4/MISRA C++: 6.2.1).
Помимо описания проблематики, в стандарте содержится большое количество советов о том, что нужно знать перед началом работы: о том, как наладить процесс разработки по MISRA, об использовании статических анализаторов для проверки кода на соответствие, о том, какие документы нужно вести, как их заполнять, и так далее и тому подобное.
Также в конце имеются приложения, в которых содержатся: краткий список и сводная таблица правил, небольшой перечень уязвимостей C/С++, пример документации отклонения от правила, а также несколько чек-листов, призванных помочь вам не запутаться во всей этой бюрократии.
Как видите, MISRA – это не просто набор правил, а практически целая инфраструктура по написанию безопасного кода для встраиваемых систем.
Использование в ваших проектах
Представим ситуацию: вы собрались написать программу для какой-нибудь очень нужной и ответственной встраиваемой системы. Или у вас уже есть программа, но её нужно «перенести» на MISRA. Как же проверять ваш код на соответствие стандарту? Неужели придется делать это вручную?
Ручная проверка кода – занятие непростое и потенциально невыполнимое. Мало того, что каждому ревьюверу пришлось бы тщательно высматривать каждую строчку кода, так еще и знать стандарт придется чуть ли не наизусть. Ужас!
Поэтому сами разработчики MISRA для проверки вашего кода советуют использовать статический анализ. Ведь, по сути, статический анализ – это автоматизированный процесс code review. Вы просто запускаете анализатор на вашей программе и через несколько минут получаете отчет о потенциальных нарушениях стандарта. То, что нужно, ведь так? Вам останется лишь просмотреть лог и исправить срабатывания.
Следующий вопрос: в какой момент начинать использовать MISRA? Ответ простой: чем раньше, тем лучше. В идеале – до того, как вы вообще начнёте писать код, потому что MISRA предполагает следование стандарту в течение всей жизни вашего кода.
Конечно, не всегда имеется возможность писать по MISRA с самого начала. Например, часто бывает, что проект уже частично или полностью реализован, но заказчик пожелал, чтобы проект соответствовал стандарту. В таком случае вам придется заняться основательным рефакторингом уже имеющегося кода.
Вот тут-то и всплывает подводный камень. Я бы даже сказал, всплывает подводный валун. Что будет, если вы возьмёте статический анализатор и проверите «обыкновенный» проект на соответствие стандарту MISRA? Спойлер: вы можете испугаться.
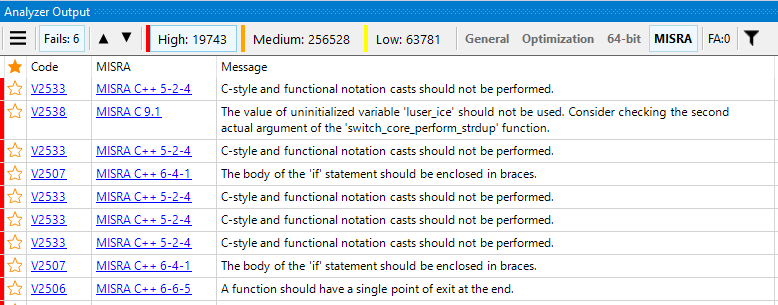
Конечно, пример на картинке преувеличен. Здесь показан результат проверки достаточного большого проекта, который на самом деле никогда и не задумывался для работы на микроконтроллерах. Тем не менее, при проверке уже имеющегося кода вы вполне можете увидеть одну, две, пять, а то и десять тысяч срабатываний анализатора. И во всей этой куче будут теряться новые срабатывания, которые были выданы на только что написанный или изменённый код.
Что же с этим делать? Неужели придется отложить все дела и сесть за исправление всех старых срабатываний?
Мы знаем, что при первой проверке проекта достаточно часто появляется много срабатываний, и разработали решение, которое поможет вам получать пользу от анализатора сразу, не останавливая работу. Называется это решение «suppress-базы».
Suppress-базы – это механизм PVS-Studio, который позволяет массово подавить сообщения анализатора. Если вы впервые проверяете проект и обнаруживаете там несколько тысяч срабатываний – вы просто добавляете их в suppress-базу, и при следующем прогоне анализатор выдаст вам ноль предупреждений.
Таким образом, вы сможете продолжить писать и изменять код в обычном режиме, и при этом будете видеть предупреждения только о тех ошибках, которые были внесены в проект только что. При этом вы будете получать максимальную пользу от анализатора сразу здесь и сейчас, не отвлекаясь на разгребание старых ошибок. Несколько кликов – и анализатор внедрен! Почитать подробную инструкцию об этом вы можете здесь.
У вас наверняка может возникнуть вопрос: «Подождите, а что делать со спрятанными срабатываниями?» Ответ довольно простой: не забывать о них и потихонечку исправлять. Можно, например, заложить suppress-базу в систему контроля версий и допускать только те коммиты, которые не увеличивают количество срабатываний. Таким образом, постепенно ваш «подводный валун» рано или поздно сточится и от него не останется и следа.
Окей, анализатор внедрен и теперь мы готовы продолжать. Что делать дальше? Понятное дело – работать с кодом. Но что нужно, чтобы можно было заявить о соответствии стандарту? Как доказать, что ваш проект соответствует MISRA?
Дело в том, что не существует какого-то специального «аттестата» о том, что ваш код соответствует MISRA. Как оговаривает сам стандарт, отслеживание кода на соответствие должно выполняться двумя сторонами: заказчиком ПО и поставщиком ПО. Поставщик разрабатывает ПО, соответствующее стандарту, и заполняет необходимые документы. Заказчик же со своей стороны должен удостовериться, что данные из этих документов соответствуют действительности.
Если же вы сами являетесь и заказчиком, и разработчиком собственного ПО, то ответственность за соответствие стандарту будет лежать только на ваших плечах :)
В общем, для доказательства соответствия вашего проекта вам понадобятся документы-пруфы. Список документов, которые должны подготовить разработчики проекта, может варьироваться, но MISRA предлагает некоторый набор в качестве эталонного. Рассмотрим этот набор поподробнее.
Для заявления о соответствии стандарту вам понадобится несколько вещей:
- Собственно проект, код которого соответствует Mandatory и Required правилам
- План обеспечения соответствия (guide enforcement plan)
- Документация по всем предупреждениям компиляторов и статических анализаторов
- Документация по всем отклонениям от Required-правил
- Резюме о соответствии правилам (guideline compliance summary)
Первый из них – план обеспечения соответствия. Это ваша самая главная таблица, и именно она будет отсылать проверяющего ко всем остальным документам. В первом её столбике находится список MISRA-правил, в остальных – отмечается, были ли выявлены какие-то отклонения от этих правил. Выглядит эта таблица примерно так:
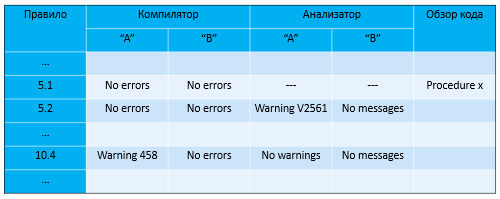
Стандарт рекомендует собирать ваш проект несколькими компиляторами, а также использовать два и более статических анализатора для проверки вашего кода на соответствие. Если компилятор или анализатор выдает какое-то предупреждение, связанное с правилом – вы должны отметить это в таблице и задокументировать: почему срабатывание нельзя устранить, является ли оно ложным, и т.д.
Если какое-то из правил нельзя проверить статическим анализатором, то вам необходимо провести процедуру code review. Эта процедура также должна быть задокументирована, после чего в план обеспечения соответствия должна быть добавлена ссылка на эту документацию.
Если компилятор или статический анализатор оказываются правы, или если в процессе code review обнаружились действительные нарушения правила, то вы должны либо исправить их, либо задокументировать. Опять же, прикрепив ссылку на документацию в таблицу.
Таким образом, план обеспечения соответствия – это документ, по которому можно будет найти документацию к любому отклонению, выявленному в вашем коде.
Теперь немного про саму документацию отклонений от правил. Как я уже упомянул, такая документация необходима только для Required-правил, потому что правила уровня Mandatory нарушать нельзя, а Advisory-правилам можно не следовать и без всякой документации.
Если вы решили отклониться от правила, то документация должна содержать:
- Номер нарушенного правила
- Точную локацию отклонения
- Обоснованность отклонения
- Доказательство того, что отклонение не нарушает безопасность
- Потенциальные последствия для пользователя
Как видите, такой подход к документации заставляет серьезно задуматься, стоит ли нарушение того. Это сделано специально, чтобы нарушать Required-правила было неповадно :)
Теперь про резюме о соответствии правилам. Эту бумагу, пожалуй, будет заполнить легче всего:
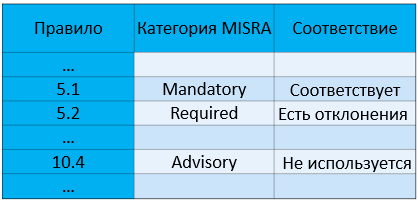
Центральный столбик заполняется до того, как приступить к работе с кодом, а самый правый – после того, как ваш проект готов.
Вполне резонно задать вопрос: зачем нужно указывать категории правил, если они уже указаны в самом стандарте? Дело в том, что стандарт допускает «повышение» правила в более строгую категорию. Например, заказчик может попросить вас перенести какое-нибудь Advisory-правило в категорию. Такое «повышение» должно быть сделано до работы с кодом, и резюме о соответствии правилам позволяет явно это отметить.
С последним столбиком всё просто: достаточно только отметить, используется ли правило, и если да, то имеются ли от него отклонения.
Вся эта таблица нужна для того, чтобы можно было быстро посмотреть, какие приоритеты имеют правила, и соответствует ли им код. Если вам вдруг станет интересно узнать точную причину отклонения, вы всегда можете обратиться к плану обеспечения соответствия и найти нужную вам документацию.

Итак, вы написали код, тщательно следуя правилам MISRA. Вы составили план обеспечения соответствия и задокументировали всё, что можно было задокументировать, а также заполнили резюме о соответствии правилам. Если это действительно так, то вы получили очень чистый, очень читаемый и очень надёжный код, который вы теперь ненавидите :)
Где теперь будет жить ваша программа? В аппарате МРТ? В обыкновенном датчике скорости или в системе автопилота какого-нибудь космического спутника? Да, вы прошли через серьёзный бюрократический путь, но это – мелочи. Разве можно не быть дотошным, когда на кону стоят настоящие человеческие жизни?
Если вы справились и смогли дойти до победного конца, то я искренне вас поздравляю: вы пишете качественный безопасный код. Спасибо!
Будущее стандартов
Напоследок хочется немного рассказать о будущем стандартов.
На данный момент MISRA живёт и развивается. Например, в начале 2019 года был анонсирован «The MISRA C:2012 Third Edition (First Revision)» – обновленный и дополненный новыми правилами стандарт 2012 года. Тогда же объявили о грядущем выходе «MISRA C:2012 Amendment 2 – C11 Core» – стандарте 2012 года, в который будут добавлены правила, впервые охватывающие версии языка Си 2011 и 2018 годов.
Не стоит на месте и MISRA C++. Как известно, последний стандарт MISRA C++ датируется 2008 годом, поэтому наиболее старшая версия языка, которую он охватывает – это C++03. Из-за этого появился еще один стандарт, аналогичный MISRA, и называется он AUTOSAR C++. Он изначально задумывался как продолжение MISRA С++ и имел своей целью охватить более поздние версии языка. В отличие от своего вдохновителя, AUTOSAR C++ обновляется два раза в год и на данный момент поддерживает C++14. Планируется дальнейшее обновление до C++17, а затем C++20, и так далее.
К чему я начал про какой-то другой стандарт? Дело в том, что чуть меньше года назад обе организации объявили об объединении своих стандартов в один. Теперь MISRA C++ и AUTOSAR C++ станут единым стандартом, и теперь они будут развиваться вместе. Я думаю, это отличная новость для разработчиков, пишущих под микроконтроллеры на C++, и не менее отличная новость для разработчиков статических анализаторов. Любимой работы наперёд еще много! :)
Заключение
Сегодня мы с вами многое узнали про MISRA: почитали историю её возникновения, изучили примеры правил и философию стандарта, рассмотрели всё необходимое для использования MISRA в ваших проектах, и даже немного заглянули в будущее. Надеюсь, теперь вы лучше понимаете, что такое MISRA и как её готовить!
По старой традиции оставлю здесь ссылку на наш статический анализатор PVS-Studio. Он способен находить не только отклонения от стандарта MISRA, но еще и огромнейший спектр ошибок и уязвимостей. Если вам интересно самостоятельно попробовать PVS-Studio – скачайте демонстрационную версию и проверьте свой проект.
На этом моя статья подходит к концу. Желаю всем читателям счастливого Нового года и веселых новогодних выходных!
Дополнительные ссылки
- Георгий Грибков – "Безопасность на максималках — как писать надежный C/C++ код для встраиваемых систем".
- PVS-Studio — статический анализатор кода.
- PVS-Studio & KEIL 5 совместная работа.

Если хотите поделиться этой статьей с англоязычной аудиторией, то прошу использовать ссылку на перевод: George Gribkov. What Is MISRA and how to Cook It.
