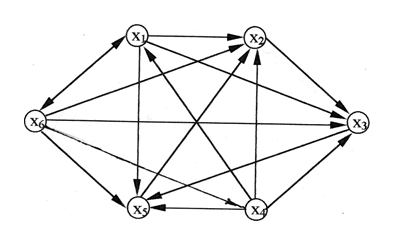
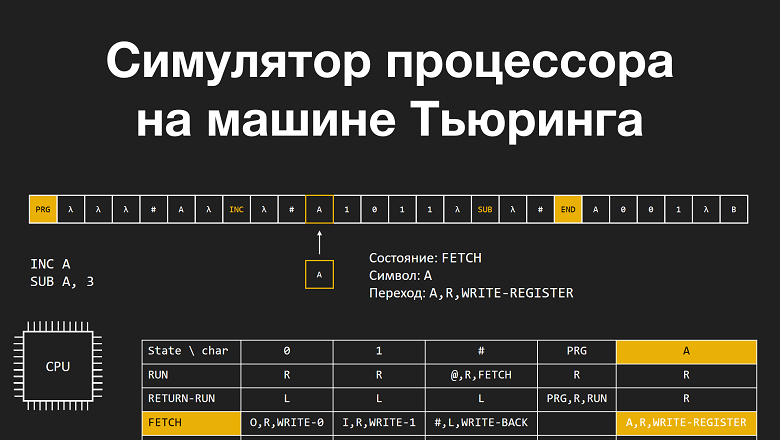
Под социальной сетью понимается социальная структура, состоящая из множества агентов (субъектов - индивидуальных или коллективных, например, индивидов, семей, групп, организаций) и определенного на нем множества отношений (совокупностей связей между агентами, например, знакомства, дружбы, сотрудничества, коммуникации). Сегодня - это уже знакомый большинству населения объект, особенно тем, кто не выпускает смартфон из рук. Представление о сетях у людей, тем не менее, очень различаются. Мало кто пытается для себя как-то формализовать, определить да большой нужды в этом не испытывает, хотя уже давно является элементом такой сети и возможно даже не одной.
Простой образ любой сети - узлы и соединяющие эти узлы связи. Роль узлов в социальных сетях выполняют люди, мы с вами, а роль связей социальные коммуникации, социальные потребности, отношения. Этот образ изображается (представляется) орграфом (мультиграфом) с множеством вершин и дуг. Если граф не пуст или не полный, то его структура может описываться множеством вариантов, которое распадается на подмножества изоморфных графов. Таким графам соответствует и другое матричное описание. С позиции структуры социальных сетей их строгая классификация возможна математическими (алгебраическими) методами.