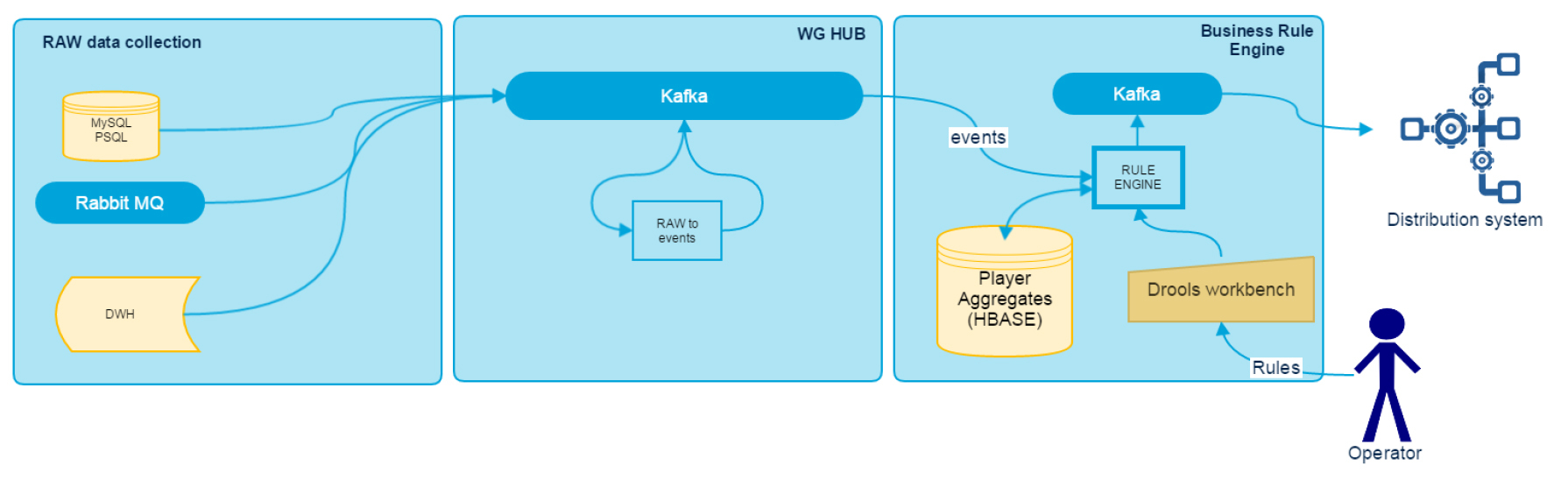
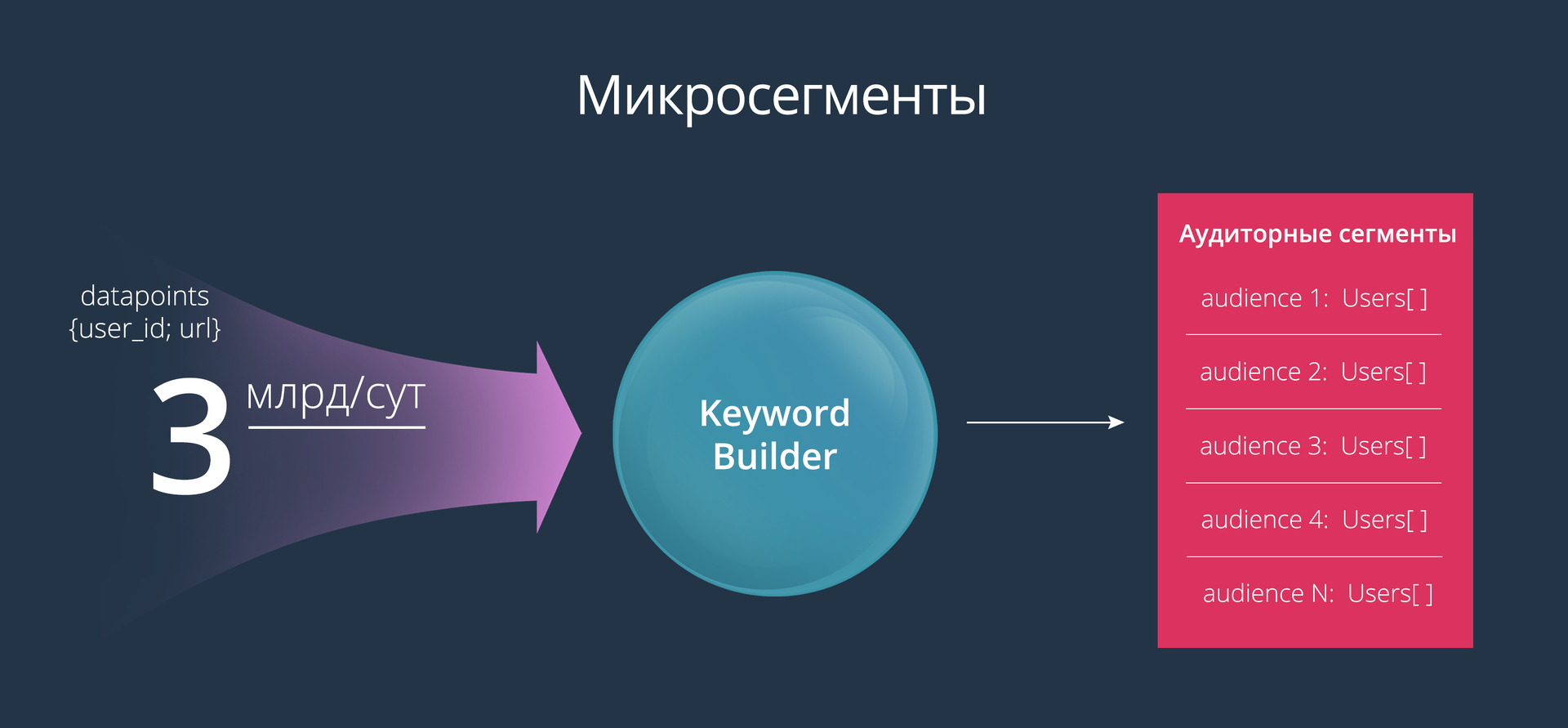
В статье "
Применение Теории вероятностей в IT" автор (преподаватель теории вероятностей в ВУЗе) пишет:
из года в год я сталкиваюсь с таким явлением, что студенты не понимают, зачем и почему им учить эту дисциплину.
Это действительно важная проблема. Владелец компании минималистичных видео-уроков Common Craft и заодно автор книги "
Искусство объяснять" пишет, что человеку очень важно сначала ответить себе на вопрос «зачем?», и только тогда он заинтересуется ответом на вопрос «как?» (наверное, поэтому ему заказывали создание роликов в стиле Common Craft и Google, и Dropbox, и Twitter).
Поэтому я решил разобраться в теории вероятностей: накупил разных книжек типа "
Удовольствие от икс", да потом ещё нанял двух репетиторов по Skype.
В итоге всё стало проясняться, и было решено поделиться своими инсайдами с широкой аудиторией.
Самый красивый пример, из тех, что я нашёл — это болты в чае. В советские времена был
ГОСТ на максимальное содержание болтов\гаек в чае, которые попадали туда при уборке урожая: «массовая доля металломагнитной примеси» не должна была превышать 5-7 грамм на тонну. Для этого проверяли выборку и по ней делали заключение по всей партии чая.
И от этого примера можно переходить к более глобальному примеру применения статистического анализа — к японскому экономическому чуду.
В общем, всё это упоминается в тизере
вебинара: