
С рождением PHP 7 не прекращаются споры об абстрактных синтаксических деревьях, just-in-time компиляторах, статическом анализе и т. д. Но что означают все эти термины? Это какие-то волшебные свойства, делающие PHP гораздо производительнее? И если да, то как это всё работает? В этой статье мы рассмотрим основы работы языков программирования и разъясним для себя процесс, который должен выполняться до того, как компьютер запустит, например, ваш PHP-скрипт.
Генератор музыки на базе кодогенератора
4 мин
Привет, хабраюзер! В этом топике я расскажу о своей идее генерации музыкальных композиций. Создадим язык описания ритма музыки на базе python, напишем компилятор этого языка в wave файлы и получим довольно нехилую электронную композицию.
Добро пожаловать под кат.
Добро пожаловать под кат.
История языков программирования: 100% «чистый» Си, без единого «плюса»
13 мин

Популярность языка программирования Си трудно переоценить, особенно вспоминая его былые заслуги. Наверное, каждый разработчик, как минимум, знает о его существовании, и, как максимум, пробовал на нем программировать. Си является предшественником таких языков, как C++, Objective-C, C#, Java.
Компания Microsoft для разработки родного языка к своей платформе .Net выбрала именно Си-подобный синтаксис. Более того, на Си написано множество операционных систем.
Конечно, Си не идеален: создатели языка – Кен Томпсон и Деннис Ритчи – долгое время дорабатывали его. Стандартизация Си продолжается до сих пор. Он существует более 45 лет и активно используется.
С ним часто ассоциируют не один, а два языка программирования — C/C++. Однако ниже речь пойдет именно о «чистом» Си.
Чем полезен мономорфизм?
14 мин
Перевод

Выступления и посты в блогах о производительности JavaScript часто обращают внимание на важность мономорфного кода, однако обычно не дается внятного никакого объяснения, что такое мономорфизм/полиморфизм и почему это имеет значение. Даже мои собственные выступления зачастую сводятся к дихотомии в стиле Невероятного Халка: «ОДИН ТИП ХОРОШО! ДВА ТИП ПЛОХО!». Неудивительно, что когда люди обращаются ко мне за советом по производительности, чаще всего они просят объяснить, что на самом деле такое мономорфизм, откуда берется полиморфизм и что в нем плохого.
Ситуацию осложняет еще и то, что само слово «полиморфизм» имеет множество значений. В классическом объектно-ориентированном программировании полиморфизм связан с созданием дочерних классов, в которых можно переопределить поведение базового класса. Программисты, работающие с Haskell, вместо этого подумают о параметрическом полиморфизме. Однако полиморфизм, о котором предупреждают в докладах о производительности JavaScript – это полиморфизм вызовов функции.
Я объяснял этот механизм столькими различными путями, что наконец-то собрался и написал данную статью: теперь можно будет не импровизировать, а просто дать на нее ссылку.
Я также попробовал новый способ объяснять вещи – изображая взаимодействие составных частей виртуальной машины в виде коротких комиксов. Кроме того, данная статья не покрывает некоторые детали, которые я посчитал незначительными, излишними или не связанными напрямую.
Не Паскалем единым: что сделал для современного мира лауреат компьютерной «нобелевки» Никлаус Вирт
11 мин

Некоторые считают, что современный мир почти не знает Никлауса Вирта и даже не догадывается о его огромном вкладе в мировую компьютерную науку. Кто-то полагает его «отцом Паскаля». Вирта вспоминают не только педагоги в ВУЗах, когда преподают студентам Turbo Pascal, но и коммерческие разработчики, пишущие на Delphi.
На самом деле, Никлаус Вирт является инженером с большой буквы, его вклад в развитие языков программирования не ограничивается Паскалем, а только начинается с него. Кроме того, Вирт — педагог, общественный деятель и, можно сказать, философ. Попробуем оценить реальный масштаб его личности и вклад в ИТ-индустрию.
Занимательный C#
8 мин
Занимательный C#
Для оценки качества диагностик анализатора C# кода PVS-Studio мы проверяем большое количество различных проектов. Т.к. проекты пишутся разными людьми в различных командах в разных компаниях, нам приходится сталкиваться с различными стилями, сокращениями, да и просто возможностями, которые предлагает язык C# программистам. В этой статье я хочу обзорно пройтись по некоторым моментам, которые предлагает нам замечательный язык C#, и по тем проблемам, на которые можно наткнуться при его использовании.
Для оценки качества диагностик анализатора C# кода PVS-Studio мы проверяем большое количество различных проектов. Т.к. проекты пишутся разными людьми в различных командах в разных компаниях, нам приходится сталкиваться с различными стилями, сокращениями, да и просто возможностями, которые предлагает язык C# программистам. В этой статье я хочу обзорно пройтись по некоторым моментам, которые предлагает нам замечательный язык C#, и по тем проблемам, на которые можно наткнуться при его использовании.
Компилятор С/С++ на базе LLVM для мультиклеточных процессоров: быть или не быть?
24 мин

Пытливый читатель наверняка уже знаком с принципиально новой архитектурой процессоров — мультиклеточной; а если не знает, сможет бегло ознакомиться в нашей статье. Архитектура настолько непохожа на традиционные, что создание компилятора привычных языков программирования становится проблемой, с которой разработчики безуспешно борются многие годы.
Немного истории
С начала основания компании "Мультиклет" в 2010 велась разработка нескольких типов компиляторов для мультиклеточной архитектуры:
- С первым процессором Multiclet P1 в 2012 году был разработан в составе программного обеспечения компилятор С89 на базе LCC. Одновременно велась разработка первого варианта собственного компилятора, приостановленная ввиду изначально сложного нереализуемого замысла.
Как уже неоднократно указывалось во многих статьях на данную тему, а также признавалось самими разработчиками компании, компилятор на базе LCC имеет ряд существенных недостатков: поддержка лишь языка С89, отсутствие каких-либо оптимизаций.
Впоследствии данный компилятор был адаптирован для поддержки нового процессора Multiclet R1 (2015 г.), система команд которого была значительно расширена, но компилятор этого не учитывал.
Принимая во внимание эти недостатки, руководство компании в 2012 году собрало группу программистов, которым была поставлена задача разработать новый компилятор С99, лишённый указанных недостатков.
Почему мы пишем и храним код в текстовых файлах?
8 мин

Простые текстовые форматы данных — прекрасная штука. Нет, без шуток. Возьмём, например, банальные txt-файлы. Ну красота же! В любом утюге есть текстовый редактор, можно открыть файл, почитать, записать. Любой уважающий себя язык программирования из коробки даст вам средства работы с текстовыми файлами. Или вот ранние сетевые протоколы — SMTP, POP3, HTTP 1.0. Это вообще такое блаженство, что слёзы на глаза наворачиваются. Можно взять telnet, приконнектиться к серверу, отдавать команды и читать ответы! Писать клиенты, серверы, снифферы, прокси — одно удовольствие.
Но время не стоит на месте и удобство работы программиста, к сожалению (или к счастью!), давно перестало быть главным критерием выбора технологий. В прекрасные текстовые файлы понадобилось вдруг добавлять графики, картинки и ссылки — и вот у нас есть форматы pdf и doc. С сетевыми протоколами вообще беда — людям зачем-то понадобились сжатие трафика, шифрование, мультиплексирование и другие страшные вещи. И вот уже у нас есть HTTP/2, с которым телнетом не очень-то поработаешь. Даже всем красивый REST разные негодяи типа Google нет-нет, да и пытаются заменить на какой-нибудь gRPC. И это я ещё не начал рассуждать о том, что мало что нынче сохраняется текстовые файлы — все почему-то используют какие-то базы данных, совершенно нечитабельные при открытии их текстовым редактором, но
И вот здесь мы подходим к теме того, что я хотел бы обсудить. Как видите, все форматы хранения данных, протоколы и прочие штуки прошли длинный путь в поисках своего оптимального вида. Однако мы, программисты, продолжаем писать код наших программ в текстовых файлах, как делали это наши дедушки лет 50 назад (или уже больше?). Какую бы ОС мы ни использовали, какой бы модный язык ни выбрали, как бы ни была крутой наша IDE — результатом написания кода будут буквы в текстовом файле. Что, согласитесь, в теории совершенно не обязательно, ибо наши буквы компьютеру нужны как зайцу стоп-сигнал. Ему нужны машинные команды для выполнения, это просто нам удобнее описывать их какими-то там буквами. А на самом деле ведь «цикл» или «функция» будут тем, чем они являются, как ты их не назови и где ты их не храни. «Роза пахнет розой, хоть розой назови её, хоть нет».
Да, мы привыкли писать код в текстовые файлы. Вы открываете файл — ну и вроде бы видите код своей программы. Какую-то его часть, вернее. Как-то видите. Понимаете. Ну или думаете, что понимаете. Но вот пост на Facebook вы тоже открываете, видите и понимаете — а ведь Facebook точно этот пост не в текстовом файле хранил.
Давайте же посмотрим, какие проблемы нам создаёт хранение кода в виде набора текстовых строк.
Язык шаблонов для универсального сигнатурного анализатора кода
5 мин
Процесс сигнатурного анализа кода в нашем проекте PT Application Inspector разбит на следующие этапы:
- парсинг в зависимое от языка представление (abstract syntax tree, AST);
- преобразование AST в независимый от языка унифицированный формат;
- непосредственное сопоставление с шаблонами, описанными на DSL.
О первых двух этапах было рассказано в предыдущих статьях «Теория и практика парсинга исходников с помощью ANTLR и Roslyn» и «Обработка древовидных структур и унифицированное AST». Данная статья посвящена третьему этапу, а именно: различным способам описания шаблонов, разработке специализированного языка (DSL) для их описания, а также примерам шаблонов на этом языке.

Обработка древовидных структур и унифицированное AST
11 мин
Предыдущая статья серии была посвящена теории парсинга исходников с использованием ANTLR и Roslyn. В ней было отмечено, что процесс сигнатурного анализа кода в нашем проекте PT Application Inspector разбит на следующие этапы:
- парсинг в зависимое от языка представление (abstract syntax tree, AST);
- преобразование AST в независимый от языка унифицированный формат (Unified AST, UAST);
- непосредственное сопоставление с шаблонами, описанными на DSL.
Данная статья посвящена второму этапу, а именно: обработке AST с помощью стратегий Visitor и Listener, преобразованию AST в унифицированный формат, упрощению AST, а также алгоритму сопоставления древовидных структур.
Содержание
Персистентная ОС: ничто не блокируется
6 мин
Это — статья-вопрос. У меня нет идеального ответа на то, что здесь будет описано. Какой-то есть, но насколько он удачен — неочевидно.
Статья касается одной из концептуальных проблем ОС Фантом, ну или любой другой системы, в которой есть персистентная и «волатильная» составляющие.
Для понимания сути проблемы стоит прочесть одну из предыдущих статей — про персистентную оперативную память.
Краткая постановка проблемы: В силу того, что прикладная программа в ОС Фантом персистентна (не перезапускается при перезагрузке), а ядро — нет (перезапускается при перезагрузке и может быть изменено между запусками), в такой системе нельзя делать блокирующие системные вызовы. Обычным способом.
Статья касается одной из концептуальных проблем ОС Фантом, ну или любой другой системы, в которой есть персистентная и «волатильная» составляющие.
Для понимания сути проблемы стоит прочесть одну из предыдущих статей — про персистентную оперативную память.
Краткая постановка проблемы: В силу того, что прикладная программа в ОС Фантом персистентна (не перезапускается при перезагрузке), а ядро — нет (перезапускается при перезагрузке и может быть изменено между запусками), в такой системе нельзя делать блокирующие системные вызовы. Обычным способом.
Сборка мусора в персистентной модели: от терабайта и дальше
5 мин
Привет всем. Продолжу о Фантоме. Для понимания полезно прочесть статью про персистентную оперативку, а так же общую статью про Фантом на Открытых Системах. Но можно и так.
Итак, мы имеем ОС (или просто среду, не важно), которая обеспечивает прикладным программам персистентную оперативную память, и вообще персистентную «жизнь». Программы живут в общем адресном пространстве с управляемыми (managed) пойнтерами, объектной байткод-машиной, не замечают рестарта ОС и, в целом, счастливы.
Очевидно, что такой среде нужна сборка мусора. Но — какая?
Есть несколько проблем, навязанных спецификой.
Во-первых, теоретически, объём виртуальной памяти в такой среде огромен — терабайты, всё содержимое диска. Ведь мы отображаем в память всё и всегда.
Во-вторых, нас категорически не устраивают stop the world алгоритмы. Если для обычного процесса остановка в полсекундны может быть приемлема, то для виртуальной памяти, которая, большей частью, на диске, это будут уже полчаса, а то как бы не полсуток!
Наконец, если считать, что полная сборка мусора составляет полсуток, нас, наверное, это не устроит — было бы здорово иметь какой-то быстрый процесс сбора мусора, хотя бы и не полностью честный, пусть он часть мусора теряет, но если удаётся быстро вернуть 90% — уже хорошо.
Тут нужна оговорка. Вообще говоря, в системе, которая располагает парой терабайт виртуальной памяти, это не так уж критично — даже если не делать освобождение памяти полсуток, возможно, не так много и набежит — ну, например, истратится 2-3, ну 5 гигабайт, ну даже и 50 гигабайт — не жалко, диск большой.
Но, скорее всего, это приведёт к большой фрагментации памяти — множество локальных переменных окажутся раскиданы по многим далеко расположенным страницам, при этом высока вероятность того, что небольшие вкрапления актуальной информации будут перемежены с тоннами неактуального мусора, что сильно повысит нагрузку на оперативную память.
Ок, итого у нас две задачи.
Итак, мы имеем ОС (или просто среду, не важно), которая обеспечивает прикладным программам персистентную оперативную память, и вообще персистентную «жизнь». Программы живут в общем адресном пространстве с управляемыми (managed) пойнтерами, объектной байткод-машиной, не замечают рестарта ОС и, в целом, счастливы.
Очевидно, что такой среде нужна сборка мусора. Но — какая?
Есть несколько проблем, навязанных спецификой.
Во-первых, теоретически, объём виртуальной памяти в такой среде огромен — терабайты, всё содержимое диска. Ведь мы отображаем в память всё и всегда.
Во-вторых, нас категорически не устраивают stop the world алгоритмы. Если для обычного процесса остановка в полсекундны может быть приемлема, то для виртуальной памяти, которая, большей частью, на диске, это будут уже полчаса, а то как бы не полсуток!
Наконец, если считать, что полная сборка мусора составляет полсуток, нас, наверное, это не устроит — было бы здорово иметь какой-то быстрый процесс сбора мусора, хотя бы и не полностью честный, пусть он часть мусора теряет, но если удаётся быстро вернуть 90% — уже хорошо.
Тут нужна оговорка. Вообще говоря, в системе, которая располагает парой терабайт виртуальной памяти, это не так уж критично — даже если не делать освобождение памяти полсуток, возможно, не так много и набежит — ну, например, истратится 2-3, ну 5 гигабайт, ну даже и 50 гигабайт — не жалко, диск большой.
Но, скорее всего, это приведёт к большой фрагментации памяти — множество локальных переменных окажутся раскиданы по многим далеко расположенным страницам, при этом высока вероятность того, что небольшие вкрапления актуальной информации будут перемежены с тоннами неактуального мусора, что сильно повысит нагрузку на оперативную память.
Ок, итого у нас две задачи.
Суперскалярный стековый процессор: подробности
7 мин

Продолжение серии статей, разбирающих идею суперскалярного процессора с OoO и фронтендом стековой машины.
Тема данной статьи — вызов функций, вид изнутри.
Ближайшие события
Правила работы с Tasks API. Часть 1
3 мин
С момента появления тасков в .NET прошло почти 6 лет. Однако я до сих пор вижу некоторую путаницу при использовании Task.Run() и Task.Factory.StartNew() в коде проектов. Если это можно списать на их схожесть, то некоторые проблемы могут возникнуть из-за dynamic в C#.
В этом посте я попытаюсь показать проблему, решение и истоки.
Пусть у нас есть код, который выглядит так:
Вопросзнатокам: есть ли в данном примере проблема? Если да, то какая? Код компилируется, возвращаемый тип Task на месте, модификатор async при использовании await — тоже.
Думаете, речь идет о пропущенном ConfigureAwait? Хаха!
В этом посте я попытаюсь показать проблему, решение и истоки.
Проблема
Пусть у нас есть код, который выглядит так:
static async Task<dynamic> Compute(Task<dynamic> inner)
{
return await Task.Factory.StartNew(async () => await inner);
}
Вопрос
Думаете, речь идет о пропущенном ConfigureAwait? Хаха!
Суперскалярный стековый процессор: продолжаем скрещивать ужа и ежа
6 мин

Продолжение статьи, где удалось продемонстрировать, что фронтенд стековой машины вполне позволяет спрятать за ним суперскалярный процессор с OoO.
Тема данной статьи — вызов функций.
Суперскалярный стековый процессор: скрещиваем ужа и ежа
11 мин
В данной статье мы будем разрабатывать (программную) модель суперскалярного процессора с OOO и фронтендом стековой машины.
Теория и практика парсинга исходников с помощью ANTLR и Roslyn
23 мин
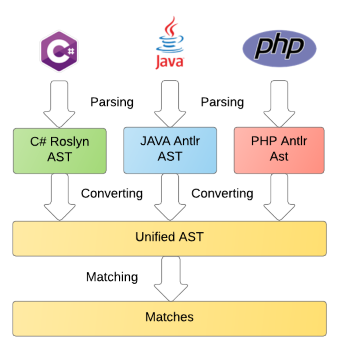
В нашем проекте PT Application Inspector реализовано несколько подходов к анализу исходного кода на различных языках программирования:
- поиск по сигнатурам;
- исследование свойств математических моделей, полученных в результате статической абстрактной интерпретации кода;
- динамический анализ развернутого приложения и верификация на нем результатов статического анализа.
Наш цикл статей посвящен структуре и принципам работы модуля сигнатурного поиска (PM, pattern matching). Преимущества такого анализатора — скорость работы, простота описания шаблонов и масштабируемость на другие языки. Среди недостатков можно выделить то, что модуль не в состоянии анализировать сложные уязвимости, требующие построения высокоуровневых моделей выполнения кода.
К разрабатываемому модулю были, в числе прочих, сформулированы следующие требования:
- поддержка нескольких языков программирования и простое добавление новых;
- поддержка анализа кода, содержащего синтаксические и семантические ошибки;
- возможность описания шаблонов на универсальном языке (DSL, domain specific language).
В нашем случае все шаблоны описывают какие-либо уязвимости или недостатки в исходном коде.
Весь процесс анализа кода может быть разбит на следующие этапы:
- парсинг в зависимое от языка представление (abstract syntax tree, AST);
- преобразование AST в независимый от языка унифицированный формат;
- непосредственное сопоставление с шаблонами, описанными на DSL.
Данная статья посвящена первому этапу, а именно: парсингу, сравнению функциональных возможностей и особенностей различных парсеров, применению теории на практике на примере грамматик Java, PHP, PLSQL, TSQL и даже C#. Остальные этапы будут рассмотрены в следующих публикациях.
Грэйс «бабуля COBOL» Хоппер
4 мин
«Она истинный морпех, но если копнуть глубже, мы найдем пирата.»
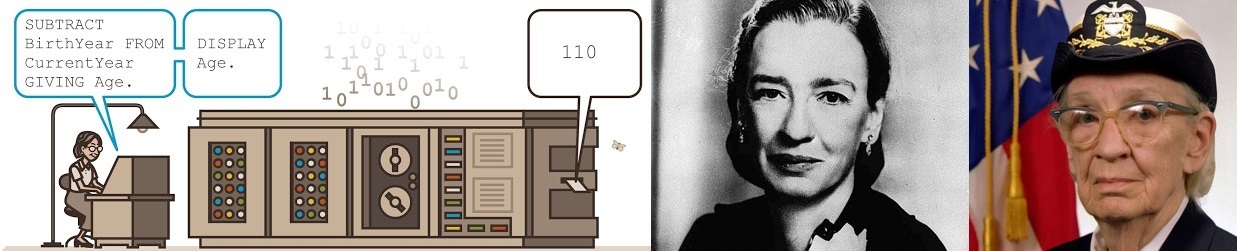
Грейс Хоппер (Grace Hopper) — американская учёная и контр-адмирал флота США. Программист гарвардского компьютера Марк I.
Построив успешную карьеру математика в Йеле (защитив докторскую и став профессором), Грэйс Хоппер в 1943 (37 лет) пошла добровольцем во Флот.
Но у нее был недобор по весу 6 кг, поэтому пришлось сесть «за клавиатуру» Гарвардского Mark 1.

Грейс Хоппер (Grace Hopper) — американская учёная и контр-адмирал флота США. Программист гарвардского компьютера Марк I.
- В детстве разобрала 7 будильников, чтобы понять, как все устроено.
- Боролась за идею машинонезависимого языка программирования.
- Разработала первый компилятор.
- Приложила руку к распространению мема «дебаггинг» (выловив настоящего жука из Mark 2).
- Могла объяснить сообразительным военным, что такое «наносекунда» и «пикосекунда». На пальцах.
- В её честь назвали эсминец USS Hopper (DDG-70).
- И суперкомпьютер Cray XE6 «Hopper».
- И в ее честь именная премия Ассоциации вычислительной техники (ACM) — присуждается молодому (до 35 лет) специалисту, сделавшему значительный вклад в области вычислительной техники.
Построив успешную карьеру математика в Йеле (защитив докторскую и став профессором), Грэйс Хоппер в 1943 (37 лет) пошла добровольцем во Флот.
Но у нее был недобор по весу 6 кг, поэтому пришлось сесть «за клавиатуру» Гарвардского Mark 1.
Стек стеком погоняет, или преобразование байткода виртуальной машины Java в байткод машины Фантом ОС
5 мин
ОС Фантом — экспериментальная операционная система, содержащая на прикладном уровне виртуальную байткод-машину в персистентной оперативной памяти.
Один из двух ключевых запланированных для ОС Фантом путей миграции существующего кода — преобразование байткода Java в байткод Фантом.
Надо сказать, что эти виртуальные машины изрядно, хотя и совершенно случайно, похожи. Виртуальная машина Фантома была спроектирована тогда, когда про Явскую я ещё ничего не знал, но, наверное, сходство целей привело к сходству принятых решений.
Обе машины — стековые. Обе оперируют двумя отдельными стеками — стеком для работы с объектами (на стеке лежат только ссылки), и бинарным стеком — для вычислений. Машина Фантома имеет также отдельные стеки для фреймов функций и ловушек исключений. Как эта часть устроена в JVM, я не знаю до сих пор, но полагаю, что вряд ли кардинально отличным образом.
Естественно, что и набор операций стековых машин местами схож как две капли.
Но, безусловно, есть и весьма существенные отличия.
Один из двух ключевых запланированных для ОС Фантом путей миграции существующего кода — преобразование байткода Java в байткод Фантом.
Надо сказать, что эти виртуальные машины изрядно, хотя и совершенно случайно, похожи. Виртуальная машина Фантома была спроектирована тогда, когда про Явскую я ещё ничего не знал, но, наверное, сходство целей привело к сходству принятых решений.
Обе машины — стековые. Обе оперируют двумя отдельными стеками — стеком для работы с объектами (на стеке лежат только ссылки), и бинарным стеком — для вычислений. Машина Фантома имеет также отдельные стеки для фреймов функций и ловушек исключений. Как эта часть устроена в JVM, я не знаю до сих пор, но полагаю, что вряд ли кардинально отличным образом.
Естественно, что и набор операций стековых машин местами схож как две капли.
Но, безусловно, есть и весьма существенные отличия.
LLVM: компилятор своими руками. Введение
14 мин
Представим себе, что в один прекрасный день вам пришла в голову идея процессора собственной, ни на что не похожей архитектуры, и вам очень захотелось эту идею реализовать «в железе». К счастью, в этом нет ничего невозможного. Немного верилога, и вот ваша идея реализована. Вам уже снятся прекрасные сны про то, как Intel разорилась, Microsoft спешно переписывает Windows под вашу архитектуру, а Linux-сообщество уже написало под ваш микропроцессор свежую версию системы с весьма нескучными обоями.
Однако, для всего этого не хватает одной мелочи: компилятора!
Да, я знаю, что многие не считают наличие компилятора чем-то важным, считая, что все должны программировать строго на ассемблере. Если вы тоже так считаете, я не буду с вами спорить, просто не читайте дальше.
Если вы хотите, чтобы для вашей оригинальной архитектуры был доступен хотя бы язык С, прошу под кат.
В статье будет рассматриваться применение инфраструктуры компиляторов LLVM для построения собственных решений на её основе.
Область применения LLVM не ограничивается разработкой компиляторов для новых процессоров, инфраструктура компиляторов LLVM также может применяться для разработки компиляторов новых языков программирования, новых алгоритмов оптимизации и специфических инструментов статического анализа программного кода (поиск ошибок, сбор статистики и т.п.).
Например, вы можете использовать какой-то стандартный процессор (например, ARM) в сочетании с специализированным сопроцессором (например, матричный FPU), в этом случае вам может понадобиться модифицировать существующий компилятор для ARM так, чтобы он мог генерировать код для вашего FPU.
Также интересным применением LLVM может быть генерация исходных текстов на языке высокого уровня («перевод» с одного языка на другой). Например, можно написать генератор кода на Verilog по исходному коду на С.

КДПВ
Однако, для всего этого не хватает одной мелочи: компилятора!
Да, я знаю, что многие не считают наличие компилятора чем-то важным, считая, что все должны программировать строго на ассемблере. Если вы тоже так считаете, я не буду с вами спорить, просто не читайте дальше.
Если вы хотите, чтобы для вашей оригинальной архитектуры был доступен хотя бы язык С, прошу под кат.
В статье будет рассматриваться применение инфраструктуры компиляторов LLVM для построения собственных решений на её основе.
Область применения LLVM не ограничивается разработкой компиляторов для новых процессоров, инфраструктура компиляторов LLVM также может применяться для разработки компиляторов новых языков программирования, новых алгоритмов оптимизации и специфических инструментов статического анализа программного кода (поиск ошибок, сбор статистики и т.п.).
Например, вы можете использовать какой-то стандартный процессор (например, ARM) в сочетании с специализированным сопроцессором (например, матричный FPU), в этом случае вам может понадобиться модифицировать существующий компилятор для ARM так, чтобы он мог генерировать код для вашего FPU.
Также интересным применением LLVM может быть генерация исходных текстов на языке высокого уровня («перевод» с одного языка на другой). Например, можно написать генератор кода на Verilog по исходному коду на С.
КДПВ