На сегодняшний день трудно найти человека, который хоть раз в жизни не сталкивался прямым или косвенным образом с распознаванием документов. Действительно, когда в мире для совершения любого сколь угодно серьезного дела необходима идентификация личности мы то и дело слышим «Можно ваш паспорт», чтобы очередной раз ввести ваши данные в компьютер с целью проверки разрешен ли вам вход, нет ли каких-либо неоплаченных долгов и так далее.
Конечно, мимо такой хорошо поставленной задачи в наш век глобальной автоматизации не могли пройти гиганты в области распознавания данных. На сегодняшний день существует множество различных программ и аппаратно-программных комплексов (как от крупных компаний, так и от относительно новых на этом рынке игроков), которые позволяют решить эту конкретную практическую задачу. При этом, несмотря на локальные отличия всех предлагаемых решений (кто-то лучше распознает, у кого-то более продуманный и современный интерфейс, кто-то более прост и понятен в интеграции, кто-то подешевле или подороже) глобально все существующие ПО решают задачу одинаково: получение изображения паспорта с помощью сканера и последующее распознавание на персональном компьютере. В результате такой подход позволяет ввести паспортные данные от 2 до 26 секунд (в зависимости от производительности сканера), что в разы-десятки раз быстрее и надежнее по сравнению ручным вводом.
Казалось бы, задача решена! Но как часто мы видим такие «умные» решения по распознаванию паспортов в жизни? Увы, в почтовых отделениях, многих банках и даже отделениях полиции (которые имеют дело с паспортами, наверное, чаще, чем кто-либо другой) до сих пор ввод паспортных данных осуществляется в ручном режиме. В чем же тут камень преткновения? Почему столь надежное и качественное решение конкретной прикладной задачи не используются повсеместно?
Чтобы понять суть проблемы, обратимся к другому примеру развития инновационной технологии, не имеющего прямого отношения к задачам распознавания – цифровой фотографии. Давайте вспомним 90-е годы, когда на рынке начали появляться первые потребительские цифровые фотоаппараты. Казалось бы, вот оно счастье: никакой пленки, мгновенный просмотр сделанных снимков, простота хранения фотографий – снимай и снимай себе в удовольствие все подряд. На практике же люди в большинстве своем, как и прежде, пользовались фотоаппаратами не слишком часто: на отдыхе, торжествах и памятных событиях. Зато настоящий бум фотографии произошел в момент появления фотокамеры в смартфоне. Цифровая фотография сразу зажила второй жизнью и обрела громадную популярность. И такую же учесть пережили многие другие технологии в совершенно разных областях: карты и навигация, Wi-Fi, социальные сети и многое другое.
Вернемся теперь к распознаванию документов и попробуем провести параллель. Может быть небольшая популярность систем распознавания паспорта связана именно с неудобством самого процесса, а не с качеством? Действительно, трудно представить участкового полиции, разложившего на газоне ноутбук и сканер и проверяющего документы у мигранта. Совсем другое дело, если бы распознать и проверить паспорт можно было бы прямо в руках с помощью какого-нибудь компактного подручного устройства (например, смартфона). Так у нас родилась идея написать программу распознавания ID-документов для мобильного телефона. И конечно, начать мы решили с распознавания паспорта гражданина РФ.

Чтобы дальше было интереснее читать, покажем наше приложение в действии. Федеральный закон 152-ФЗ запрещает нам публиковать изображения настоящих паспортов. Поэтому, для демонстрационных целей используется распечатанное с Википедии синтезированное изображение паспорта.
Итак, финальная цель – распознать паспорт гражданина РФ на мобильнике. Но в такой постановке задача звучит очень расплывчато. Давайте уточним суть задачи, задав ограничения «по осям», сформировав некоторое подобие технических требований.
Целевая платформа. Необходимо приложение, способное работать на современных Android-устройствах, а также Apple iPhone версии не ниже 5s. Такие ограничения появились после анализа текущей ситуации на рынке мобильных устройств. При этом важным элементом является написание именно распознающей на мобильном устройстве программы, а не программы-прослойки, которая получает изображения, отправляет картинки в облако и получает назад результат. И дело тут совсем не в медленном мобильном интернете, как может показаться на первый взгляд. Просто у нас в стране во всю действует федеральный закон «О персональных данных» (152-ФЗ), который строго регулирует деятельность по обработке персональных данных. В соответствии с законом, в России существенно возрастают требования ко всем частным и государственным компаниям и организациям, а также физическим лицам, которые хранят, собирают, передают или обрабатывают персональные данные (в том числе фамилию, имя, отчество). Поэтому с точки зрения закона чем быстрее любая распознающая программа забудет персональные данные, тем лучше (и уж тем более не стоит никуда отправлять ни сами данные, ни изображения паспорта).
Объект распознавания. В большинстве прикладных задач клиенту в основном требуются серия-номер паспорта, фотография, фамилия, имя, отчество, пол и дата рождения. Все эти данные расположены на третьей (в соответствии с нумерацией) странице паспорта. Поэтому решим вначале задачу распознавания указанных выше «основных» полей. То есть будем решать задачу распознавания третьей страницы паспорта РФ.
Входные данные. В отличии от классического подхода (распознавание отсканированного изображения) смартфон позволяет получить видеопоследовательность. Объединение результатов распознавания информации с разных кадров позволяет существенно поднять качество работы системы в целом. Правда это преимущество справедливо только при условии, что удается очень быстро обрабатывать` отдельные кадры, что плавно нас переводит к вопросу о производительности.
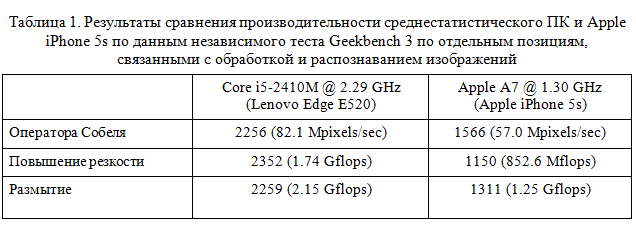
Производительность. По заявлениям конкурентов, на сегодняшний день лучшие ПО распознавания паспорта справляются с этой задачей примерно за 1-3 секунды на компьютере средней производительности, без учета сканирования. Поэтому мы поставили себе цель решить данную задачу на мобильнике не медленнее чем за 3 секунды. При этом мы хотим обрабатывать данные со скоростью не менее трех кадров в секунду на устройствах типа Apple iPhone 5s. Другими словами, среднее время обработки одного кадра не должно превышать 0.3 секунды. Если вспомнить, что 1 кадр состоит примерно из 2 миллионов пикселей, а распознавание производится на устройствах значительно слабее средненького ПК (см. таблицу 1), то задача более чем нерешаемой. Признаюсь, нам пришлось немало попотеть во время оптимизации кода и разработкой быстрых алгоритмов прежде чем мы добились такой скорости. Позже мы напишем отдельный пост про подходы оптимизации распознающих программ на мобильных устройствах. Сейчас могу лишь только вспомнить: год назад на это смелое заявление о скорости мы дружно ответили «Challenge accepted».
Качество. Качество распознавания часто является решающим фактором при выборе той или иной системы. Поэтому в самом начале разработки мы поставили себе довольно высокую планку – в первой версии продукта 95% паспортов должны распознаваться правильно (исключая паспорта, которые не могут быть распознаны автоматически). Вообще оценка качества подобных распознающих систем – серьезная задача, про которую мы хотим рассказать в будущих постах на Хабре.
Как неоднократно подчеркивали наши коллеги из различных организаций, задача распознавания Паспорта РФ чрезвычайно сложна. Причем сложность вызвана как различными защитными элементами самого бланка паспорта (гильоширный фон, голографические элементы, наличие глянцевой пленки), так и высокой вариативностью заполнения (неаккуратная печать персональных данных, использование нестандартных шрифтов, наличие механических повреждений).
Однако, при распознавании паспорта на телефоне ко всем указанным выше проблемам добавляются принципиально новые, ранее не встречающиеся при работе со сканером:
Помимо новых проблем, «всплывающих» на этапе получения изображения, не менее серьезные трудности ожидают нас далее. Так, например, актуальной становится задача грубой локализации и идентификации документа в кадре. Ведь в отличии от отсканированного образа, при распознавании видеопоследовательности надо быть уверенным, что на очередном кадре присутствует целевой документ. При этом, решать эту задачу обычно надо до проективной нормализации.
Двигаемся дальше. Для точного позиционирования текстовых строк необходимо найти границы паспорта и определить проективный базис. Для этого требуется в условиях шума выделить линейные границы, углы, скругления и прочие примитивы; сгенерировать и выбрать варианты границ документа, наиболее соответствующие модели. После определения проективного базиса необходимо проективно исправить зону изображения, произвести позиционирование полей.
Теперь мы готовы к распознаванию. Для распознавания данных требуются специальные методы оптического распознавания, как отдельных символов, так и текстовых фрагментов. Особенностью обработки видеопотока является достаточно низкое исходное разрешение (не превышающее 150-200 DPI) при наличии помех и искажений, в частности бликов и засветки, дефокусировки изображения и смазывания.
После того, как будут успешно преодолены все трудности, связанные с обработкой отдельного кадра, появляются новые задачи, связанные с распознаванием всей видеопоследовательности – это контекстный анализ и интеграция результатов. Эта тема очень интересна, и мы обязательно посвятим ей ни одну статью в будущих постах. Пока лишь ограничимся анонсированием существования таких задач.
Таким образом, решая по-новому, казалось бы, «простую» задачу, распознавание паспорта гражданина РФ, мы столкнулись не с одним десятком интересных задач как в области компьютерного зрения, так и в области архитектуры эффективного ПО и написания высокопроизводительных программ для мобильных устройств.
Данный пост носит скорее вводный характер и повествует дорогим читателям в целом о наших задачах, проблемах, интересах. О конкретных научных и технических достижений мы обязательно продолжим серию публикаций на Хабре, в которых расскажем о решениях отдельных подзадач распознавания документов (и не только) на мобильных устройствах.
Что же касается готового решения по распознаванию паспорта РФ на мобильном устройстве, мы с радостью хотим сообщить, скачать Demo-программу распознавания для Android можно уже сейчас (Smart PassportReader в Google play) и для iOS (Smart PassportReader в App Store). А если по роду деятельности вам интересно SDK нашего продукта, чтобы живьем «потрогать» и попробовать встроить в свои мобильные приложения – напишите нам на support@smartengines.biz и мы с удовольствием расскажем, как это сделать, а также ответим на другие интересующие Вас вопросы.
И в самом конце несколько скриншотов нашей программы для Apple iPhone
Конечно, мимо такой хорошо поставленной задачи в наш век глобальной автоматизации не могли пройти гиганты в области распознавания данных. На сегодняшний день существует множество различных программ и аппаратно-программных комплексов (как от крупных компаний, так и от относительно новых на этом рынке игроков), которые позволяют решить эту конкретную практическую задачу. При этом, несмотря на локальные отличия всех предлагаемых решений (кто-то лучше распознает, у кого-то более продуманный и современный интерфейс, кто-то более прост и понятен в интеграции, кто-то подешевле или подороже) глобально все существующие ПО решают задачу одинаково: получение изображения паспорта с помощью сканера и последующее распознавание на персональном компьютере. В результате такой подход позволяет ввести паспортные данные от 2 до 26 секунд (в зависимости от производительности сканера), что в разы-десятки раз быстрее и надежнее по сравнению ручным вводом.
Казалось бы, задача решена! Но как часто мы видим такие «умные» решения по распознаванию паспортов в жизни? Увы, в почтовых отделениях, многих банках и даже отделениях полиции (которые имеют дело с паспортами, наверное, чаще, чем кто-либо другой) до сих пор ввод паспортных данных осуществляется в ручном режиме. В чем же тут камень преткновения? Почему столь надежное и качественное решение конкретной прикладной задачи не используются повсеместно?
Чтобы понять суть проблемы, обратимся к другому примеру развития инновационной технологии, не имеющего прямого отношения к задачам распознавания – цифровой фотографии. Давайте вспомним 90-е годы, когда на рынке начали появляться первые потребительские цифровые фотоаппараты. Казалось бы, вот оно счастье: никакой пленки, мгновенный просмотр сделанных снимков, простота хранения фотографий – снимай и снимай себе в удовольствие все подряд. На практике же люди в большинстве своем, как и прежде, пользовались фотоаппаратами не слишком часто: на отдыхе, торжествах и памятных событиях. Зато настоящий бум фотографии произошел в момент появления фотокамеры в смартфоне. Цифровая фотография сразу зажила второй жизнью и обрела громадную популярность. И такую же учесть пережили многие другие технологии в совершенно разных областях: карты и навигация, Wi-Fi, социальные сети и многое другое.
Вернемся теперь к распознаванию документов и попробуем провести параллель. Может быть небольшая популярность систем распознавания паспорта связана именно с неудобством самого процесса, а не с качеством? Действительно, трудно представить участкового полиции, разложившего на газоне ноутбук и сканер и проверяющего документы у мигранта. Совсем другое дело, если бы распознать и проверить паспорт можно было бы прямо в руках с помощью какого-нибудь компактного подручного устройства (например, смартфона). Так у нас родилась идея написать программу распознавания ID-документов для мобильного телефона. И конечно, начать мы решили с распознавания паспорта гражданина РФ.
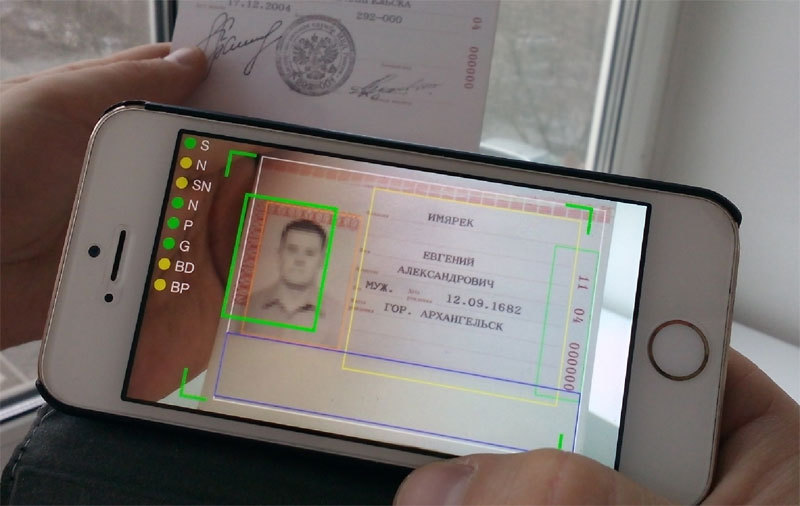
Чтобы дальше было интереснее читать, покажем наше приложение в действии. Федеральный закон 152-ФЗ запрещает нам публиковать изображения настоящих паспортов. Поэтому, для демонстрационных целей используется распечатанное с Википедии синтезированное изображение паспорта.
Постановка задачи
Итак, финальная цель – распознать паспорт гражданина РФ на мобильнике. Но в такой постановке задача звучит очень расплывчато. Давайте уточним суть задачи, задав ограничения «по осям», сформировав некоторое подобие технических требований.
Целевая платформа. Необходимо приложение, способное работать на современных Android-устройствах, а также Apple iPhone версии не ниже 5s. Такие ограничения появились после анализа текущей ситуации на рынке мобильных устройств. При этом важным элементом является написание именно распознающей на мобильном устройстве программы, а не программы-прослойки, которая получает изображения, отправляет картинки в облако и получает назад результат. И дело тут совсем не в медленном мобильном интернете, как может показаться на первый взгляд. Просто у нас в стране во всю действует федеральный закон «О персональных данных» (152-ФЗ), который строго регулирует деятельность по обработке персональных данных. В соответствии с законом, в России существенно возрастают требования ко всем частным и государственным компаниям и организациям, а также физическим лицам, которые хранят, собирают, передают или обрабатывают персональные данные (в том числе фамилию, имя, отчество). Поэтому с точки зрения закона чем быстрее любая распознающая программа забудет персональные данные, тем лучше (и уж тем более не стоит никуда отправлять ни сами данные, ни изображения паспорта).
Объект распознавания. В большинстве прикладных задач клиенту в основном требуются серия-номер паспорта, фотография, фамилия, имя, отчество, пол и дата рождения. Все эти данные расположены на третьей (в соответствии с нумерацией) странице паспорта. Поэтому решим вначале задачу распознавания указанных выше «основных» полей. То есть будем решать задачу распознавания третьей страницы паспорта РФ.
Входные данные. В отличии от классического подхода (распознавание отсканированного изображения) смартфон позволяет получить видеопоследовательность. Объединение результатов распознавания информации с разных кадров позволяет существенно поднять качество работы системы в целом. Правда это преимущество справедливо только при условии, что удается очень быстро обрабатывать` отдельные кадры, что плавно нас переводит к вопросу о производительности.
Производительность. По заявлениям конкурентов, на сегодняшний день лучшие ПО распознавания паспорта справляются с этой задачей примерно за 1-3 секунды на компьютере средней производительности, без учета сканирования. Поэтому мы поставили себе цель решить данную задачу на мобильнике не медленнее чем за 3 секунды. При этом мы хотим обрабатывать данные со скоростью не менее трех кадров в секунду на устройствах типа Apple iPhone 5s. Другими словами, среднее время обработки одного кадра не должно превышать 0.3 секунды. Если вспомнить, что 1 кадр состоит примерно из 2 миллионов пикселей, а распознавание производится на устройствах значительно слабее средненького ПК (см. таблицу 1), то задача более чем нерешаемой. Признаюсь, нам пришлось немало попотеть во время оптимизации кода и разработкой быстрых алгоритмов прежде чем мы добились такой скорости. Позже мы напишем отдельный пост про подходы оптимизации распознающих программ на мобильных устройствах. Сейчас могу лишь только вспомнить: год назад на это смелое заявление о скорости мы дружно ответили «Challenge accepted».
Качество. Качество распознавания часто является решающим фактором при выборе той или иной системы. Поэтому в самом начале разработки мы поставили себе довольно высокую планку – в первой версии продукта 95% паспортов должны распознаваться правильно (исключая паспорта, которые не могут быть распознаны автоматически). Вообще оценка качества подобных распознающих систем – серьезная задача, про которую мы хотим рассказать в будущих постах на Хабре.
Новые проблемы при распознавании на смартфоне
Как неоднократно подчеркивали наши коллеги из различных организаций, задача распознавания Паспорта РФ чрезвычайно сложна. Причем сложность вызвана как различными защитными элементами самого бланка паспорта (гильоширный фон, голографические элементы, наличие глянцевой пленки), так и высокой вариативностью заполнения (неаккуратная печать персональных данных, использование нестандартных шрифтов, наличие механических повреждений).
Однако, при распознавании паспорта на телефоне ко всем указанным выше проблемам добавляются принципиально новые, ранее не встречающиеся при работе со сканером:
- Проективное искажение изображения документа. При съемке камерой углы и их отношения, а также пропорции объектов изменяются в зависимости от ракурса съемки. Это приводит к тому, что классические алгоритмы (поиск опорных линий, выделения текстовых полей и прочие) не могут применяться напрямую, а требуют предварительной проективной нормализации изображения.
- Блики. Глянцевая пленка, голограммы и прочие элементы защиты, которые помогают нам отличить настоящий паспорт от поддельного, очень сильно мешают при распознавании (частично уничтожая информацию). Попробуйте посмотрите на свой паспорт даже через объектив фотоаппарата (например, с помощью стандартного приложения камеры вашего смартфона) под разными углами, и вы сразу поймете всю глубину проблемы.
- Неравномерность освещения. В отличии от сканера, где используется свой осветитель, при фотографировании документа свет поступает от внешних источников неконтролируемым образом. Отсюда возникает еще ряд таких проблем, как тени и неточность передачи цвета.
- Дефокусировка и смазывание. Возникает из-за постоянного смещения камеры во время распознавания (ведь съемка идет без использования штатива).
- Цифровой шум. Часто возникает в ситуации недостаточной освещенности. При этом, чем меньше освещенность, тем больше усиливается влияние цифрового шума.
Помимо новых проблем, «всплывающих» на этапе получения изображения, не менее серьезные трудности ожидают нас далее. Так, например, актуальной становится задача грубой локализации и идентификации документа в кадре. Ведь в отличии от отсканированного образа, при распознавании видеопоследовательности надо быть уверенным, что на очередном кадре присутствует целевой документ. При этом, решать эту задачу обычно надо до проективной нормализации.
Двигаемся дальше. Для точного позиционирования текстовых строк необходимо найти границы паспорта и определить проективный базис. Для этого требуется в условиях шума выделить линейные границы, углы, скругления и прочие примитивы; сгенерировать и выбрать варианты границ документа, наиболее соответствующие модели. После определения проективного базиса необходимо проективно исправить зону изображения, произвести позиционирование полей.
Теперь мы готовы к распознаванию. Для распознавания данных требуются специальные методы оптического распознавания, как отдельных символов, так и текстовых фрагментов. Особенностью обработки видеопотока является достаточно низкое исходное разрешение (не превышающее 150-200 DPI) при наличии помех и искажений, в частности бликов и засветки, дефокусировки изображения и смазывания.
После того, как будут успешно преодолены все трудности, связанные с обработкой отдельного кадра, появляются новые задачи, связанные с распознаванием всей видеопоследовательности – это контекстный анализ и интеграция результатов. Эта тема очень интересна, и мы обязательно посвятим ей ни одну статью в будущих постах. Пока лишь ограничимся анонсированием существования таких задач.
Заключение
Таким образом, решая по-новому, казалось бы, «простую» задачу, распознавание паспорта гражданина РФ, мы столкнулись не с одним десятком интересных задач как в области компьютерного зрения, так и в области архитектуры эффективного ПО и написания высокопроизводительных программ для мобильных устройств.
Данный пост носит скорее вводный характер и повествует дорогим читателям в целом о наших задачах, проблемах, интересах. О конкретных научных и технических достижений мы обязательно продолжим серию публикаций на Хабре, в которых расскажем о решениях отдельных подзадач распознавания документов (и не только) на мобильных устройствах.
Что же касается готового решения по распознаванию паспорта РФ на мобильном устройстве, мы с радостью хотим сообщить, скачать Demo-программу распознавания для Android можно уже сейчас (Smart PassportReader в Google play) и для iOS (Smart PassportReader в App Store). А если по роду деятельности вам интересно SDK нашего продукта, чтобы живьем «потрогать» и попробовать встроить в свои мобильные приложения – напишите нам на support@smartengines.biz и мы с удовольствием расскажем, как это сделать, а также ответим на другие интересующие Вас вопросы.
И в самом конце несколько скриншотов нашей программы для Apple iPhone

