Это перевод и форма повествования от первого лица сохранена. Автор — Бен Бойтер, бакалавр информационных технологий в Университете Чарльза Стерта (CSU).

Большинство людей не в курсе, но моей диссертацией была программа для чтения текста с изображения. Я думал, что, если смогу получить высокий уровень распознавания, то это можно будет использовать для улучшения результатов поиска. Мой отличный советник
доктор Гао Джунбин предложил мне написать диссертацию на эту тему. Наконец-то я нашел время написать эту статью и здесь я постараюсь рассказать о всем том, что узнал. Если бы только было что-то подобное, когда я только начинал…
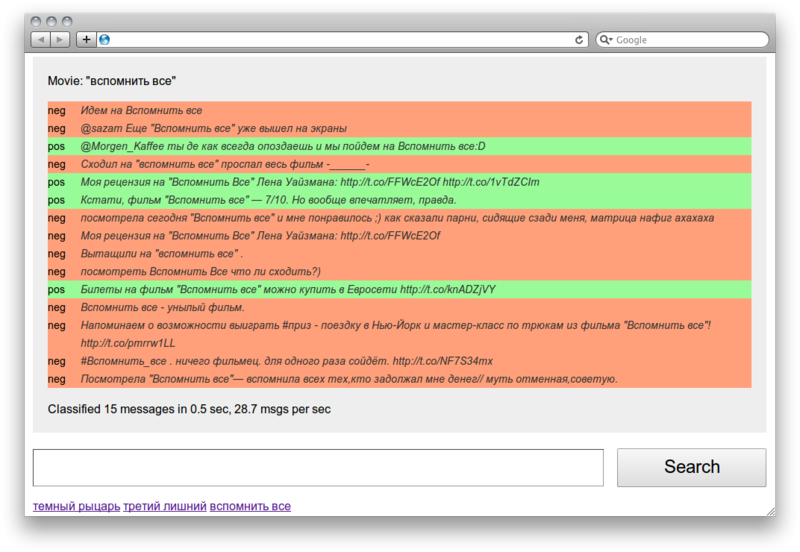
Как я уже говорил, я пытался взять обычные изображения из интернета и извлекать из них текст для улучшения результатов поиска. Большинство моих идей было основано на методах взлома капчи. Как всем известно, капча — это те самые всех раздражающее штуки, вроде «Введите буквы, которые вы видите на изображении» на страницах регистрации или обратной связи.
Капча устроена так, что человек может прочитать текст без труда, в то время, как машина — нет (привет, reCaptcha!). На практике это никогда не работало, т. к. почти каждую капчу, которую размещали на сайте взламывали в течение нескольких месяцев.
У меня неплохо получалось — более 60% изображений было успешно разгадано из моей небольшой коллекции. Довольно неплохо, учитывая количество разнообразных изображений в интернете.

 Эта статья не для матёрых укротителей Python’а, для которых распутать этот клубок змей — детская забава, а скорее поверхностный обзор многопоточных возможностей для недавно подсевших на питон.
Эта статья не для матёрых укротителей Python’а, для которых распутать этот клубок змей — детская забава, а скорее поверхностный обзор многопоточных возможностей для недавно подсевших на питон. 


 Недавно мне потребовалось получать данные с вебкамеры для автоматической их обработки. Перебрав несколько программок, обнаружил, что ни одна из них не позволяет рулить камерой программно — только формы да кнопки, в лучшем случае есть планировщик записи, но для этого приходится постоянно держать программу запущенной. Плюс не кросплатформенно, привязка к конкретному ПО в проекте. Решение — задействовать любимый язык программирования.
Недавно мне потребовалось получать данные с вебкамеры для автоматической их обработки. Перебрав несколько программок, обнаружил, что ни одна из них не позволяет рулить камерой программно — только формы да кнопки, в лучшем случае есть планировщик записи, но для этого приходится постоянно держать программу запущенной. Плюс не кросплатформенно, привязка к конкретному ПО в проекте. Решение — задействовать любимый язык программирования.