Я уже рассказывал, как мы «ловим» проблемы PostgreSQL с помощью массового мониторинга логов на сотнях серверов одновременно. Но ведь кроме логов, эта СУБД предоставляет нам еще и множество инструментов для анализа ее состояния — грех ими не воспользоваться.
Правда, если просто смотреть на них с консоли, можно очень быстро окосеть без какой-либо пользы, потому что количество доступных нам данных превышает все разумные пределы.

Поэтому, чтобы ситуация все же оставалась контролируемой, мы разработали надстройку над Zabbix, которая поставляет метрики, формирует экраны и задает единые правила мониторинга для всех серверов и баз на них.
Сегодняшняя статья — о том, какие выводы можно сделать, наблюдая в динамике различные метрики баз PostgreSQL-сервера, и где может скрываться проблема.
Самое первое, с чего начинаются все разборки на тему «что у нас с базой сейчас/было плохо» — это наблюдение за сводным состоянием pg_stat_activity:
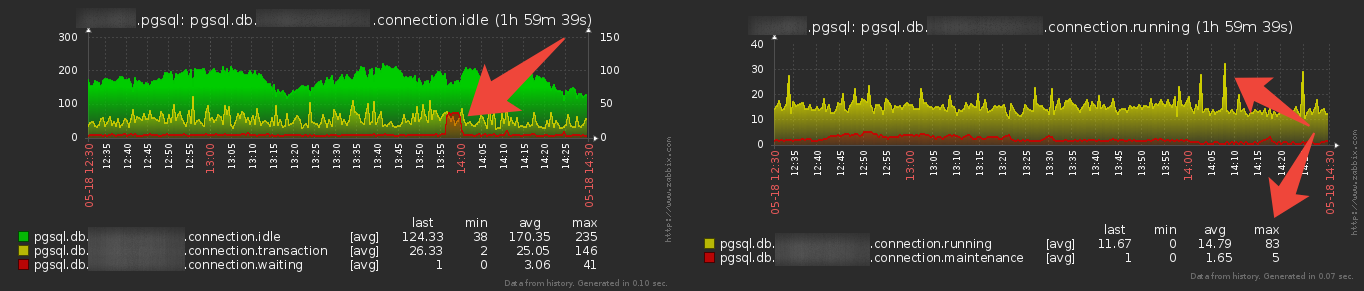
На левом графике мы видим все соединения, которые чего-то ждут, на правом — которые что-то делают. В зависимости от версии PG состояние соединения определяется по
На что обращать внимание:
Поскольку для нас важно снимать не только много метрик, но и делать это максимально эффективно, то некоторые из них мы стараемся снимать синхронно в рамках одного запроса:
Раз уж мы затронули в предыдущем пункте мониторинг блокировок, то стоит заметить, что PostgreSQL любит их накладывать направо и налево:

Нас из них больше всего интересуют два вида:
Но не забываем, что суммарное количество блокировок — не резиновое:
Для получения информации об изменениях в контексте текущей базы можно воспользоваться системным представлением pg_stat_database. Но если баз на сервере много, удобно делать это сразу для них всех, подключившись к
Отдельно хочу акцентировать внимание — не пренебрегайте выводом max-значений метрик!
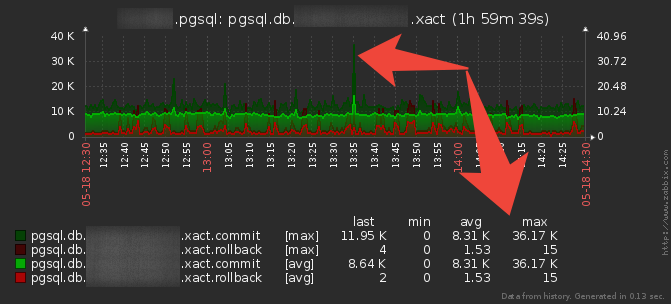
На этом графике мы как раз хорошо видим ситуацию внезапного пикового увеличения количества проведенных (
Ну а откат (
Сначала обратим внимание на записи, которые у нас вычитываются из индексов/таблиц:
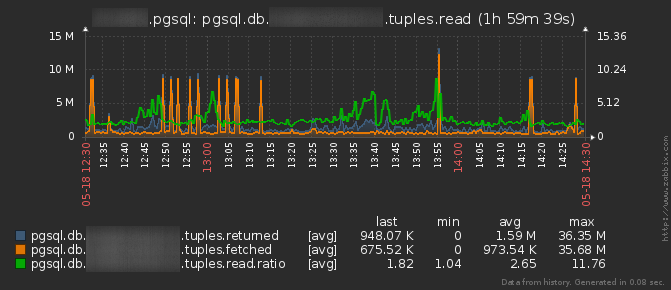
Если вы наблюдаете резкий пик
Впрочем, даже если
Раз уж мы начали проверять, «что» у нас там читается — давайте посмотрим и «как» это происходит. То есть какой объем записей у нас читается по индексам, а какой — в результате

Понятно, что тут любой внеплановый рост показателей должен вызвать подозрение. Например, если вы по каким-то нуждам каждую ночь вычитываете целиком табличку на 10M записей, то возникновение такого пика днем — повод к разборкам.
Равно как и любые массово-аномальные вставки/обновления/удаления:

Чтобы понять, насколько реально ухудшает жизнь сервера массовая вычитка записей, посмотрим на работу сервера со страницами данных и соотношение
В реальности все не совсем так, и является поводом к доскональному анализу запросов около времени пика:

Для MVCC долго активные запросы и транзакции в нагруженных системах — беда для производительности. Подробно и в картинках про это можно прочитать тут, а тут — как можно все-таки выжить в таких условиях.

Поймать таких злодеев нам помогают
Как показывает наш опыт, визуального представления этих метрик уже достаточно, чтобы примерно представлять, куда дальше «копать»:
Правда, если просто смотреть на них с консоли, можно очень быстро окосеть без какой-либо пользы, потому что количество доступных нам данных превышает все разумные пределы.
Поэтому, чтобы ситуация все же оставалась контролируемой, мы разработали надстройку над Zabbix, которая поставляет метрики, формирует экраны и задает единые правила мониторинга для всех серверов и баз на них.
Сегодняшняя статья — о том, какие выводы можно сделать, наблюдая в динамике различные метрики баз PostgreSQL-сервера, и где может скрываться проблема.
Состояние соединений
Самое первое, с чего начинаются все разборки на тему «что у нас с базой сейчас/было плохо» — это наблюдение за сводным состоянием pg_stat_activity:
На левом графике мы видим все соединения, которые чего-то ждут, на правом — которые что-то делают. В зависимости от версии PG состояние соединения определяется по
pg_stat_activity.state/wait_event и/или тексту самого запроса.На что обращать внимание:
- Слишком мало
idle— вашему приложению может в какой-то момент не хватить уже открытых к базе соединений, и при попытке открыть еще одно вы попадете на длительное ожидание инициализации процесса для обслуживания нового коннекта. - Слишком много
idleс динамикой роста может означать «утечку» соединений на стороне приложения, что рано или поздно приведет к достижению лимитаmax_connections. - Много
idle in transaction— скорее всего, у нас перегружена бизнес-логика или pgbouncer. То есть с точки зрения БД вы транзакцию открыли и ушли перекурить.
Если при этом есть еще и тенденция к росту, стоит поискать утечку открытых транзакций в приложении, а пока временно выставитьidle_in_transaction_session_timeout. - Растут
wait— приложение в кого-то «уперлось» на блокировках. Если это уже прошедшая разовая аномалия — повод разобраться в исходной причине.
Если же значение растет и растет, то стоит оперативно «прибить» виновника черезpg_terminate_backend(pid). - Пики
active(особенно max-значение) демонстрируют, насколько ваше приложение любит ходить в базу «синхронно». То есть вы кинули какой-то сигнал по всем пользователям (например, «опубликована новость») и несколько сотен клиентских приложений одновременно, без всяких задержек, рванули в базу читать…
Не надо так — сделайте минимальную рандомизированную задержку после приема сигнала, чтобы «размазать» нагрузку. maintenance— это все активные запросы, которые делают с базой что-то служебное:
query ~* E'^(\\s*(--[^\\n]*\\n|/\\*.*\\*/|\\n))*(autovacuum|VACUUM|ANALYZE|REINDEX|CLUSTER|CREATE|ALTER|TRUNCATE|DROP)'
В большинстве случаев там будет фигурировать количество одновременно работающих autovacuum/autoanalyze, вред которых заключается разве что в употреблении ресурсов сервера на «посторонние» дела. Если для вас это критично — покрутитеautovacuum_max_workersиautovacuum_naptime, но совсем отключать — не стоит.
Но если одновременно начинают растиwaitиmaintenance, то это повод посмотреть, не решил ли кто-то из DBA или разработчиков накатить индекс, например, заблокировав случайно половину функционала приложения.
Поскольку для нас важно снимать не только много метрик, но и делать это максимально эффективно, то некоторые из них мы стараемся снимать синхронно в рамках одного запроса:
Состояние соединений и блокировок
WITH event_types(wait_event_type) AS(
VALUES
('lwlock')
, ('lock')
, ('bufferpin')
, ('client')
, ('extension')
, ('ipc')
, ('timeout')
, ('io')
)
, events(wait_event) AS(
VALUES
('walwritelock')
, ('wal_insert')
, ('buffer_content')
, ('buffer_io')
, ('lock_manager')
, ('relation')
, ('extend')
, ('page')
, ('tuple')
, ('transactionid')
, ('virtualxid')
, ('speculative token')
, ('object')
, ('userlock')
, ('advisory')
, ('clientread')
, ('datafileextend')
, ('datafileread')
, ('datafilewrite')
, ('slruread')
, ('slruwrite')
)
, states(state) AS(
VALUES
('running')
, ('maintenance')
, ('waiting')
, ('transaction')
, ('idle')
)
, stats AS(
SELECT
pid
, datname
, state
, lower(wait_event_type) wait_event_type
, lower(wait_event) wait_event
, query
FROM
pg_stat_activity
WHERE
pid <> pg_backend_pid()
)
, dbs AS(
SELECT
datname
FROM
pg_database db
WHERE
NOT db.datistemplate
)
SELECT
date_part('epoch', now())::integer ts
, coalesce(s.qty, 0) val
, dbs.datname dbname
, states.state
, true total
FROM
dbs
CROSS JOIN
states
NATURAL LEFT JOIN
(
SELECT
datname
, CASE
WHEN query ~* E'^(\\s*(--[^\\n]*\\n|/\\*.*\\*/|\\n))*(autovacuum|VACUUM|ANALYZE|REINDEX|CLUSTER|CREATE|ALTER|TRUNCATE|DROP)' THEN
'maintenance'
WHEN wait_event IS NOT NULL AND
wait_event <> 'clientread' AND
state = 'active' THEN
'waiting'
WHEN state = 'active' THEN
'running'
WHEN state = 'idle' THEN
'idle'
WHEN state IN ('idle in transaction', 'idle in transaction (aborted)') THEN
'transaction'
WHEN state = 'fastpath function call' THEN
'fastpath'
ELSE
'disabled'
END state
, count(*) qty
FROM
stats
GROUP BY
1, 2
) s
UNION
SELECT
date_part('epoch', now())::integer ts
, coalesce(t.qty, 0) val
, dbs.datname dbname
, event_types.wait_event_type
, false total
FROM
dbs
CROSS JOIN
event_types
NATURAL LEFT JOIN
(
SELECT
datname
, wait_event_type
, count(*) qty
FROM
stats
WHERE
wait_event_type IS NOT NULL
GROUP BY
1, 2
) t
UNION
SELECT
date_part('epoch', now())::integer ts
, coalesce(e.qty, 0) val
, dbs.datname dbname
, events.wait_event
, false total
FROM
dbs
CROSS JOIN
events
NATURAL LEFT JOIN
(
SELECT
datname
, wait_event
, count(*) qty
FROM
stats
WHERE
wait_event IS NOT NULL
GROUP BY
1, 2
) e;
Блокировки
Раз уж мы затронули в предыдущем пункте мониторинг блокировок, то стоит заметить, что PostgreSQL любит их накладывать направо и налево:
Нас из них больше всего интересуют два вида:
Exclusive— типично возникают при блокировке на конкретной записи.AccessExclusive— при проведении maintenance-операции над таблицей.
Но не забываем, что суммарное количество блокировок — не резиновое:
И рекомендательные, и обычные блокировки сохраняются в области общей памяти, размер которой определяется параметрами конфигурацииОбычно такая ситуация возникает, если у вас в приложении «текут» и не освобождаются ресурсы: соединения с базой, контексты транзакций или advisory-блокировки. Поэтому обращайте внимание на общую динамику.max_locks_per_transactionиmax_connections. Важно, чтобы этой памяти было достаточно, так как в противном случае сервер не сможет выдать никакую блокировку. Таким образом, число рекомендуемых блокировок, которые может выдать сервер, ограничивается обычно десятками или сотнями тысяч в зависимости от конфигурации сервера.
Transactions per second (TPS)
Для получения информации об изменениях в контексте текущей базы можно воспользоваться системным представлением pg_stat_database. Но если баз на сервере много, удобно делать это сразу для них всех, подключившись к
postgres.
TPS & tuples
SELECT
extract(epoch from now())::integer ts
, datname dbname
, pg_stat_get_db_tuples_returned(oid) tup_returned
, pg_stat_get_db_tuples_fetched(oid) tup_fetched
, pg_stat_get_db_tuples_inserted(oid) tup_inserted
, pg_stat_get_db_tuples_updated(oid) tup_updated
, pg_stat_get_db_tuples_deleted(oid) tup_deleted
, pg_stat_get_db_xact_commit(oid) xact_commit
, pg_stat_get_db_xact_rollback(oid) xact_rollback
FROM
pg_database
WHERE
NOT datistemplate;
Отдельно хочу акцентировать внимание — не пренебрегайте выводом max-значений метрик!
На этом графике мы как раз хорошо видим ситуацию внезапного пикового увеличения количества проведенных (
commit) транзакций. Это не один-в-один соответствует нагрузке на сервер и транзакции могут быть разной сложности, но рост в 4 раза явно показывает, что серверу стоит иметь определенный резерв производительности, чтобы и такой пик переживать беспроблемно.Ну а откат (
rollback) транзакции — это повод проверить, осознанно ли ваше приложение выполняет ROLLBACK, или это автоматически делает сервер в результате возникшей ошибки.Количество операций над записями
Сначала обратим внимание на записи, которые у нас вычитываются из индексов/таблиц:
tuples.returned— это количество записей, которые были «прочитаны» со страниц данных.tuples.fetched— те из них, которые не были отфильтрованы «прямо тут» на этапеRows Removed by Filter, а ушли «выше» по плану выполнения.tuples.ratio— соответственно, отношение одного к другому, которое должно стремиться к 1, чем больше — тем хуже. Это базовый показатель, который демонстрирует, во сколько раз больше данных вы вычитываете, чем реально необходимо вашим запросам.
Если вы наблюдаете резкий пик
tuples.ratio — можете быть уверены, что рядом в логе вам попадется какой-то неэффективный запрос из разряда описанных в статье про рецепты их лечения.Впрочем, даже если
ratio идеально равно 1, но пик пришелся на returned/fetched — тоже хорошего не жди. Обычно это может означать наличие в плане какой-то неприятности вроде:Hash Join
- Hash
- Seq Scan on BIG_TABLE
- Index Scan ...Merge Join
- Index Scan on BIG_INDEX
- Index Scan ...Раз уж мы начали проверять, «что» у нас там читается — давайте посмотрим и «как» это происходит. То есть какой объем записей у нас читается по индексам, а какой — в результате
Seq Scan:Понятно, что тут любой внеплановый рост показателей должен вызвать подозрение. Например, если вы по каким-то нуждам каждую ночь вычитываете целиком табличку на 10M записей, то возникновение такого пика днем — повод к разборкам.
Равно как и любые массово-аномальные вставки/обновления/удаления:
Использование кэша данных
Чтобы понять, насколько реально ухудшает жизнь сервера массовая вычитка записей, посмотрим на работу сервера со страницами данных и соотношение
block.read/hit. В идеальном мире сервер не должен «читать» с диска (shared read на узле плана) ровно ничего, все уже должно быть в памяти (shared hit), поскольку обращение к диску — всегда медленно.В реальности все не совсем так, и является поводом к доскональному анализу запросов около времени пика:
Самый длительный запрос/транзакция
Для MVCC долго активные запросы и транзакции в нагруженных системах — беда для производительности. Подробно и в картинках про это можно прочитать тут, а тут — как можно все-таки выжить в таких условиях.
Поймать таких злодеев нам помогают
pg_stat_activity.query_start/xact_start.Как показывает наш опыт, визуального представления этих метрик уже достаточно, чтобы примерно представлять, куда дальше «копать»:
- искать утечки ресурсов в приложении
- оптимизировать неудачные запросы
- ставить более производительное «железо»
- … или следить, чтобы нагрузка была правильно разнесена во времени
