Ранее мы говорили о том, что любая информация имеет как внешнюю форму, так и внутренний смысл. Внешняя форма — это то, что именно мы, например, увидели или услышали. Смысл — это то, какую интерпретацию этому мы дали. И внешняя форма, и смысл могут быть описаниями, составленными из определенных понятий.
Было показано, что если описания удовлетворяют ряду условий, то давать им интерпретацию можно, просто заменяя понятия исходного описания на другие понятия, применяя определенные правила.
Правила трактовки зависят от тех сопутствующих обстоятельств, в которых мы пытаемся дать интерпретацию информации. Эти обстоятельства принято называть контекстом, в котором трактуется информация.
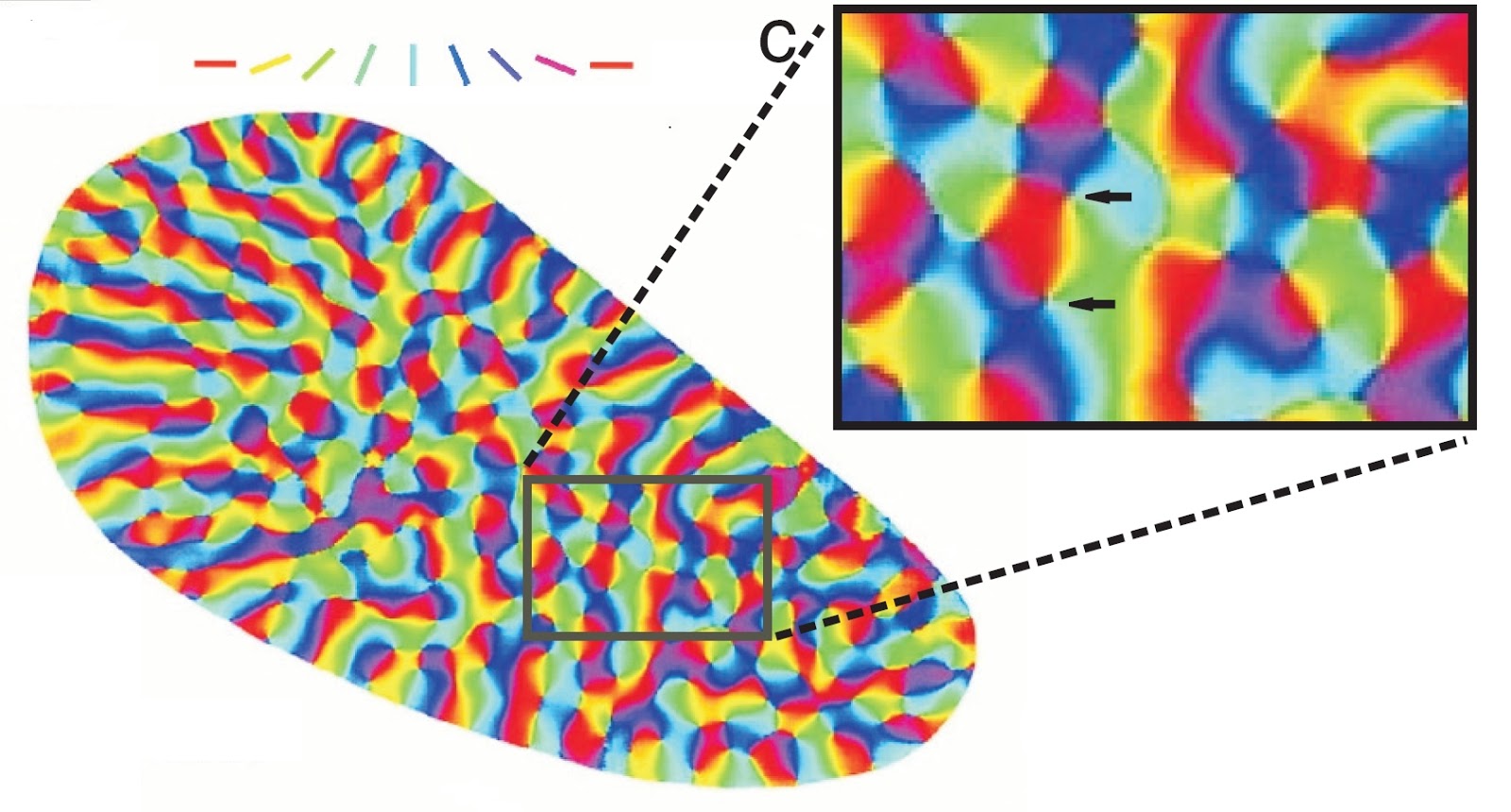
Кора мозга состоит из нейронных миниколонок. Мы предположили, что каждая миниколонка коры — это вычислительный модуль, который работает со своим информационным контекстом. То есть каждая зона коры содержит миллионы независимых вычислителей смысла, в которых одна и та же информация получает свою собственную трактовку.
Был показан механизм кодирования и хранения информации, который позволяет каждой миниколонке коры иметь свою полную копию памяти о всех предыдущих событиях. Наличие собственной полной памяти позволяет каждой миниколонке проверить, насколько ее интерпретация текущей информации согласуется со всем предыдущим опытом. Те контексты в которых трактовка оказывается «похожа» на что-то ранее знакомое составляют набор смыслов, содержащихся в информации.



 Статистика приходит к нам на помощь при решении многих задач, например: когда нет возможности построить детерминированную модель, когда слишком много факторов или когда нам необходимо оценить правдоподобие построенной модели с учётом имеющихся данных. Отношение к статистике неоднозначное. Есть мнение, что существует три вида лжи: ложь, наглая ложь и статистика. С другой стороны, многие «пользователи» статистики слишком ей верят, не понимая до конца, как она работает: применяя, например, тест
Статистика приходит к нам на помощь при решении многих задач, например: когда нет возможности построить детерминированную модель, когда слишком много факторов или когда нам необходимо оценить правдоподобие построенной модели с учётом имеющихся данных. Отношение к статистике неоднозначное. Есть мнение, что существует три вида лжи: ложь, наглая ложь и статистика. С другой стороны, многие «пользователи» статистики слишком ей верят, не понимая до конца, как она работает: применяя, например, тест 






 Что такое информация, как найти скрытый в ней смысл, что вообще есть смысл? В большинстве толкований
Что такое информация, как найти скрытый в ней смысл, что вообще есть смысл? В большинстве толкований 