Квантизация — уменьшение цветов изображения (
wiki). Конечно, сейчас мало кому это необходимо, но задача сама по себе интересная.
Квантизированная Лена привлекает внимание
Например, старый добрый формат GIF использует палитру, максимум на 256 цветов. Если вы захотите сохранить серию своих селфи как gif-анимацию (кому бы это надо было), то первое, что вам, а точнее программе, которую вы будете для этого использовать, надо будет сделать – создать палитру. Можно использовать статическую палитру, например
web-safe colors, алгоритм квантизации получиться очень простым и быстрым, но результат будет «не очень». Можно создать оптимальную палитру на основе цветов изображения, что даст результат наиболее визуально похожий на оригинал.
Алгоритмов создания оптимальной палитры несколько, каждый имеет свои плюсы и минусы. Я не стану утруждать читателя нудной теорией и формулами, во первых мне лень, во вторых большинству это не интересно – статью просто пролистают, рассматривая картинки.
Далее вас ждёт
скучное и непонятное повествование о методе медианного сечения, алгоритму рассеивания ошибок (шума квантизации) по Флойду-Стейнбергу (и не только), особенностях цветового восприятия человеческого глаза, а так же немного
говнокода.


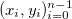 и соответствующий им набор положительных весов
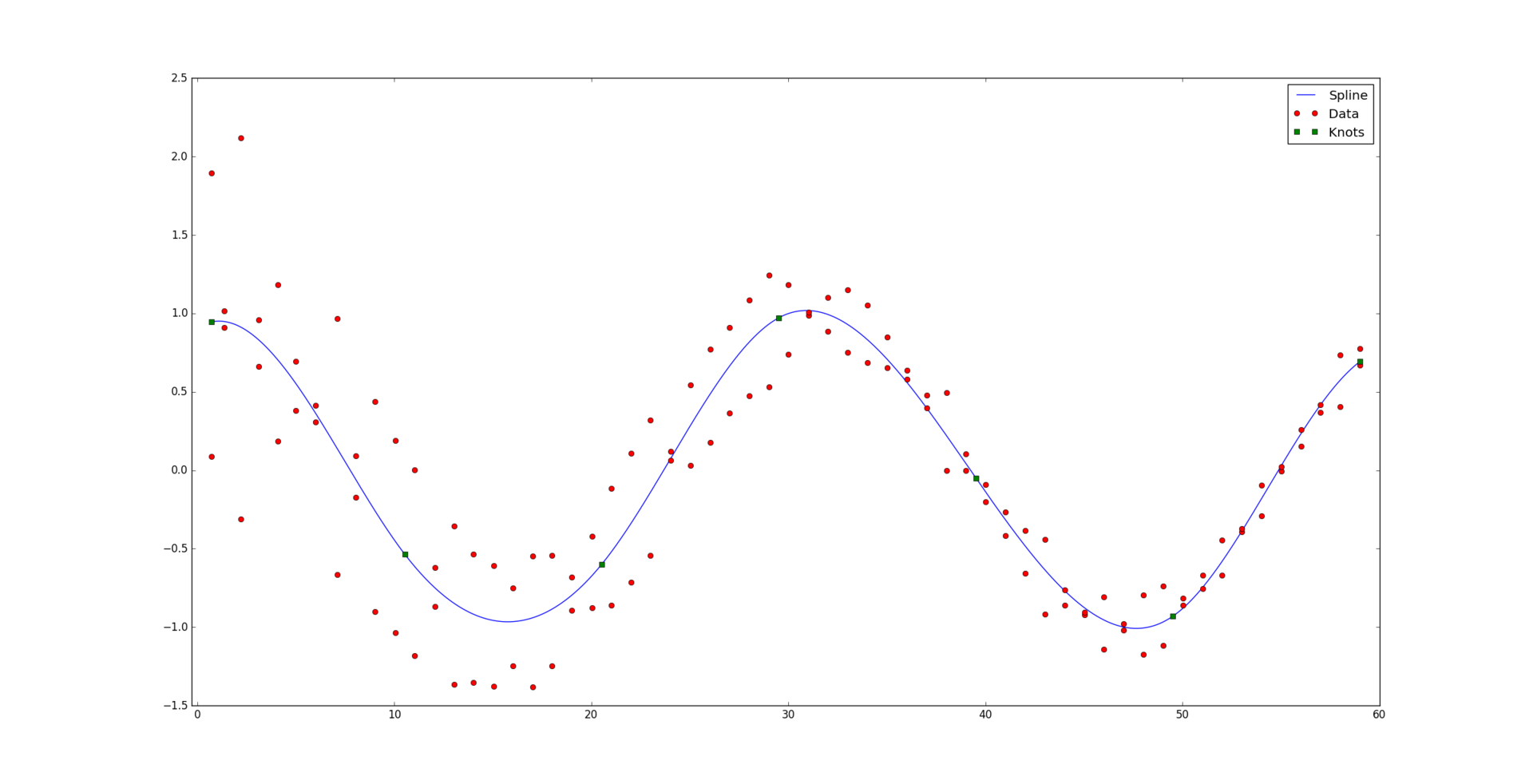
и соответствующий им набор положительных весов 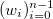 . Мы считаем, что некоторые точки могут быть важнее других (если нет, то все веса одинаковые). Неформально говоря, мы хотим, чтобы на соответствующем интервале была проведена красивая кривая таким образом, чтобы она «лучше всего» проходила через эти данные.
. Мы считаем, что некоторые точки могут быть важнее других (если нет, то все веса одинаковые). Неформально говоря, мы хотим, чтобы на соответствующем интервале была проведена красивая кривая таким образом, чтобы она «лучше всего» проходила через эти данные. 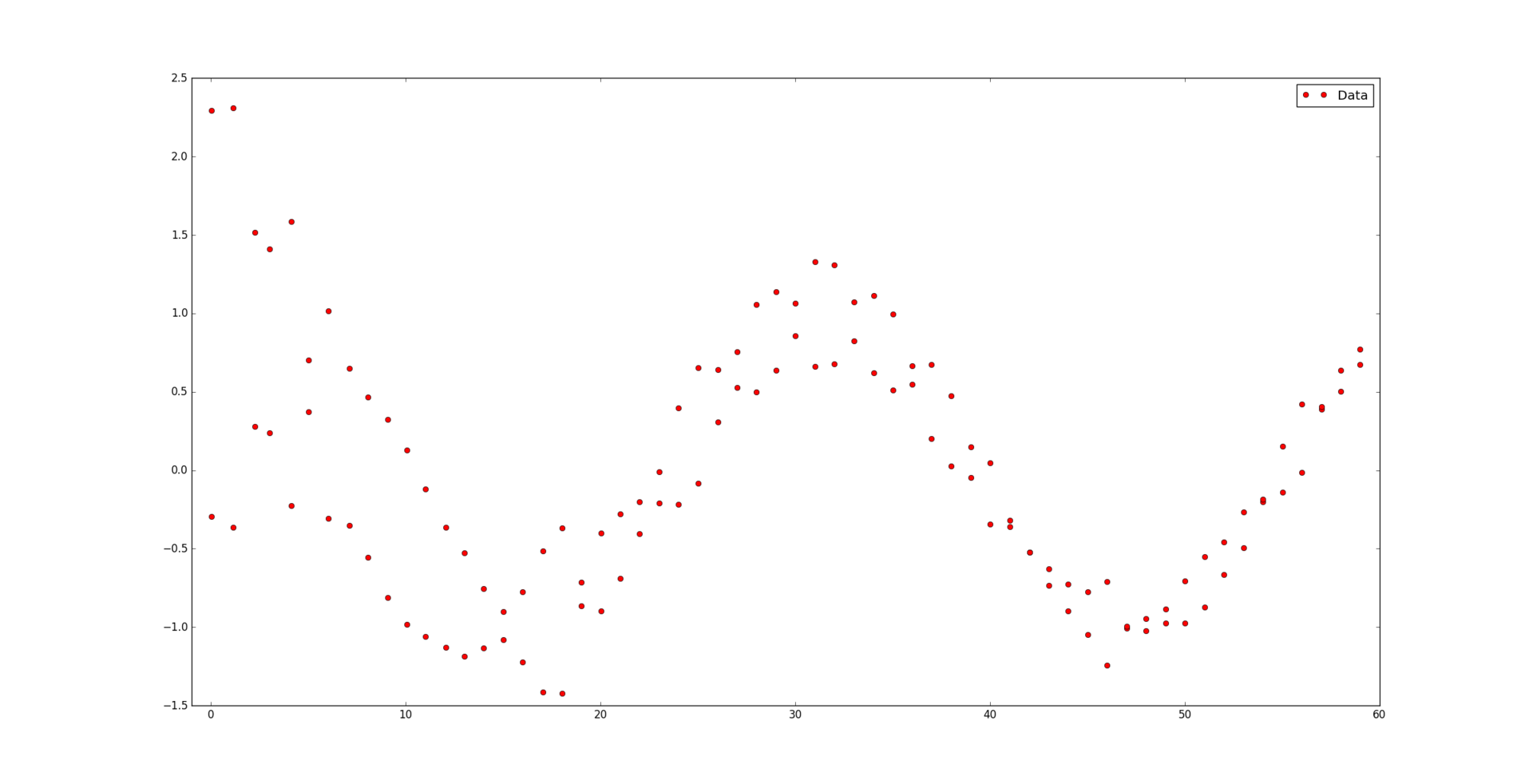


 В начале ноября в американском городе Иссакуа завершилась встреча международной рабочей группы
В начале ноября в американском городе Иссакуа завершилась встреча международной рабочей группы 




 Глава из книги "Современное программирование на C++" называется "В сто первый раз об интеллектуальных указателях". Все бы ничего, но книга была издана в 2001 году, так стоит ли в очередной раз возвращаться к этой теме? Мне кажется что как раз сейчас и стоит. За эти пятнадцать лет поменялась сама точка зрения, тот угол под которым мы смотрим на проблему. В те далекие времена только-только вышла первая де-факто стандартная реализация — boost::shared_ptr<>, до этого каждый писал себе реализацию по потребности и как минимум представлял себе детали, сильные и слабые стороны своего кода. Все книги по C++ в то время обязательно описывали одну из вариаций умных указателей в мельчайших деталях.
Глава из книги "Современное программирование на C++" называется "В сто первый раз об интеллектуальных указателях". Все бы ничего, но книга была издана в 2001 году, так стоит ли в очередной раз возвращаться к этой теме? Мне кажется что как раз сейчас и стоит. За эти пятнадцать лет поменялась сама точка зрения, тот угол под которым мы смотрим на проблему. В те далекие времена только-только вышла первая де-факто стандартная реализация — boost::shared_ptr<>, до этого каждый писал себе реализацию по потребности и как минимум представлял себе детали, сильные и слабые стороны своего кода. Все книги по C++ в то время обязательно описывали одну из вариаций умных указателей в мельчайших деталях.
